Xây dựng pipeline trích xuất và làm sạch dữ liệu văn bản phi cấu trúc cho hệ thống
Trong các hệ thống doanh nghiệp hiện đại, phần lớn dữ liệu không nằm trong database quan hệ mà tồn tại dưới dạng tài liệu: PDF hợp đồng, file Word báo cáo, hay nội dung HTML từ website. Đây đều là dữ liệu phi cấu trúc, không thể đưa trực tiếp vào phân tích, tìm kiếm hay AI nếu chưa qua xử lý.
Bài viết này trình bày một cách tiếp cận có hệ thống dành cho Developer: từ nhận diện dữ liệu phi cấu trúc, trích xuất nội dung từ nhiều định dạng khác nhau, đến xây dựng pipeline làm sạch và chuẩn hóa văn bản để sẵn sàng cho ETL, NLP hoặc AI application.
Dữ liệu phi cấu trúc dưới góc nhìn kỹ thuật
Khác với structured data (bảng, cột, schema cố định), dữ liệu phi cấu trúc không tuân theo một định dạng nhất quán. Developer thường gặp ba nhóm phổ biến:
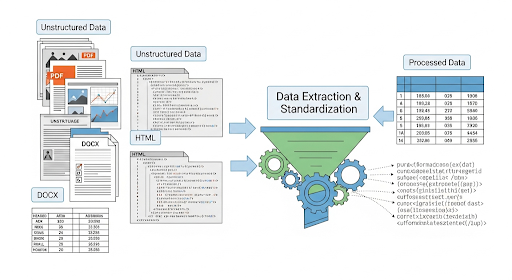
Thường là hợp đồng, báo cáo tài chính, tài liệu nghiên cứu. Một file PDF có thể chứa text, bảng, hình ảnh, vector hoặc thậm chí là ảnh scan, khiến việc trích xuất không đồng nhất.
DOCX
File Word có cấu trúc bán phần: heading, paragraph, table, image, footnote. Việc đọc dữ liệu yêu cầu thư viện hiểu được cấu trúc nội bộ của document.
HTML
Nguồn dữ liệu từ web chứa nhiều thành phần không phục vụ phân tích: menu, footer, script, style, quảng cáo. Text “có giá trị” chỉ chiếm một phần nhỏ trong toàn bộ DOM.
Điểm chung của các nguồn này là: không thể phân tích ngay. Trước khi dùng cho báo cáo, search engine hay AI, dữ liệu cần được trích xuất, loại bỏ nhiễu và chuẩn hóa.
Vì sao Developer cần xử lý dữ liệu phi cấu trúc bài bản?
Việc xử lý dữ liệu phi cấu trúc không chỉ phục vụ phân tích, mà còn là nền tảng cho nhiều hệ thống phía sau:
- Chuẩn bị dữ liệu đầu vào cho NLP / LLM / embedding
- Tự động hóa quy trình đọc tài liệu thay cho thao tác thủ công
- Trích xuất insight từ hợp đồng, báo cáo, phản hồi khách hàng
- Nâng chất lượng dữ liệu trước khi đưa vào data warehouse hoặc search engine
Một pipeline tốt giúp hệ thống ổn định, dễ mở rộng và giảm đáng kể chi phí vận hành về lâu dài.
Trích xuất nội dung từ các định dạng phổ biến
Đọc dữ liệu từ PDF
Với PDF dạng text, các thư viện Python thường dùng là PyPDF2 hoặc pdfplumber.
import pdfplumber
with pdfplumber.open("sample.pdf") as pdf:
content = ""
for page in pdf.pages:
content += page.extract_text()
Trong trường hợp PDF là ảnh scan, cần OCR:
tesseract input.pdf output.txt -l vie
Lưu ý kỹ thuật:
- PDF có thể bị mã hóa hoặc giới hạn quyền đọc
- Text có thể bị vỡ dòng, sai thứ tự do layout phức tạp
- OCR cần xử lý thêm bước làm sạch sau trích xuất
Trích xuất nội dung từ DOCX
python-docxcho phép đọc paragraph, heading và table một cách có cấu trúc.
from docx import Document
doc = Document("sample.docx")
text = "\n".join(p.text for p in doc.paragraphs)
Ứng dụng thường gặp:
- Đọc báo cáo nội bộ
- Trích dữ liệu bảng cho phân tích
- Chuẩn bị input cho NLP hoặc search index
Thu thập text từ HTML
Với dữ liệu web, cần loại bỏ toàn bộ phần markup không cần thiết.
Python – BeautifulSoup
from bs4 import BeautifulSoup
import requests
html = requests.get("https://example.com").text
soup = BeautifulSoup(html, "html.parser")
text = " ".join(p.get_text() for p in soup.find_all("p"))
Node.js – Cheerio
const cheerio = require("cheerio");
const axios = require("axios");
const { data } = await axios.get("https://example.com");
const $ = cheerio.load(data);
const text = $("p").map((i, el) => $(el).text()).get().join(" ");
Ở bước này, mục tiêu không phải crawl toàn bộ HTML, mà là tách phần nội dung chính phục vụ phân tích.
Thiết kế pipeline làm sạch dữ liệu văn bản
Sau khi trích xuất, dữ liệu thô thường chứa nhiều nhiễu. Một pipeline xử lý cơ bản cho Developer có thể gồm các bước sau.
1. Loại bỏ ký tự rác
Text thường chứa ký tự lạ, xuống dòng không cần thiết hoặc dấu không mong muốn. Regex giúp lọc nhanh:
import re
clean_text = re.sub(r"[^a-zA-Z0-9À-ỹ\s.,]", "", raw_text)
2. Chuẩn hóa định dạng văn bản
- Chuyển về chữ thường
- Đảm bảo encoding UTF-8
- Đồng nhất cách viết để tránh sai lệch khi phân tích
3. Tiền xử lý NLP
Bước này đặc biệt quan trọng nếu dữ liệu dùng cho AI hoặc phân tích ngôn ngữ:
- Tokenization
- Loại bỏ stopwords
- Lemmatization / stemming để gom các biến thể từ
Ví dụ: “chạy nhanh”, “chạy bộ” → “chạy”
4. Loại bỏ HTML và metadata dư thừa
Với dữ liệu web, cần đảm bảo chỉ giữ lại text thuần:
from bs4 import BeautifulSoup
text_only = BeautifulSoup(html, "lxml").get_text()
5. Lưu trữ dữ liệu đã chuẩn hóa
Tùy mục đích sử dụng, dữ liệu sạch có thể được:
- Xuất ra CSV / JSON
- Index vào Elasticsearch cho full-text search
- Đưa vào data warehouse hoặc vector database
Các kịch bản ứng dụng thường gặp
Trong thực tế triển khai, pipeline xử lý dữ liệu phi cấu trúc thường xuất hiện trong các dịch vụ Chatbot AI:
- Chuẩn hóa văn bản trước khi embedding cho LLM
- ETL pipeline: crawl HTML → clean → load BigQuery / Snowflake
- Search nội bộ từ hợp đồng PDF, DOCX
- Script tự động đọc báo cáo định kỳ và đẩy dữ liệu vào dashboard
Tổng kết
Với Developer, xử lý dữ liệu phi cấu trúc không đơn thuần là “đọc file”. Đó là một pipeline hoàn chỉnh: Extract → Clean → Normalize → Store. Khi được thiết kế đúng, pipeline này giúp tiết kiệm thời gian, giảm lỗi thủ công và tạo nền tảng vững chắc cho các hệ thống phân tích, tìm kiếm và AI.
Nếu đang xây dựng data pipeline, search engine nội bộ hoặc trợ lý AI, đây là lớp hạ tầng dữ liệu không thể bỏ qua.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-xu-ly-du-lieu-phi-cau-truc-trich-xuat-va-lam-sach-van-ban.html
All rights reserved
