What is GPT-5.2? An insight of 5 major updates in GPT-5.2!
GPT-5.2 is OpenAI’s December 2025 point release in the GPT-5 family: a flagship multimodal model family (text + vision + tools) tuned for professional knowledge work, long-context reasoning, agentic tool use, and software engineering. OpenAI positions GPT-5.2 as the most capable GPT-5 series model to date and says it was developed with an emphasis on reliable multi-step reasoning, handling very large documents, and improved safety/ policy compliance; the release includes three user-facing variants — Instant, Thinking, and Pro — and is rolling out first to paid ChatGPT subscribers and API customers.
What is GPT-5.2 and why does it matter?
GPT-5.2 is the latest member of OpenAI’s GPT-5 family — a new “frontier” model series designed specifically to close the gap between single-turn conversational assistants and systems that must reason across long documents, call tools, interpret images, and execute multi-step workflows reliably. OpenAI positions 5.2 as their most capable release yet for professional knowledge work: it sets new state-of-the-art results on internal benchmarks (notably a new GDPval benchmark for knowledge work), demonstrates stronger coding performance on software-engineering benchmarks, and offers significantly improved long-context and vision capabilities.
In practical terms, GPT-5.2 is more than just “a bigger chat model.” It’s a family of three tuned variants (Instant, Thinking, Pro) that trade off latency, depth of reasoning, and cost — and which, together with OpenAI’s API and ChatGPT routing, can be used to run long research jobs, build agents that call external tools, interpret complex images and charts, and generate production-grade code at higher fidelity than earlier releases. The model supports very large context windows (OpenAI documents list a 400,000-token context window and a 128,000 max-output limit for the flagship models), new API features for explicit reasoning effort levels, and “agentic” tool invocation behavior.
5 core capabilities upgraded in GPT-5.2
1) is GPT-5.2 better at multi-step logic and math?
GPT-5.2 brings sharper multi-step reasoning and noticeably stronger performance on mathematics and structured problem solving. OpenAI says they added more granular control over reasoning effort (new levels such as xhigh), engineered “reasoning token” support, and tuned the model to maintain chain-of-thought over longer internal reasoning traces. Benchmarks like FrontierMath and ARC-AGI-style tests show substantive gains versus GPT-5.1; It larger margins on domain-specific benchmarks used in scientific and financial workflows. In short: GPT-5.2 “thinks longer” when asked, and can do more complicated symbolic/mathematical work with better consistency.

| RC-AGI-1 (Verified) Abstract reasoning | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) Abstract reasoning | 52.9% | 17.6% |
GPT-5.2 Thinking sets records in multiple advanced science and math reasoning tests:
- GPQA Diamond Science Quiz: 92.4% (Pro version 93.2%)
- ARC-AGI-1 Abstract Reasoning: 86.2% (first model to break the 90% threshold)
- ARC-AGI-2 Higher Order Reasoning: 52.9%, setting a new record for the Thinking Chain model
- FrontierMath Advanced Mathematics Test: 40.3%, far surpassing its predecessor;
- HMMT Math Competition Problems: 99.4%
- AIME Math Test: 100% Complete Solution
Furthermore, GPT-5.2 Pro (High) is state-of-the-art on ARC-AGI-2, achieving a score of 54.2% at a cost of $15.72 per task! Outperforming all other models.
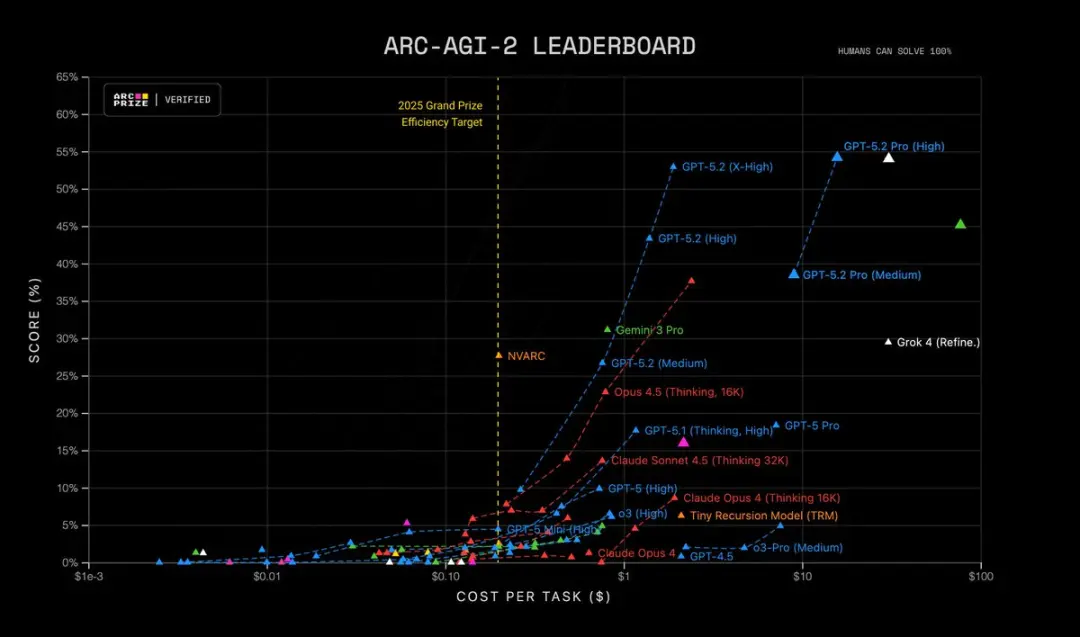
Why this matters: many real-world tasks — financial modelling, experiment design, program synthesis that requires formal reasoning — are bottlenecked by a model’s ability to chain many correct steps. GPT-5.2 reduces “hallucinated steps” and produces more stable intermediate reasoning traces when you ask it to show its working.
2) How has long text comprehension and cross-document reasoning improved?
Long-context understanding is one of the marquee improvements. GPT-5.2’s underlying model supports a 400k-token context window and — importantly — maintains higher accuracy as relevant content shifts deep into that context. GDPval, a task suite for “well-specified knowledge work” across 44 occupations, where GPT-5.2 Thinking reaches parity or better than expert human judges on a large share of tasks. Independent reporting confirms the model holds and synthesizes information across many documents far better than prior models. This is a genuinely practical step forward for tasks like due diligence, legal summarization, literature reviews, and codebase comprehension.
GPT-5.2 can handle contexts up to 256,000 tokens (approximately 200+ pages of documents). Furthermore, in the "OpenAI MRCRv2" long-text comprehension test, GPT-5.2 Thinking achieved an accuracy rate close to 100%.
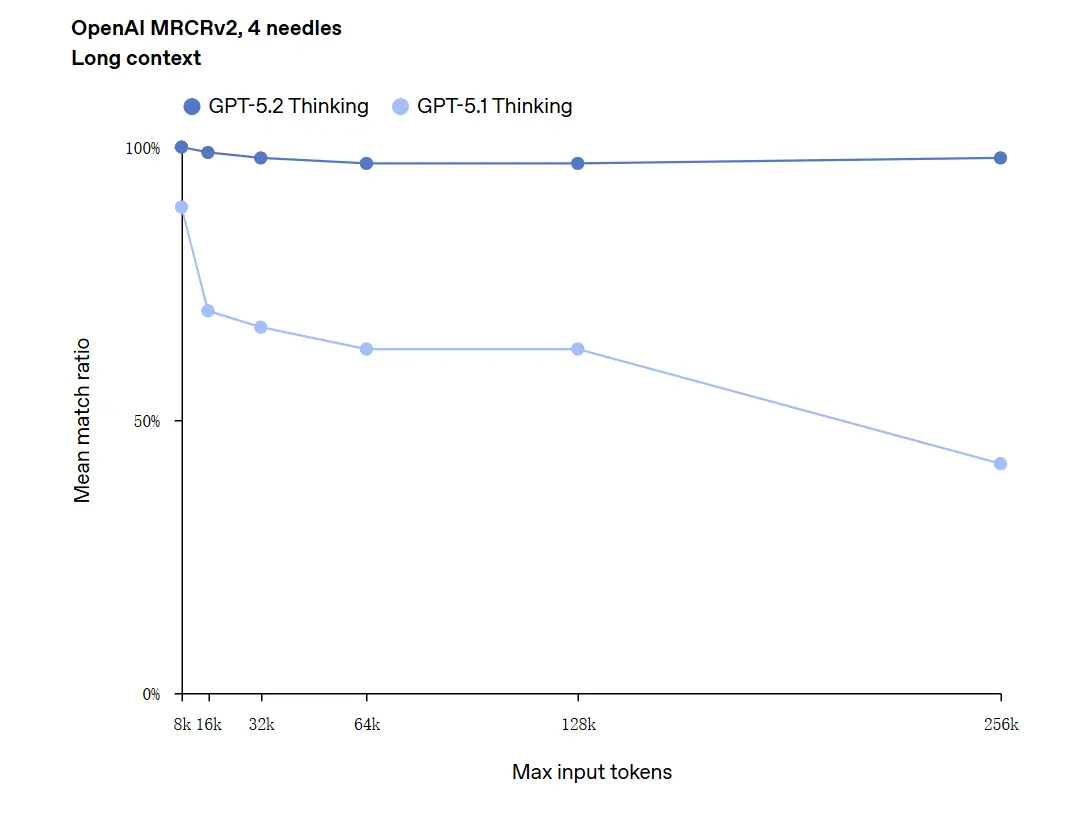
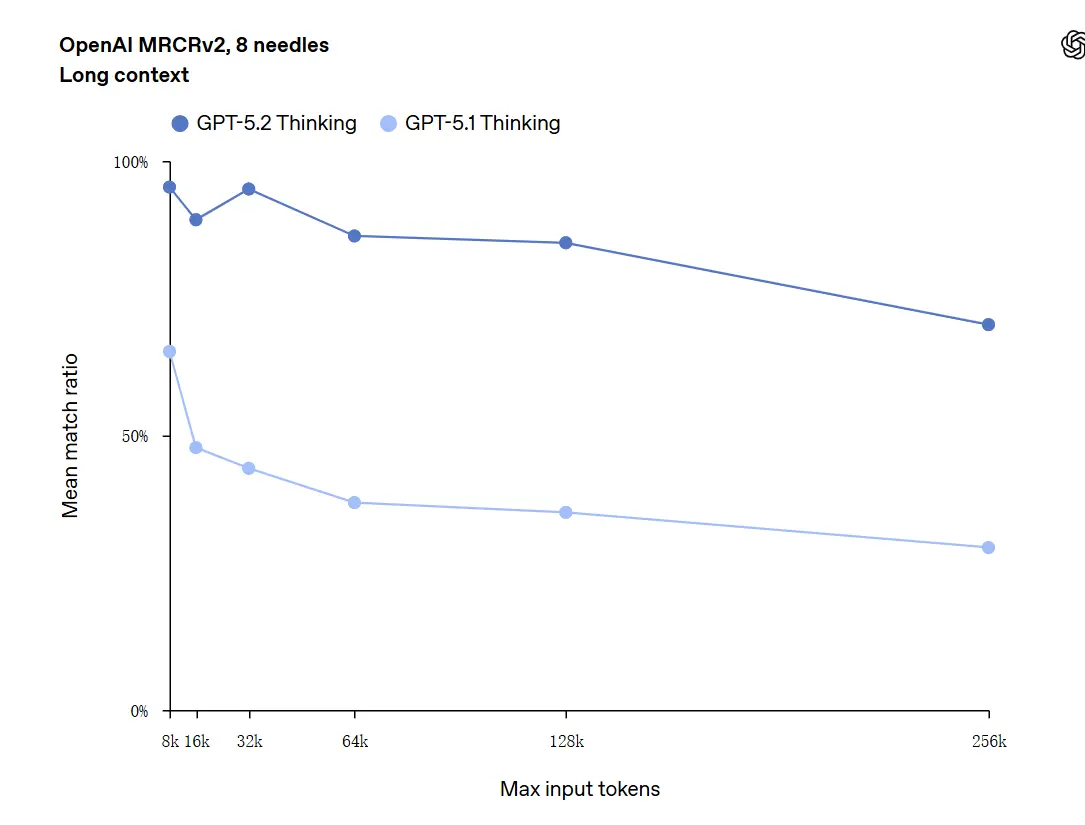
Caveat on “100% accuracy”: It described the improvements as “approaching 100%” for narrow micro-tasks; OpenAI’s data are better described as “state-of-the-art and in many cases at or above human expert levels on evaluated tasks,” not literally flawless across all uses. Benchmarks show large gains but not universal perfection.
3) What’s new in visual understanding and multimodal reasoning?
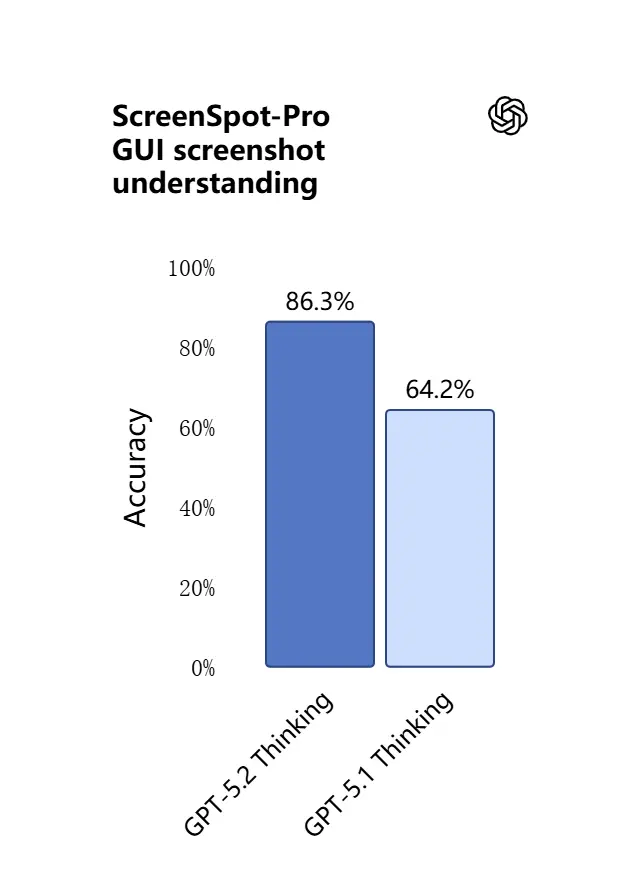
Vision capabilities in GPT-5.2 are sharper and more practical. The model is better at interpreting screenshots, reading charts and tables, recognizing UI elements, and combining visual inputs with long textual context. This isn’t just captioning: GPT-5.2 can extract structured data from images (e.g., tables in a PDF), explain graphs, and reason about diagrams in ways that support downstream tool actions (e.g., generating a spreadsheet from a photographed report).
.webp)
Practical effect: teams can feed full slide decks, scanned research reports, or image-heavy documents directly into the model and ask for cross-document syntheses — greatly reducing manual extraction work.
4) How has tool invocation and task execution changed?
GPT-5.2 pushes further into agentic behavior: it is better at planning multi-step tasks, deciding when to call external tools, and executing sequences of API/tool calls to finish a job end-to-end. “agentic tool-calling” improvements — the model will propose a plan, call tools (databases, compute, file systems, browser, code runners), and synthesize results into a final deliverable more reliably than earlier models. The API introduces routing and safety controls (allowed tools lists, tool scaffolding) and the ChatGPT UI can auto-route requests to the appropriate 5.2 variant (Instant vs Thinking).
GPT-5.2 scored 98.7% in the Tau2-Bench Telecom benchmark, demonstrating its mature tool-calling capabilities in complex multi-turn tasks.
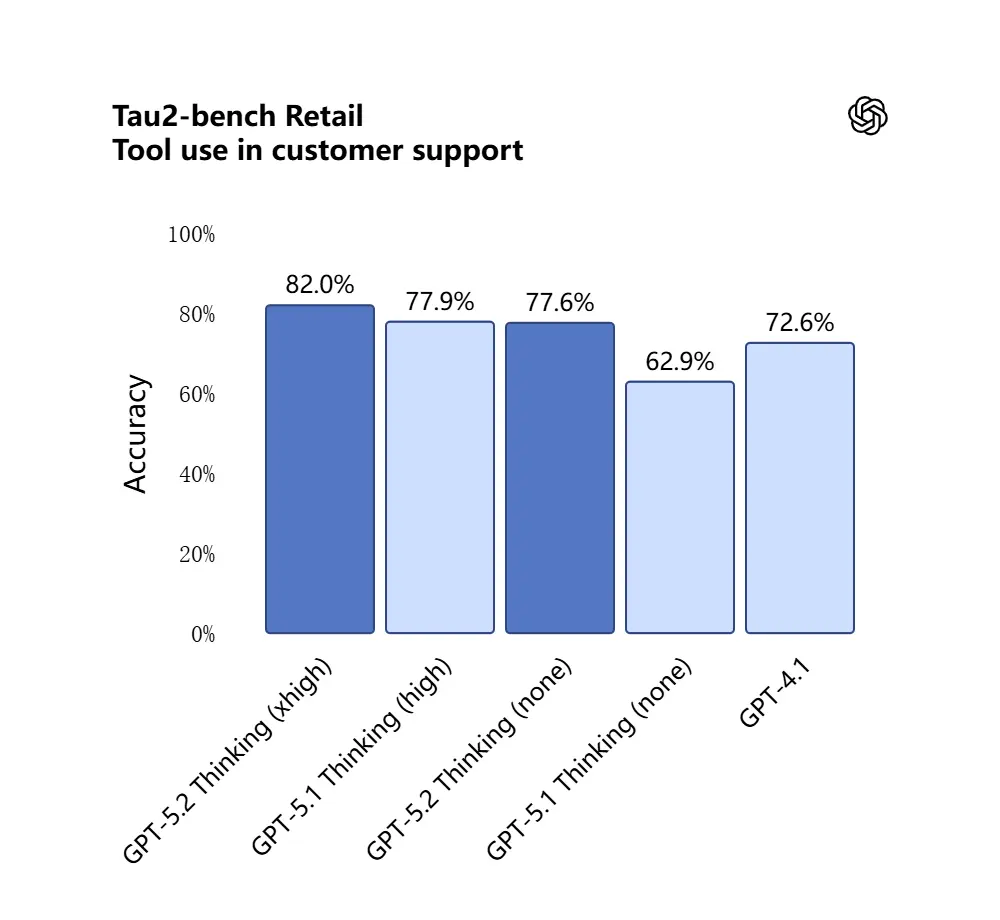
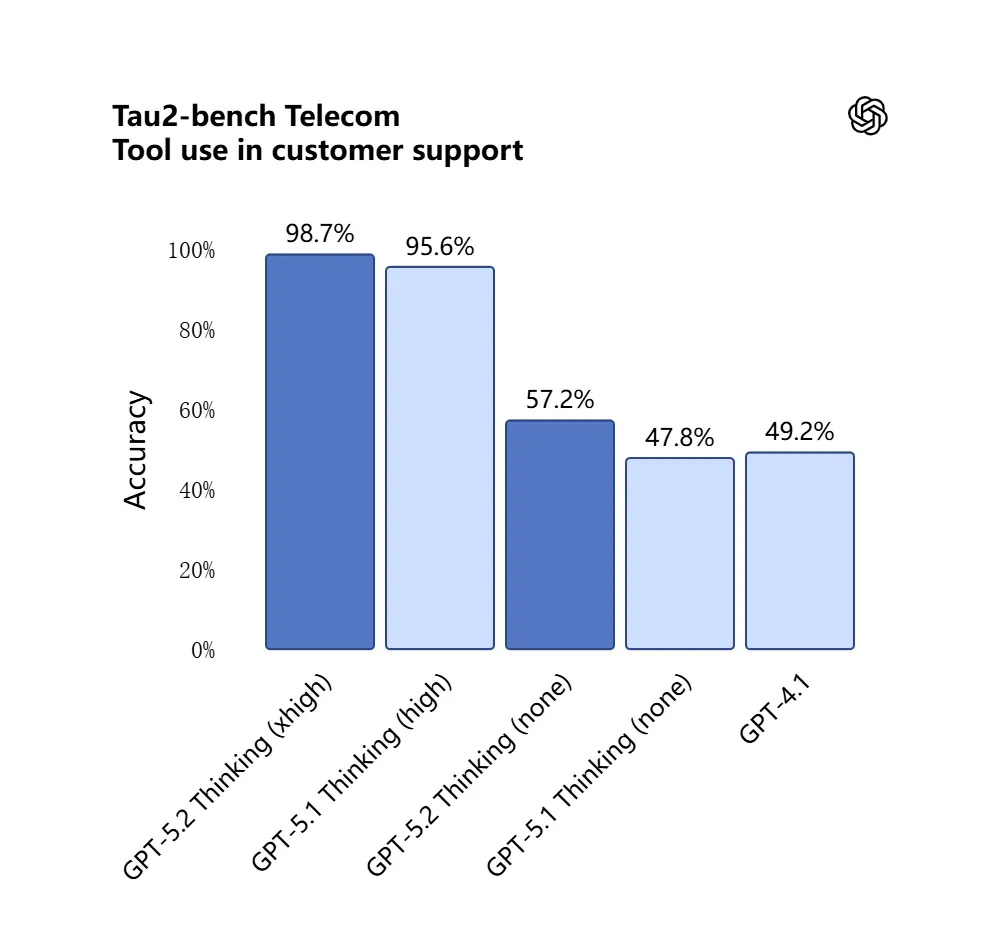
Why it matters: this makes GPT-5.2 more useful as an autonomous assistant for workflows like “ingest these contracts, extract clauses, update a spreadsheet, and write a summary email” — tasks that previously needed careful orchestration.
5) Programming capability evolved
GPT-5.2 is markedly better at software engineering tasks: it writes more complete modules, generates and runs tests more reliably, understands complex project dependency graphs, and is less prone to “lazy coding” (skipping boilerplate or failing to wire modules together). On industry-grade coding benchmarks (SWE-bench Pro, etc.) GPT-5.2 sets new records. For teams that use LLMs as pair-programmers, that improvement can reduce the manual verification and rework required after generation.
In the SWE-Bench Pro test (real-world industrial software engineering task), GPT-5.2 Thinking's score improved to 55.6%, while it also achieved a new high of 80% in the SWE-Bench Verified test.
_Software%20engineering.webp)
In practical applications, this means:
- Automatic debugging of production environment code leads to greater stability;
- Support for multi-language programming (not limited to Python);
- Ability to independently complete end-to-end repair tasks.
What are the differences between GPT-5.2 and GPT-5.1?
Short answer: GPT-5.2 is an iterative but material improvement. It keeps the GPT-5 family architecture and multimodal foundations, but advances four practical dimensions:
- Depth and consistency of reasoning. 5.2 introduces higher reasoning effort levels and better chaining for multi-step problems; 5.1 improved reasoning earlier, but 5.2 raises the ceiling for complex math and multi-stage logic.
- Long-context reliability. Both versions extended context, but 5.2 is tuned to maintain accuracy deep into very long inputs (OpenAI claims improved retention out to hundreds of thousands of tokens).
- Vision + multimodal fidelity. 5.2 improves cross-referencing between images and text — e.g., reading a chart and integrating that data into a spreadsheet — showing higher task-level accuracy.
- Agentic tool behavior and API features. 5.2 exposes new reasoning effort parameters (
xhigh) and context compaction features in the API, and OpenAI has refined the routing logic in ChatGPT so the UI can pick the best variant automatically. - Fewer errors, greater stability: GPT-5.2 reduces its "illusion rate" (false response rate) by 38%. It answers research, writing, and analytical questions more reliably, reducing instances of "fabricated facts." In complex tasks, its structured output is clearer and its logic more stable. Meanwhile, the model's response safety is significantly improved in mental health-related tasks. It performs more robustly in sensitive scenarios such as mental health, self-harm, suicide, and emotional dependence.
In system evaluations, GPT-5.2 Instant scored 0.995 (out of 1.0) on the "Mental Health Support" task, significantly higher than GPT-5.1 (0.883).
Quantitatively, OpenAI’s published benchmarks show measurable gains on GDPval, math benchmarks (FrontierMath), and software engineering evaluations. GPT-5.2 outperforms GPT-5.1 in junior investment-banking spreadsheet tasks by several percentage points.
Is GPT-5.2 free — how much does it cost?
Can I use GPT-5.2 for free?
OpenAI rolled out GPT-5.2 starting with paid ChatGPT plans and API access. Historically OpenAI has kept the fastest / deepest models behind paid tiers while making lighter variants available more broadly later; with 5.2 the company said the rollout would begin on paid plans (Plus, Pro, Business, Enterprise) and that the API is available to developers. That means immediate free access is limited: the free tier may receive degraded or routed access (for example to lighter subvariants) later as OpenAI scales the rollout.
The good news is that CometAPI now integrates with GPT-5.2, and it's currently on Christmas sale. You can now use GPT-5.2 through CometAPI; the playground allows you to freely interact with GPT-5.2, and developers can use the GPT-5.2 API (CometAPI is priced at 20% of OpenAI's) to build workflows.
What does it cost via the API (developer / production use)?
API usage is billed per-token. OpenAI’s published platform pricing at launch shows (CometAPI is priced at 20% of OpenAI's) :
- GPT-5.2 (standard chat) —
1.75 per 1M input tokens\** and \**14 per 1M output tokens (cached-input discounts apply). - GPT-5.2 Pro (flagship) —
21 per 1M input tokens\** and \**168 per 1M output tokens (significantly more expensive because it’s intended for high-accuracy, compute-heavy workloads). - By comparison, GPT-5.1 was cheaper (e.g.,
1.25 in /10 out per 1M tokens).
Interpretation: API costs rose relative to prior generations; the price signals that 5.2’s premium reasoning and long-context performance are priced as a distinct product tier. For production systems, plan costs depend heavily on how many tokens you input/output and how often you reuse cached inputs (cached inputs get heavy discounts).
What that means in practice
- For casual use through ChatGPT’s UI, monthly subscription plans (Plus, Pro, Business, Enterprise) are the main path. Pricing for ChatGPT subscription tiers did not change with the 5.2 release (OpenAI keeps plan prices stable even if the model offerings change).
- For production & developer use, budget for token costs. If your app streams lots of long responses or processes long documents, output token pricing ($14 / 1M tokens for Thinking) will dominate costs unless you carefully cache inputs and reuse outputs.
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI launched GPT-5.2 with three purpose-tiered variants to match use cases: Instant, Thinking, and Pro:
- GPT-5.2 Instant: Fast, cost-efficient, tuned for everyday work — FAQs, how-tos, translations, quick drafting. Lower latency; good first drafts and simple workflows.
- GPT-5.2 Thinking: Deeper, higher-quality responses for sustained work — long-document summarization, multi-step planning, detailed code reviews. Balanced latency and quality; the default ‘workhorse’ for professional tasks.
- GPT-5.2 Pro: Highest quality and trustworthiness. Slower and costlier; best for difficult, high-stakes tasks (complex engineering, legal synthesis, high-value decisions) and where an ‘xhigh’ reasoning effort is required.
Comparison table
| Feature / Metric | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| Intended use | Everyday tasks, quick drafts | Deep analysis, long documents | Highest-quality, complex problems |
| Latency | Lowest | Moderate | Highest |
| Reasoning effort | Standard | High | xHigh available |
| Best for | FAQ, tutorials, translations, short prompts | Summaries, planning, spreadsheets, coding tasks | Complex engineering, legal synthesis, research |
| API name examples | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| Input token price (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| Output token price (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| Availability (ChatGPT) | Rolling out; paid plans then wider | Rolling out to paid plans | Pro users / Enterprise (paid) |
| Typical use case example | Drafting email, minor code snippets | Build multi-sheet financial model, long report Q&A | Audit codebase, generate production-grade system design |
Who is suitable to use GPT-5.2?
GPT-5.2 is designed with a broad set of target users in mind. Below are role-based recommendations:
Enterprises & product teams
If you build knowledge work products (research assistants, contract review, analytics pipelines, or developer tooling), GPT-5.2’s long-context and agentic capabilities can significantly reduce integration complexity. Enterprises that need robust document understanding, automated reporting, or intelligent copilots will find Thinking/Pro useful. Microsoft and other platform partners are already integrating 5.2 into productivity stacks (e.g., Microsoft 365 Copilot).
Developers and engineering teams
Teams that want to use LLMs as pair-programmers or to automate code generation/testing will benefit from the improved programming fidelity in 5.2. API access (with thinking or pro modes) enables deeper syntheses of big codebases thanks to the 400k token context window. Expect to pay more on the API when using Pro, but the reduction in manual debugging and review may justify that cost for complex systems.
Researchers and data-heavy analysts
If you regularly synthesize literature, parse long technical reports, or want model-assisted experiment design, GPT-5.2’s long-context and math improvements help accelerate workflows. For reproducible research, couple the model with careful prompt engineering and verification steps.
Small businesses and power users
ChatGPT Plus (and Pro for power users) will get routed access to 5.2 variants; this makes advanced automation and high-quality outputs reachable for smaller teams without building an API integration. For non-technical users who need better document summarization or slide building, GPT-5.2 delivers noticeable practical value.
Practical notes for developers and operators
API features to watch
reasoning.effortlevels (e.g.,medium,high,xhigh) let you tell the model how much compute to spend on internal reasoning; use this to trade latency for accuracy on a per-request basis.- Context compaction: the API includes tools to compress and compact history so genuinely relevant content is preserved for long chains. This is critical when you must keep the effective token usage manageable.
- Tool scaffolding & allowed-tools controls: production systems should explicitly whitelist what the model can invoke and log tool calls for auditing.
Cost-control tips
- Cache frequently used document embeddings and use cached inputs (which receive steep discounts) for repeated queries against the same corpus. OpenAI’s platform pricing includes significant discounts for cached inputs.
- Route exploratory/low-value queries to Instant and keep Thinking/Pro for batch jobs or final passes.
- Carefully estimate token usage (input + output) when projecting API costs because long outputs multiply the cost.
Bottom line — should you upgrade to GPT-5.2?
If your work depends on long-document reasoning, cross-document synthesis, multimodal interpretation (images + text), or building agents that call tools, GPT-5.2 is a clear upgrade: it raises practical accuracy and reduces manual integration work. If you are primarily running high-volume, low-latency chatbots or strictly budget-constrained applications, Instant (or earlier models) may still be a reasonable choice.
GPT-5.2 represents a deliberate shift from “better chat” to “better professional assistant”: more compute, more capability, and higher cost tiers — but also real productivity wins for teams that can make use of reliable long-context, improved math/reasoning, image understanding, and agentic tool execution.
All rights reserved
