Virtual node - Partitioner trong Cassandra
Bài đăng này đã không được cập nhật trong 4 năm
Chào mọi người hôm trước mình có viết bài chia sẻ về NodeJs cơ bản và xây dựng ứng dụng chat đơn giản với NodeJs và Express
Hôm nay để tiếp tục chuyên mục biết gì viết đó (hehe) mình sẽ chia sẻ kiến thức mình tìm hiểu được về hệ quản trị cơ sở dữ liệu Cassandra mà facebook đang sử dụng để lưu thông tin chúng ta đang hằng ngày được cập nhật lên đó.
Let's do it
Khái niệm Cassandra?
-
Cassandra là một quản trị hệ cơ sở dữ liệu phân tán mã nguồn mở được thiết kế để xử lý một khối lượng lớn dữ liệu giàn trải trên nhiều node mà vẫn đảm bảo tính sẵn sàng cao (Highly Availability), khả năng mở rộng hay thu giảm số node linh hoạt (Elastic Scalability)
-
Nó được phát triển bởi Facebook và vẫn còn tiếp tục phát triển và sử dụng cho mạng xã hội lớn nhất thới giới này. Năm 2008, Facebook chuyển nó cho cộng đồng mã nguồn mở và được Apache tiếp tục phát triển đến ngày hôm nay. Cassandra được coi là sự kết hợp của Amazon’s Dynamo và Google’s BigTable.
Đặc trưng chính của Cassandra
- Tính phân tán và không tập trung (Distributed and Decentralized)
- Tính mềm dẻo (Elastic Scalability)
- Tính sẵn sàng cao (High Availability)
- Tính chấp nhận lỗi (Fault Tolerance)
- Tính hướng cột (Column oriented Key-Value store)
- Hiệu năng cao (High Performance)
Đó là các đặc trưng tổng quan khái quát về Cassandra, mình sẽ không đi sâu vào từng vấn đề đó, các khái niệm đó ta đều có thể tìm hiểu có khá nhiều trên mạng.
Bây giờ ta sẽ đi vào phần chính của bài viết mà mình chia sẻ hôm nay đó là về kiến trúc của Cassandra
Virtual node
Vnode giúp đơn giản nhiều tác vụ trong Cassandra
- Không cần phải tính toán và gán token cho từng node.
- Không cần thiết phải tái cân bằng lại một cluster khi thêm hoặc xóa đi một vài node. Khi một node được thêm vào cluster nó được giả định quản lý một phần dữ liệu từ những node khác trong cluster. Nếu một node bị lỗi thì dữ liệu mà nó đang nắm giữ sẽ được trải đều ra các node còn lại trong cluster.
- Tái tạo lại một dead node sẽ nhanh hơn bởi vì nó tạo liên kết với mỗi một node khác trong cluster.
- Cải thiện hiệu năng sử dụng nhiều máy tính khác nhau trên một cluster. Ta có thể gán số lượng vnode cho máy nhỏ hơn hoặc lớn hơn.
Vậy dữ liệu được phân tán trên các cluster như thế nào? (Sử dụng vnode)
-
Virtual node cho phép mỗi node sở hữu nhiều partition range phân tán từ đầu tới cuối cluster. Vnode cũng sử dụng consistent hashing để phân tán dữ liệu, nhưng sử dụng consistent hashing không đòi hỏi tạo ra token và gán giá trị cho chúng
-
Virtual vs single token architecture
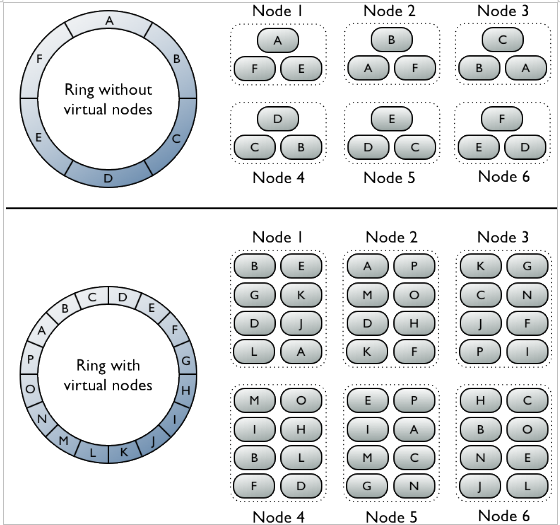
-
Ring không có virtual node: mỗi node được gán với một single token mà thể hiện vị trí trong ring. Mỗi node lưu trữ dữ liệu được ánh xạ bởi partition key đến token value bên trong mỗi range bởi node phía trước gán giá trị cho nó. Mỗi node cũng chứa bản sao của mỗi hàng từ node khác trong cluster. Ví dụ như Range E có các bản sao trên node 5, 6, 1. Đặc biệt một node sở hữu chính xác một partition range trong ring space.
-
Ring có Vnode: Trong cluster , vnode sẽ ngẫu nhiên chọn rac các phân vùng của dữ liệu và lưu trữ trên các node. Vị trí của một row được xác định bởi giá trị băm của partion key trong nhiều partition range nhỏ hơn thuộc về mỗi node.
Phân vùng dữ liệu (Partitioner)
Partitioner là việc bạn quyết định việc dữ liệu được phân tán như thế nào trên các node trong cluster (bao gồm cả các bản sao).
-
Trong Cassandra dữ liệu được quản lý bởi một cluster được đại diện như một không gian dữ liệu hay một ring. Vòng tròn (ring) được chia tương ứng với phạm vi là số lượng các node, mỗi node quản lý một hoặc nhiều vùng của dữ liệu. Trước khi một node có thể tham gia vòng nó được gắn một giá trị token (thẻ bài). Token xác định vị trí của node trên ring và phạm vi dữ liệu mà nó quản lý.
-
Application cần chỉ rõ giá trị nằm trong khoảng giữa các token và Cassandra sử dụng nó để điều hướng request tới node chứa dữ liệu đích.
-
Cassandra phân vùng dữ liệu trên cluster sử dụng consistent hashing. Trong consistent hashing phạm vị output trả về bởi hash function được chia ra trên một ring.
-
Consistent hashing cho phép việc phân tán dữ liệu trên các cluster mà giảm tối thiểu việc tái cấu trúc lại khi có một hoặc nhiều node được thêm vào hoặc xóa đi trong cluster.
-
Consistent hashing partitions data dựa trên partition key.
-
Ví dụ như mình có dữ liệu với trường
nameđược chọn làpartition key. Các giái trị trên trườngnameđược băm ra và sắp xếp theo thứ tự như bảng dưới đây
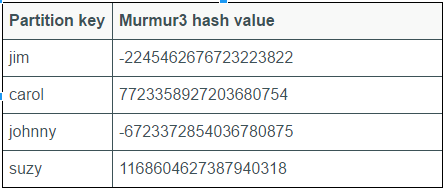
=> Sau đó mỗi node trên cluster sẽ quản lý một range dữ liệu dựa trên các giá trị băm được từ partition key.
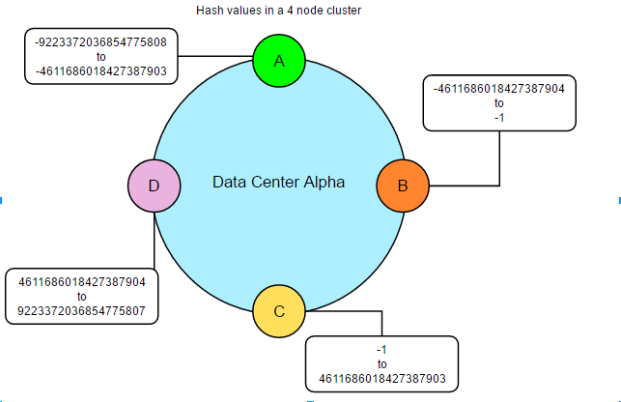
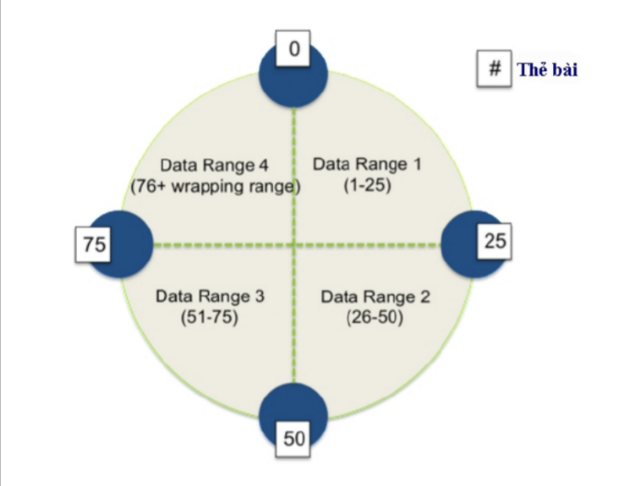
- Như hình trên chúng ta xem xét một cụm đơn giản gồm 4 nút, nơi tất cả các dữ liệu được quản lý bởi 1 cụm được đánh số trong khoảng từ 0 đến 100. Mỗi nút được gán một thẻ bài đại diện cho một điểm trong phạm vi này. Trong ví dụ này, các thẻ có giá trị là 0, 25, 50, và 75. Nút đầu tiên, với token 0, chịu trách nhiệm về phạm vi gói (75-0). Nút với thẻ bài thấp nhất cũng chấp nhận khóa hàng ít hơn so với các mã thẻ bài thấp nhất và nhiều hơn với các mã thẻ bài cao nhất.
Các loại phân vùng
Phân vùng ngẫu nhiên (RandomPartitioner):
-
Phân phối dữ liệu đồng thời trên các nút sử dụng giá trị băm MD5 của khóa hàng. Phạm vi có thể của các giá trị băm từ 0 tới 2127-1. Mỗi nút trong cụm được gán một thẻ bài đại diện một giá trị băm trong phạm vi này.
-
Đối với việc triển khai trung tâm dữ liệu đơn lẻ, các thẻ bài được tính bằng cách chia phạm vi băm cho số lượng các nút trong cụm. Đối với việc triển khai nhiều trung tâm dữ liệu thẻ được tính cho mỗi trung tâm dữ liệu.
Vậy thì lợi ích của phương pháp này là gì?
-
Nếu thẻ được đặt phù hợp thì dữ liệu từ tất cả các cột sẽ được phân bố đều trên toàn cụm mà không tốn nhiều thời gian xử lý. Đơn giản hóa việc cân bằng tại mỗi cụm.
-
Mỗi phần trong phạm vi băm sẽ nhận được một số lượng trung bình cộng các hàng, nó làm cho việc gán thẻ bài cho các nút trở nên dễ dàng hơn.
Phân vùng theo thứ tự (ByteOrderedPartitioner)
-
Đảm bảo các khóa hàng được được lưu trữ theo thứ tự sắp xếp.
-
Cho phép ta có thể tính toán giá trị token mà ta sở hữu và gán cho một nút nào đó do ta lựa chọn ngược lại với RandomPartitioner.
-
Chúng ta sẽ xem ví dụ dưới đây để có thể hiểu rõ hơn
Ta biết rằng tất cả các key được phân bố trong phạm vi 0 – 999. Ta có 10 nút và muốn gán chúng như sau:

*Tất cả các key nằm trong phạm vi từ 0 – 100 sẽ được lưu trữ trên node_1. ByteOrderedPartitioner cho phép ta tạo ra shard dữ liệu.
Bất lợi:
-
Khó cân bằng trong cụm
- bởi vì nó đòi hỏi người quản lý cần phải tính toán các phạm vi lưu trữ một cách thủ công. Trong thực tế điều này đòi hỏi việc di chuyển node token xung quanh phù hợp với thực tế phân phối dữ liệu khi nó được nạp.
-
Việc ghi tuần tự có thể tạo ra các điểm nóng (hot pots)
- Nếu ứng dụng có xu hướng ghi hoặc cập nhật dữ liệu một khối liên tục của hàng tại một thời điểm, sau đó việc ghi dữ liệu không được phân phối trên các cụm, tất cả chúng đều đi tới một nút. Điều này sẽ là vấn đề cho các ứng dụng xử lý dữ liệu ghi lại ngày tháng.
-
Cân bằng tải không đồng đều cho nhiều bảng
- Nếu ứng dụng có nhiều bảng rất có thể các bảng có những khóa hàng khác nhau và phân phối dữ liệu khác nhau. Một ordered partitioner mà được cân bằng cho một bảng có thể gây ra những điểm nóng và phân phối không đồng đều cho các bảng khác trong cùng một cụm.
-
Data Replication (Sao lưu dữ liệu)
-
Cassandra lưu trữ các bản sao (
replicas) dữ liệu trên nhiều node khác nhau. Mở rộng các node nơi mà các bản sao được lưu trữ. Tổng số bản sao trên cụm (cluster) được gọi làreplication factor. Nếu gía trịreplication factormà là 1 nghĩa là chỉ có một bản sao của mỗi hàng trên một node. Replication factor là 2 có nghĩa là có 2 bản sao của mỗi hàng, mỗi bản copie nằm trên mỗi node khác nhau. Tất cả các bản sao có mức đô quan trọng ngang nhau, tất nhiên số replication factor không được vượt quá tổng số node trong cụm. -
Giả sử có RF (replication factor) = 2. Khi đó có 2 bản sao, khi ghi dữ liệu cả 2 bản sao sẽ được lưu trữ, giả sử rằng ta có đủ số node. Khi một node bị lỗi, việc ghi dữ liệu cho node đó được giấu đi bằng cách nào đó và sẽ được ghi lại vào node khi mà nó được fixed trở lại, trừ khi nó bị lỗi đủ lâu thì Cassandra sẽ hủy tác vụ đó.
-
Có hai chiến lược để Replication đó là
-
SimpleStrategy:
- Chỉ sử dụng đối với 1 data center. SimpleStrategy sẽ đặt bản sao đầu tiên trên một nút xác định bởi partitioner, các bản sao tiếp theo được lưu trên node kế tiếp theo chiều kim đồng hồ mà không cần xem xét tới cấu trúc liên kết
-
NetworkTopologyStrategy
- Sử dụng khi mà các cluster được triển khai trên nhiều data center, chiến lược này xác định bao nhiêu bản sao mà mình muốn trên mỗi data center. NTS sẽ đặt các bản sao trên cùng data center, và chuyển dịch theo chiều kim đồng hồ cho tới khi gặp node đầu tiên trong một rack khác. NTS đặt các bản sao trên các rack khác nhau bởi vì các node trong cùng một rack thường bị lỗi tại cùng thời điểm do vấn đề power, cooling, hoặc network issues.
-
-
Khi quyết định bao nhiêu bản sao sẽ được lưu trữ trên một data center thì có 2 vấn đề chính cần cân nhắc đó là
- Có thể đọc cục bộ, mà không phụ thuộc vào độ trễ của data center
- Các kịch bản thất bại
Hai cách phổ biến nhất để cấu hình nhiều cụm data center đó là
- Hai bản sao trên mỗi data center: Cách cấu hình này cho phép sự thất bại của một node duy nhất cho mỗi nhóm replication và vẫn cho phép local đọc consistency (nhất quán) level of ONE.
- Ba bản sao trên mỗi data center: cho phép hoặc lỗi trên một node mỗi nhóm replication tại strong Consistency level của LOCAL_QUORUM hoặc nhiều node bị lỗi trên mỗi data center sử dụng CL = ONE.
Tổng kết
Cá nhân mình thấy Cassandra cũng là một hệ quản trị cơ sở dữ liệu khá là hay tuy chưa được sử dụng rộng rãi như Mysql, Mongo.. trong ứng dụng mà chúng ta sử dụng ở trường hay mình cũng chưa thấy ngoài công ty sử dụng
Tuy nhiên cũng đâu phải tự dưng mà Facebook sử dụng Cassandra để các status của chúng ta được lưu trữ hằng ngày như vậy.
Cảm ơn các bạn đã dành thời gian đọc bài viết của mình!
All rights reserved
