Ví dụ về việc thu thập dữ liệu Web với Scrapy
Bài đăng này đã không được cập nhật trong 8 năm
Lời mở đầu
Chào các bạn, tình cờ bạn của mình có cho mình xem trang này: https://loza.vn - là một trang bán sản phẩm thời trang cho nữ, xem qua thấy khá là thích mắt, thế là mình có ý định crawl hết đống ảnh sản phẩm về  . Để làm được điều ấy thì mình có sử dụng Scrapy - một framework viết bằng python.
Các bạn có thể xem qua một tutorial của chính Scrapy tại trang: https://doc.scrapy.org/en/latest/intro/tutorial.html
. Để làm được điều ấy thì mình có sử dụng Scrapy - một framework viết bằng python.
Các bạn có thể xem qua một tutorial của chính Scrapy tại trang: https://doc.scrapy.org/en/latest/intro/tutorial.html
Thực hiện
Tạo project
Đầu tiên, chúng ta cần tạo project. Di chuyển đến thư mục bạn muốn lưu project, sau đó chạy dòng lệnh sau:
scrapy startproject loza
Ví dụ về Spider
Ví dụ về 1 file Spider:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
Giải thích:
- name : tên của Spider, là tên duy nhất trong một project. Trong một project Scrapy, bạn không thể đặt tên giống nhau cho các Spider khác nhau.
- start_urls : mảng chứa danh sách các link mà Spider sẽ bắt đầu crawl.
- parse : phương thức mà sẽ được gọi để xử lý response đã được trả về cho mỗi request được tạo ra.
(Xem thêm tutorial của Scrapy để biết chi tiết hơn)
Viết Spider của chúng ta.
1. Phân tích
-
Mục đích của mình là lấy hết tất cả các ảnh (một sản phẩm có thể có nhiều ảnh) của các sản phẩm của trang https://loza.vn
-
Trang này chia danh mục sản phẩm như sau: Áo sơ mi, Quần, Váy đầm, Chân váy, Vest nữ, Áo khoác, Bộ đồ, Dạo phố.
-
Ví dụ khi chạy vào link: Áo sơ mi - https://loza.vn/ao-so-mi-nu
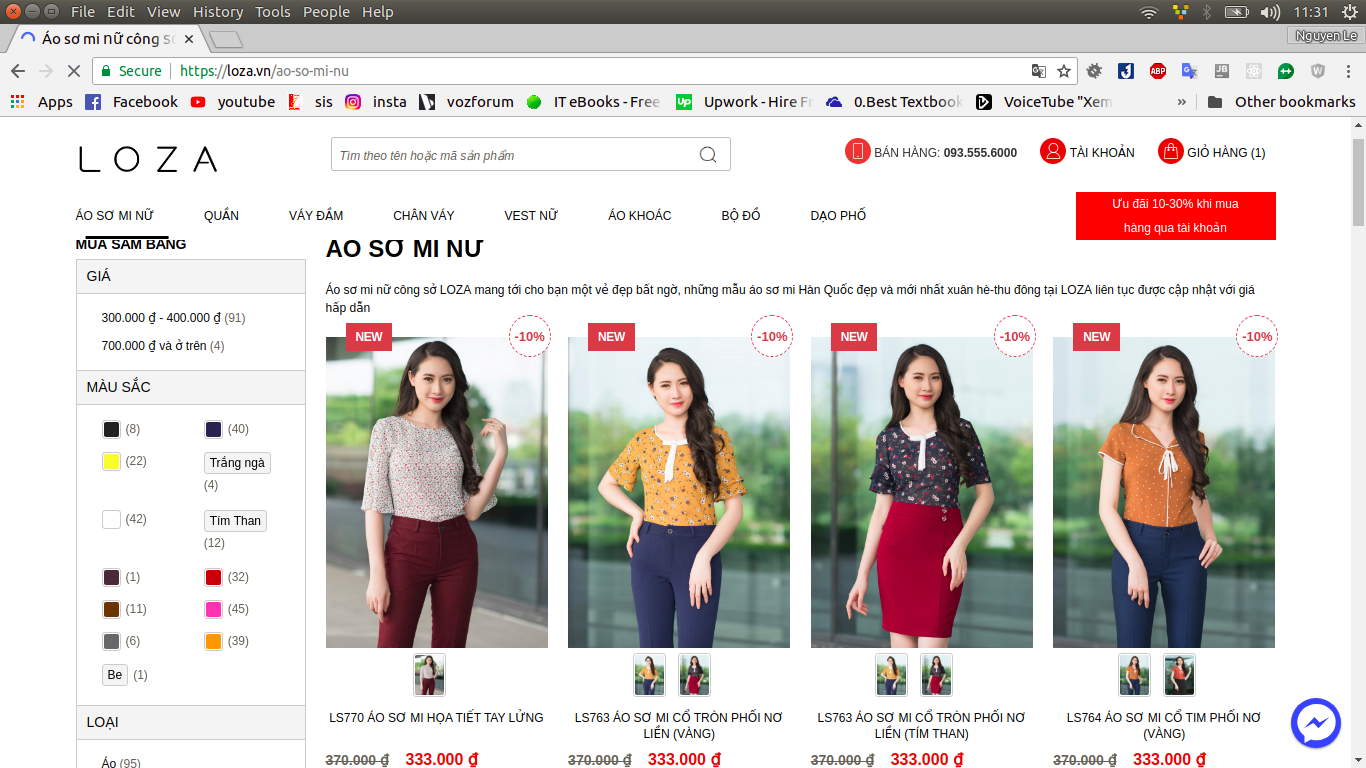
Mình muốn lấy tất cả các ảnh của các sản phẩm thuộc trang này. Tuy nhiên ảnh mà mình và các bạn nhìn thấy ở trang này mới chỉ là "ảnh đại diện" cho sản phẩm. Click vào một sản phẩm nào đó, bạn sẽ được chuyển đến trang chi tiết sản phẩm với nhiều ảnh hơn. Ví dụ khi click vào một sản phẩm.
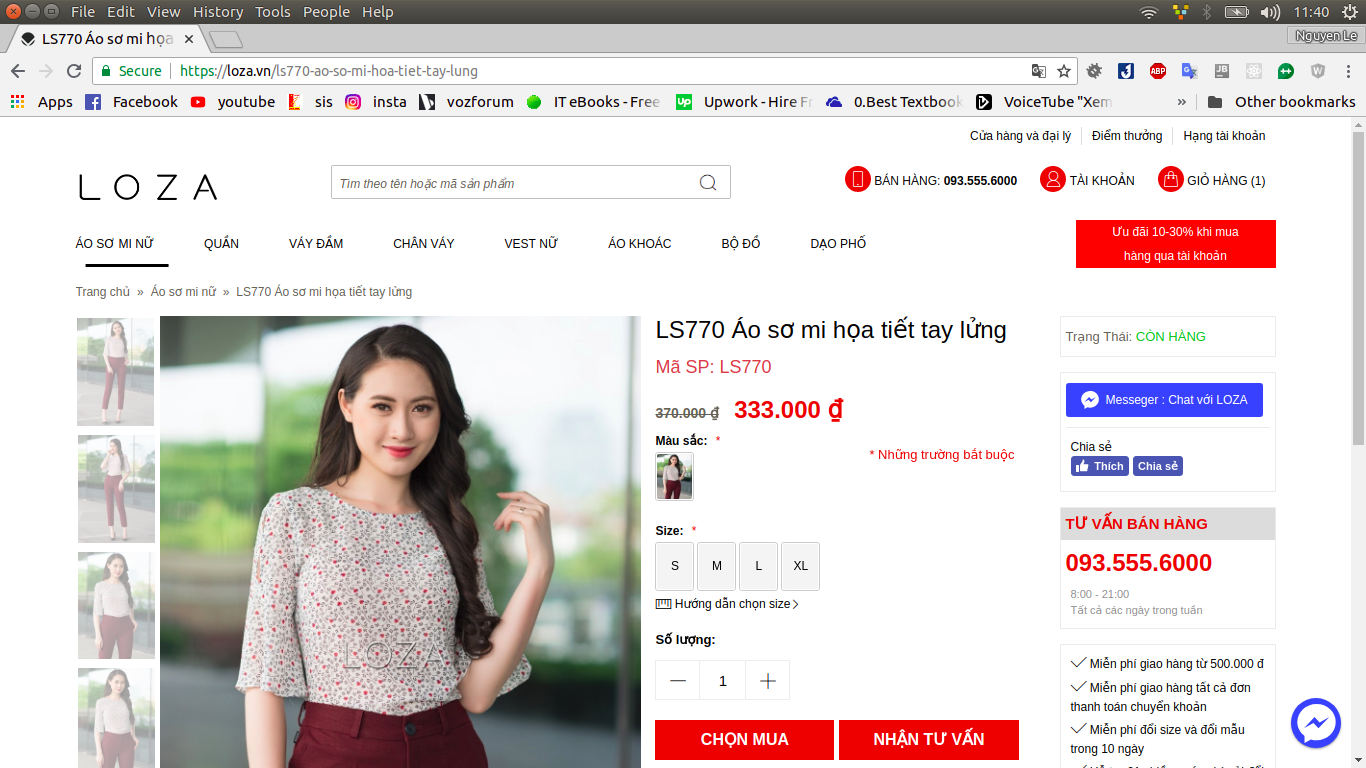
Các bạn thể thấy, trang này chứa nhiều ảnh của một sản phẩm và ý định của mình là lấy hết những ảnh đó. Lúc này, khi bạn để click vào ảnh sản phẩm thì sẽ xem được danh sách ảnh của sản phẩm như sau:
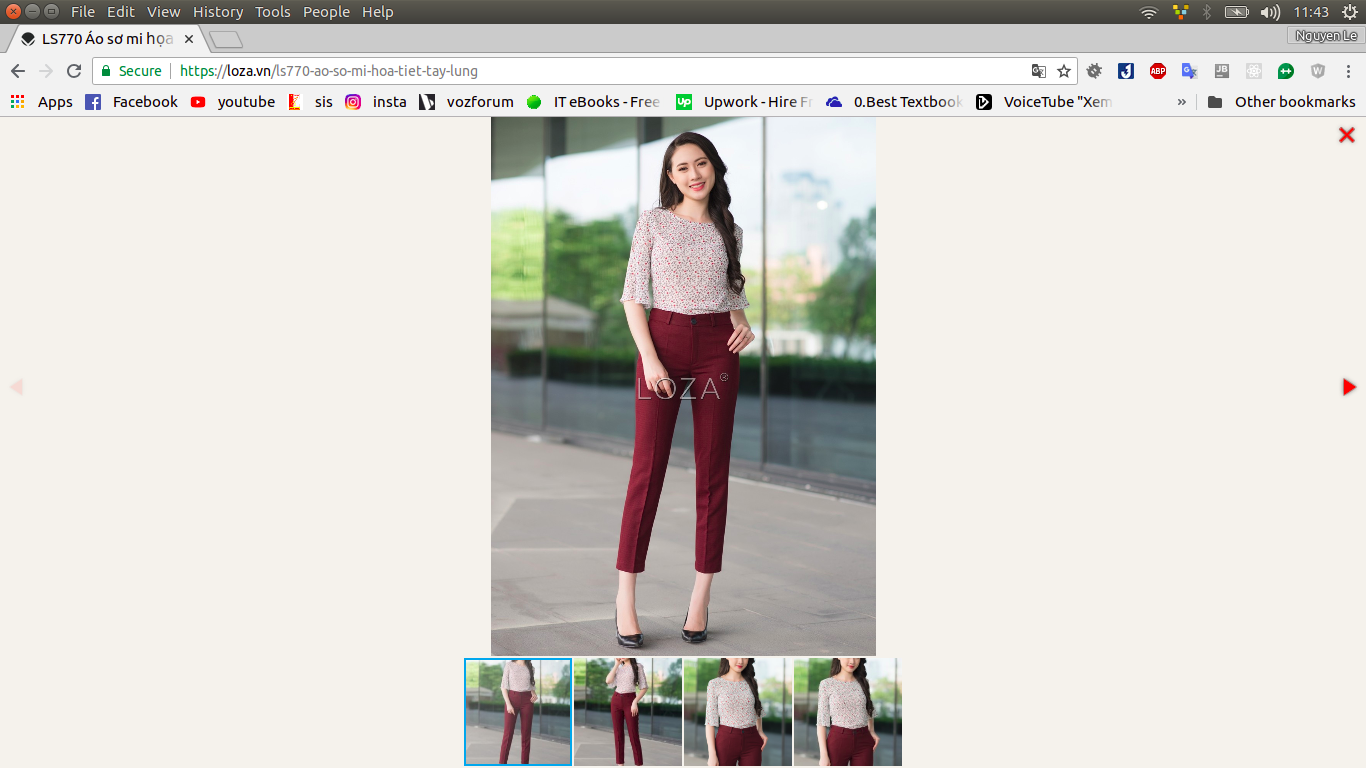
Sau khi phân tích, mình rút ra luồng thực hiện như sau:
- Đầu tiên, Spider của mình xuất phát từ mảng start_urls.
- Đối với response cho mỗi url (chính là nội dung của một trang danh mục sản phẩm), mình sẽ phải lấy hết lấy được hết link trỏ đến trang chi tiết các sản phẩm.
- Với mỗi link chi tiết sản phẩm đã lấy được, mình phải tạo request đến liên kết để lấy được nội dung của trang chi tiết, tức là sẽ lấy được ảnh chi tiết.
- Với mỗi trang chi tiết, mình phải tạo request đến các link ảnh chi tiết của sản phẩm để lấy được nội dung ảnh.
- Lưu ảnh lại.
2. Thực hiện code
import scrapy
class LozaSpider(scrapy.Spider):
name = "loza"
start_urls = [
"https://loza.vn/ao-so-mi-nu",
"https://loza.vn/quan-cong-so-nu",
"https://loza.vn/vay-dam",
"https://loza.vn/chan-vay",
"https://loza.vn/vest-nu",
"https://loza.vn/ao-khoac-nu",
"https://loza.vn/set-do",
"https://loza.vn/thoi-trang-dao-pho"
]
def parse(self, response):
for item_link in response.css('div.category-products li.item a.product-image::attr(href)').extract():
yield scrapy.Request(item_link, callback=self.parse_single_item)
def parse_single_item(self, response):
for link in response.css('div.more-views ul li a img').xpath('@src').extract():
img_link = link.replace("thumbnail/200x280", "image/1000x")
yield scrapy.Request(img_link, callback=self.parse_img)
def parse_img(self, response):
with open("image/%s" % response.url.split('/')[-1], 'wb') as f:
f.write(response.body)
Giải thích:
- start_urls chứa các liên kết đến các danh mục sản phẩm mà chúng ta cần lấy.
- Hàm parse:
- response lúc này chính là nội dung được trả về khi truy cập từng link trong start_urls.
- response.css() cho phép bạn lựa chọn phần tử html sử dụng CSS. (Bạn nên tham khảo trang chủ của Scrapy để biết thêm)
- response.css('div.category-products li.item a.product-image::attr(href)').extract() trả về danh sách các link chi tiết sản phẩm.
- yield scrapy.Request(item_link, callback=self.parse_single_item): tạo một request mới tới link item_link (ở đây là request mới tới link chi tiết sản phẩm), tham số callback xác định hàm sẽ thực hiện sau khi response được trả về. Trong trường hợp này, mình gọi hàm parse_single_item.
- Hàm parse_single_item thực hiện xử lý cho trang chi tiết sản phẩm.
Các bạn để ý, ở đây mình có dòng img_link = link.replace("thumbnail/200x280", "image/1000x"), lý do là, ở trang chi tiết sản phẩm, những ảnh ở phía bên trái sẽ có link dạng: "...thumbnail/200x280/LS770_ao_so_mi_hoa_tiet_2_.jpg"
Tuy nhiên ảnh mà mình muốn lấy với độ phân giải cao hơn, sẽ có link dạng: "...image/1000x/LS770_ao_so_mi_hoa_tiet_2_.jpg" - yield scrapy.Request(item_link, callback=self.parse_single_item): tạo request mới tới link img_link (ở đây chính là request tới link của từng ảnh chi tiết của sản phẩm), tham số callback sẽ gọi hàm parse_img.
- Hàm parse_img:
- Hàm này thực hiện việc lưu ảnh chi tiết của sản phẩm vào máy của chúng ta (ở đây mình lưu vào thư mực image cùng cấp với thư mục project).
- Tên ảnh thì mình làm như sau:
- link ảnh mình muốn tải về có dạng: https://loza.vn/media/catalog/product/cache/image/1000x/C534_Chan_vay_vat_lech_2__2.jpg
- response.url.split('/')[-1] sẽ trả về tên là: "C534_Chan_vay_vat_lech_2__2.jpg"
Sau khi đã viết code xong, chạy lệnh để thực hiện crawl
scrapy crawl loza
Kết luận
Vừa rồi, mình đã cùng các bạn thực hiện crawl ảnh từ một trang web. Dữ liệu ảnh này bạn có thể dùng để làm một website thương mại điện tử (sản phẩm demo thôi nhá vì ảnh có bản quyền rồi :v). Bên cạnh đó, nếu bạn có hứng thú thì có tìm hiểu thêm framework Scrapy - một framework thu thập dữ liệu khá nổi tiếng của python. Có thể trong quá trình bạn làm một trang web hoặc một công việc gì đó mà không có dữ liệu demo hoặc cần thu thập dữ liệu từ các trang web, lúc ấy, có thể bạn sẽ cần đến Scrapy đấy. Cảm ơn các bạn đã đọc bài của mình.
Tài liệu tham khảo: https://doc.scrapy.org/en/latest/intro/tutorial.html
Link code demo: https://github.com/NLAQ/crawl-image-loza
All rights reserved
