Xây Dựng Trợ Lý AI Riêng (Local RAG) - Không Cần API, Không Lộ Dữ Liệu
🚀 Xây Dựng Trợ Lý AI Riêng (Local RAG) - Không Cần API, Không Lộ Dữ Liệu
Một hướng dẫn thực tế để tạo “ChatGPT riêng” đọc tài liệu của bạn — chạy 100% trên máy cá nhân.
🧠 Vấn đề
Bạn có rất nhiều dữ liệu:
- 📄 Notes cá nhân
- 📁 Tài liệu công việc
- 💬 Email, Slack, meeting notes
- 📚 Docs từ nhiều năm trước
Nhưng khi cần:
- “Client này từng yêu cầu gì?”
- “Policy nghỉ phép nằm ở đâu?”
- “Case này giống case nào trước đó?”
👉 Bạn phải:
- Mở từng file
- Ctrl + F
- Đọc lại
⏱️ Mất 10–30 phút cho mỗi câu hỏi.
💡 Giải pháp: RAG (Retrieval-Augmented Generation)
RAG là gì?
👉 AI đọc toàn bộ tài liệu của bạn
👉 Khi bạn hỏi → nó tìm thông tin liên quan
👉 Sau đó trả lời dựa trên dữ liệu thực tế
✔️ Không bịa
✔️ Không đoán
✔️ Có context thật
⚙️ Kiến trúc hệ thống
3 thành phần chính:
| Thành phần | Vai trò |
|---|---|
| Ollama | Chạy AI model (LLM) local |
| Qdrant | Lưu vector & tìm kiếm |
| n8n | Orchestration (workflow) |
🔍 Cách hệ thống hoạt động
📥 1. Ingestion (Đưa dữ liệu vào)
- Cắt tài liệu thành đoạn nhỏ (chunking)
- Convert text → vector (embedding)
- Lưu vào Qdrant
🎤 2. Query (Đặt câu hỏi)
- Câu hỏi → vector
- Tìm các đoạn liên quan nhất
- Gửi context vào LLM
- LLM trả lời
⚠️ Lưu ý quan trọng
RAG KHÔNG chỉ có 1 model
Bạn cần:
| Loại | Vai trò |
|---|---|
| Embedding model | Tìm kiếm |
| LLM | Trả lời |
👉 Ví dụ:
- Embedding:
nomic-embed-text - LLM:
mistral,llama2
🔐 Tại sao nên chạy local?
- 🔒 Dữ liệu không rời khỏi máy
- 💰 Không tốn API cost
- 🌐 Không cần internet
- ⚡ Chủ động hoàn toàn
👉 Phù hợp với:
- Công ty (internal data)
- Legal / tài chính
- Cá nhân (knowledge base riêng)
⚡ Performance thực tế
| Cấu hình | Thời gian |
|---|---|
| CPU | ~2–8 giây |
| GPU | Nhanh hơn đáng kể |
👉 Phụ thuộc:
- Model
- Độ dài context
- Số lượng documents
💼 Use Cases thực tế
👨💼 Product Manager
“Client A từng complain gì?”
→ AI đọc meeting notes + chat logs
👩💼 HR
“Quy định nghỉ phép?”
→ AI trả lời từ policy nội bộ
⚖️ Legal
“Clause này giống hợp đồng nào?”
→ AI tìm contract tương tự
👨💻 Developer
“Bug này từng fix chưa?”
→ AI đọc docs + issues
🔥 Trước vs Sau
❌ Không có RAG
- Tìm file → đọc → 15 phút
✅ Có RAG
- Hỏi → trả lời trong vài giây
👉 Thay đổi hoàn toàn workflow
🛠️ Cài đặt với Docker Compose
📦 docker-compose.yml
services:
n8n:
image: docker.n8n.io/n8nio/n8n
container_name: rag-n8n
restart: always
ports:
- "127.0.0.1:5678:5678"
environment:
- N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
- N8N_HOST=${N8N_HOST}
- N8N_PORT=${N8N_PORT}
- N8N_PROTOCOL=${N8N_PROTOCOL}
- NODE_ENV=${N8N_HOST}
- GENERIC_TIMEZONE=${GENERIC_TIMEZONE}
- TZ=${GENERIC_TIMEZONE}
- N8N_RESTRICT_FILE_ACCESS_TO=/files
volumes:
- n8n_data:/home/node/.n8n
- ./local-files:/files
networks:
- app-net
ollama:
image: ollama/ollama
container_name: rag-ollama
ports:
- "11434:11434"
restart: "no"
volumes:
- ./ollama/data:/root/.ollama
networks:
- app-net
qdrant:
image: qdrant/qdrant:latest
container_name: rag-qdrant
ports:
- "6333:6333"
restart: "no"
volumes:
- ./qdrant/data:/qdrant/storage
networks:
- app-net
volumes:
n8n_data:
networks:
app-net:
driver: bridge
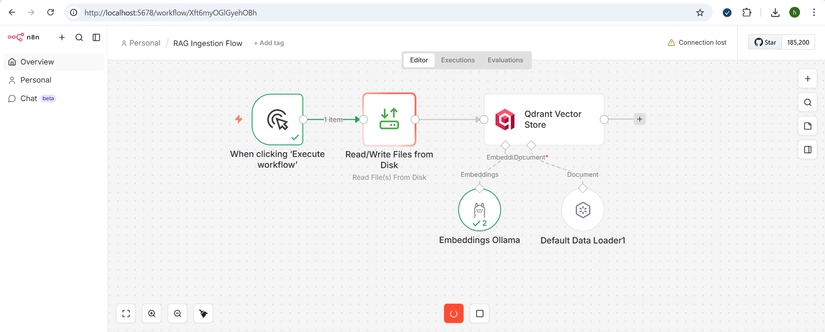
📥 Workflow RAG - Khởi tạo dữ liệu
Quá trình: Đưa tài liệu vào → Cắt nhỏ → Lưu vào Qdrant
1️⃣ Bước 1: Đưa tài liệu vào
Cách làm:
- N8N hỗ trợ kết nối với Google Drive, Outlook, v.v...
- Lần này dùng Read/Write Files from Disk để load file từ local.
2️⃣ Bước 2: Cắt nhỏ tài liệu (Chunking)
Mục đích:
- Chia tài liệu thành các đoạn nhỏ để dễ tìm kiếm
Cấu hình:
- Kích thước chunk: 1000 ký tự
- Overlapping: 200 ký tự (để giữ ngữ cảnh)
- Sử dụng embedding model:
nomic-embed-text(nhẹ, nhanh)
3️⃣ Bước 3: Lưu vào Qdrant
- Các đoạn text được convert thành vector
- Lưu vào Qdrant để tìm kiếm nhanh
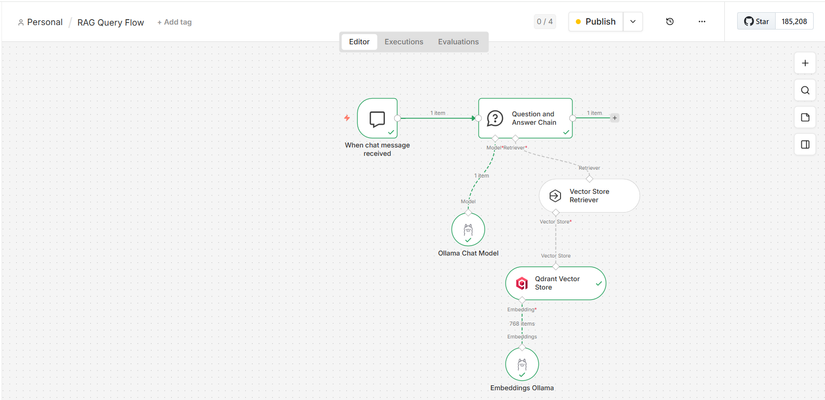
🎤 Workflow RAG - Truy vấn dữ liệu
Quá trình: Hỏi câu hỏi → Tìm kiếm tài liệu liên quan → LLM trả lời
1️⃣ Bước 1: Người dùng đặt câu hỏi (Query)
- Sử dụng node nhận input từ người dùng
2️⃣ Bước 2: Tìm kiếm tài liệu liên quan (Retrieve)
Sử dụng: Qdrant Vector Store Retriever node
- Chuyển câu hỏi thành vector
- So sánh với vectors của tài liệu đã lưu
- Lấy những đoạn liên quan nhất
3️⃣ Bước 3: Đưa thông tin vào LLM (Augment)
Sử dụng: Q&A node
- Cấu hình embedding model (tìm kiếm):
nomic-embed-text - Cấu hình chat model (trả lời):
mistralhoặcllama2 - Lưu ý: Embedding model ≠ Chat model (phải chọn loại phù hợp)
4️⃣ Bước 4: LLM sinh câu trả lời (Generate)
- LLM đọc context từ tài liệu
- Trả lời dựa trên dữ liệu thực tế (không bịa)
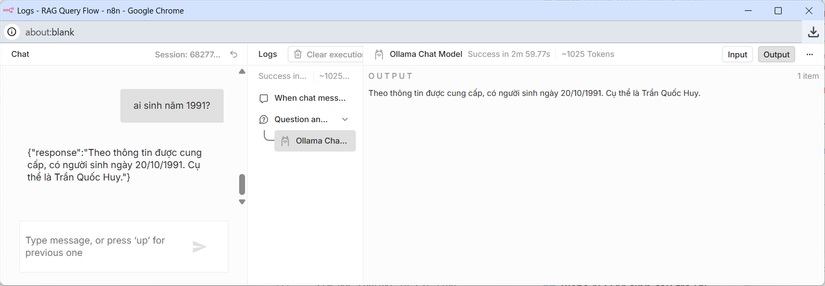
✅ Kết quả
- Đầu vào: Câu hỏi từ người dùng
- Đầu ra: Câu trả lời có context từ tài liệu cá nhân
- Tốc độ: Vài giây (nếu có GPU) hoặc 10-15 giây (nếu CPU)
All rights reserved
