Vector Database với Milvus
Dữ liệu phi cấu trúc đang ngày càng phát triển, và các mô hình deep learning hiện nay có thể chuyển đổi dữ liệu không có cấu trúc thành các vector embeddings để xử lý, phân tích và so sánh một cách hiệu quả hơn. Vector embeddings là một biểu diễn dữ liệu nhỏ gọn và ý nghĩa hơn, có thể nắm bắt các mối quan hệ và cấu trúc ngầm.
Tuy nhiên, do tính chất high-dimensional của chúng, các cơ sở dữ liệu truyền thống thường gặp khó khăn trong việc quản lý vector embeddings một cách hiệu quả. Điều này đã dẫn đến sự phát triển của các cơ sở dữ liệu vector chuyên biệt, được thiết kế để xử lý loại dữ liệu này.
1. Vector Databases
Vector Databases được thiết kế để lưu trữ, tìm kiếm và quản lý dữ liệu vector một cách hiệu quả. Mỗi vector đại diện cho một đối tượng hoặc mục, chẳng hạn như một từ, hình ảnh, âm thanh hoặc bất kỳ loại dữ liệu nào khác. Những cơ sở dữ liệu này thường tập trung vào việc tìm kiếm tương tự vector và cho phép người dùng tìm và truy xuất các đối tượng tương tự một cách nhanh chóng ở quy mô lớn. Chúng ta sẽ đi sâu vào một cơ sở dữ liệu vector mã nguồn mở được gọi là Milvus, để xem cách hoạt động của những cơ sở dữ liệu này.
2. Milvus

Milvus là một hệ thống quản lý dữ liệu vector mã nguồn mở, giúp lưu trữ và tìm kiếm dữ liệu vector lớn và động một cách hiệu quả. Nó được xây dựng trên nền tảng Facebook Faiss, một thư viện C++ mã nguồn mở dành cho tìm kiếm tương tự vector. Milvus đã cải thiện Faiss bằng cách làm cho nó nhanh hơn, thêm nhiều tính năng hơn, và làm cho nó dễ sử dụng hơn cho người mới. Chúng ta sẽ đi sâu vào cách Milvus thực hiện điều này bằng cách xem xét một số cải tiến mà nó mang lại cho Faiss.
Dưới đây là những gì Milvus cung cấp:
-
Các loại truy vấn: Hỗ trợ các loại truy vấn đa dạng bao gồm: vector similarity search, attribute filtering, multi-vector query.
-
Dynamic Vector Data: Quản lý hiệu quả dữ liệu Dynamic Vector như chèn và xóa, thông qua cấu trúc dựa trên LSM, đồng thời cung cấp các tìm kiếm thời gian thực nhất quán với cô lập snapshot.
-
Indexes: Hỗ trợ chủ yếu các Index dựa trên lượng tử hóa, Index dựa trên đồ thị và giao diện mở rộng để dễ dàng tích hợp các Index mới vào hệ thống.
-
Heterogeneous Computing: Tận dụng nền tảng tính toán không đồng nhất với cả CPU và GPU để đạt được hiệu năng cao.
-
Distributed System: Là một hệ thống quản lý dữ liệu phân tán được triển khai trên nhiều node để đạt được khả năng mở rộng và sẵn sàng.
-
Giao diện ứng dụng: Cung cấp nhiều giao diện ứng dụng, bao gồm SDK và API RESTful, dễ dàng sử dụng bởi các ứng dụng.
3. System Design
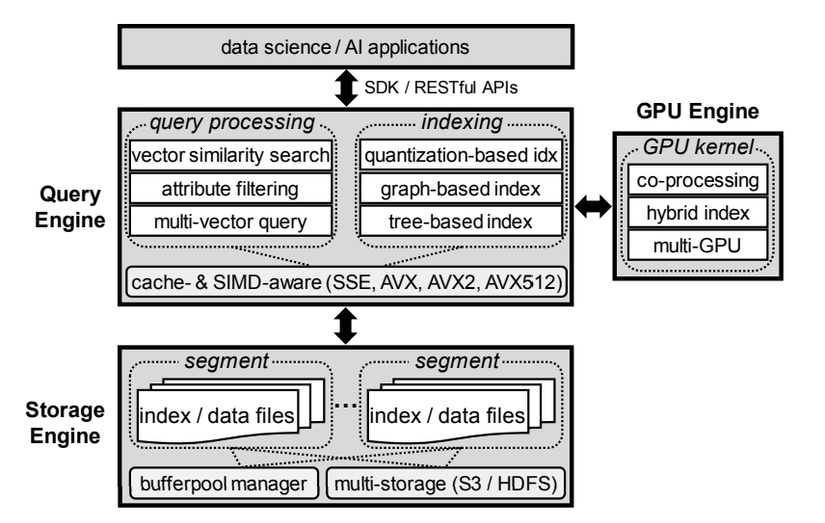
Kiến trúc hệ thống của Milvus bao gồm ba thành phần chính: Query Engine, GPU Engine và Storage Engine.
Query Engine: Hỗ trợ xử lý truy vấn hiệu quả trên dữ liệu vector và được tối ưu hóa cho các CPU hiện đại bằng cách giảm thiểu các lỗi cache và tận dụng các lệnh SIMD.
GPU Engine: Một engine đồng xử lý tăng cường hiệu suất với sự song song rộng lớn và hỗ trợ nhiều thiết bị GPU để đạt hiệu quả cao.
Storage Engine: Đảm bảo độ bền dữ liệu và tích hợp cấu trúc dựa trên log-structured merge-tree (LSM) cho quản lý dữ liệu động. Nó hoạt động trên nhiều hệ thống tệp với một bộ nhớ đệm trong bộ nhớ.
4. Query Processing
Trong Milvus, một dữ liệu có thể là một hoặc nhiều vector và tùy chọn thêm một số thuộc tính số học (dữ liệu không phải vector), vì nó hỗ trợ truy vấn đa vector và lọc thuộc tính. Có ba loại truy vấn cơ bản:
-
Truy vấn Vector: Tìm kiếm tương đồng trên một vector truy vấn đơn lẻ, trả về k vector tương đồng nhất.
-
Lọc thuộc tính: Tìm kiếm tương đồng vector đã được lọc trên một vector truy vấn đơn lẻ, trả về k vector tương đồng nhất trong khi tuân thủ các ràng buộc thuộc tính.
-
Multi-Vector Queries: Tìm kiếm tương đồng trên truy vấn multi-vector, trả về k multi-vector tương đồng nhất theo một hàm tổng hợp giữa nhiều vector.
Đối với tìm kiếm tương đồng, Milvus hỗ trợ các chỉ số tương đồng phổ biến như khoảng cách Euclidean, inner product, tương đồng cosine, khoảng cách Hamming và khoảng cách Jaccard, và cho phép các ứng dụng khám phá phương pháp hiệu quả nhất cho các trường hợp sử dụng của họ.
5. Indexes
Lập chỉ mục là rất quan trọng đối với hiệu suất truy vấn. Milvus chủ yếu hỗ trợ các chỉ mục dựa trên lượng tử hóa và chỉ mục dựa trên đồ thị. Chúng ta sẽ giải thích các chỉ mục dựa trên lượng tử hóa vì chúng tiêu tốn ít bộ nhớ hơn nhiều và nhanh hơn trong việc xây dựng so với các chỉ mục dựa trên đồ thị. Trước tiên, chúng ta sẽ nói về lượng tử hóa vector là gì:
5.1. Lượng tử hóa Vector
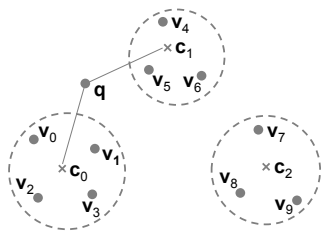
Ý tưởng chính của lượng tử hóa vector là áp dụng một bộ lượng tử để ánh xạ một vector tới một từ mã được chọn từ một bảng mã. Thuật toán phân cụm K-mean thường được sử dụng để xây dựng bảng mã. Trong Hình 3, chúng ta có 10 vector. Sau khi áp dụng phân cụm K-mean, chúng ta có ba cụm. Ba tâm cụm sẽ là các từ mã, và bộ lượng tử q sẽ ánh xạ mỗi vector đến tâm cụm gần nhất của nó.
Hãy tóm tắt lượng tử hóa vector trong hai bước:
Tạo bảng mã: Sử dụng phân cụm K-mean để tạo ra một bảng mã, là một tập hợp các vector tâm cụm cho mỗi cụm.
Lượng tử hóa: Bộ lượng tử sẽ ánh xạ mỗi vector đến vector tâm cụm gần nhất trong bảng mã.
5.2. Chỉ mục Dựa trên Lượng tử hóa
Các chỉ mục dựa trên lượng tử hóa sử dụng hai bộ lượng tử: bộ lượng tử thô và bộ lượng tử tinh vi. Bộ lượng tử thô áp dụng phân cụm K-mean để phân chia các vector thành K cụm. Bộ lượng tử tinh vi mã hóa các vector trong mỗi cụm. Milvus hỗ trợ các chỉ mục khác nhau cho các kịch bản khác nhau với các sự đánh đổi khác nhau giữa tốc độ, bộ nhớ và khả năng hồi phục. Ví dụ, chỉ mục IVF_FLAT sử dụng đại diện vector gốc làm mã hóa và cung cấp truy vấn và khả năng hồi phục tốc độ cao, nhưng yêu cầu quét tốn kém hơn trong các cụm liên quan.
Tiếp theo, chúng ta sẽ thảo luận về cách xử lý truy vấn được thực hiện với các chỉ mục dựa trên lượng tử hóa.
Xử lý truy vấn của một truy vấn q trên các chỉ mục dựa trên lượng tử hóa bao gồm hai thao tác:
-
Tìm n_probe cụm gần nhất dựa trên khoảng cách giữa q và tâm cụm của mỗi cụm.
-
Tìm kiếm trong từng cụm liên quan n_probe dựa trên các bộ lượng tử tinh vi khác nhau.
n_probe là một tham số điều khiển sự đánh đổi giữa độ chính xác và hiệu suất. n_probe cao hơn tăng độ chính xác vì nó giảm cơ hội bỏ lỡ các kết quả thực, nhưng làm giảm hiệu suất vì nó yêu cầu nhiều tìm kiếm hơn.
Thách thức chính trong việc tối ưu hóa xử lý truy vấn trên các chỉ mục dựa trên lượng tử hóa là nhanh chóng tìm ra các vector tương đồng top-k cho một tập hợp các truy vấn so với một tập hợp các vector dữ liệu. Tóm lại, chúng ta muốn cải thiện hai thao tác chính: tìm các cụm liên quan và tìm kiếm trong từng cụm liên quan.
Chúng ta sẽ thảo luận về cách Milvus giải quyết vấn đề này trong phần tiếp theo.
6. Tối ưu hóa Xử lý Truy vấn
Milvus tối ưu hóa xử lý truy vấn bằng cách tận dụng nền tảng tính toán không đồng nhất bao gồm cả CPU và GPU để đạt được hiệu suất cao. Chúng ta sẽ thảo luận chi tiết về tối ưu hóa hướng CPU, tối ưu hóa hướng GPU, và tối ưu hóa phối hợp GPU & CPU.
6.1. Tối ưu hóa Hướng CPU
-
Tối ưu hóa hướng CPU chủ yếu bao gồm các tối ưu hóa Cache-aware và SIMD-aware.
-
Tối ưu hóa Cache-aware: Phương pháp này tái sử dụng các vector dữ liệu đã truy cập càng nhiều càng tốt để giảm thiểu lỗi cache của CPU. Nó phân bổ các luồng cho các vector dữ liệu thay vì các vector truy vấn để tận dụng tốt nhất tính song song đa lõi, vì kích thước dữ liệu thường lớn hơn nhiều so với kích thước truy vấn trong thực tế.
-
Tối ưu hóa SIMD-aware: SIMD, viết tắt của Single Instruction, Multiple Data, đề cập đến các thành phần phần cứng thực hiện cùng một phép toán trên nhiều toán hạng dữ liệu đồng thời. Milvus hỗ trợ một loạt các lệnh SIMD và cho phép tự động chọn lệnh SIMD trong thời gian chạy.
6.2. Tối ưu hóa Hướng GPU
Tối ưu hóa hướng GPU chủ yếu bao gồm việc hỗ trợ xử lý truy vấn lớn 𝑘 trong kernel GPU và hỗ trợ các thiết bị GPU đa dạng.
Xử lý Truy vấn Lớn-k: Để hỗ trợ các giá trị k lớn hơn 1024, vốn bị giới hạn bởi bộ nhớ chia sẻ, Milvus thực hiện truy vấn theo kiểu round-by-round để tổng hợp và tạo ra kết quả cuối cùng.
Hỗ trợ Thiết bị GPU Đa dạng: Milvus hỗ trợ nhiều thiết bị GPU và cho phép người dùng chọn bất kỳ số lượng thiết bị GPU nào trong thời gian chạy thay vì thời gian biên dịch.
Tối ưu hóa phối hợp GPU & CPU
Trong chế độ này, nếu bộ nhớ GPU không đủ lớn để lưu trữ toàn bộ dữ liệu, các thách thức là cải thiện việc sử dụng I/O chuyển dữ liệu và sử dụng CPU khi chi phí di chuyển dữ liệu cao hơn lợi ích của việc sử dụng GPU.
Trong triển khai gốc của Facebook Faiss, băng thông I/O không được sử dụng tối đa vì nó sao chép dữ liệu từ CPU sang GPU theo từng cụm. Nó cũng thực hiện các truy vấn trên GPU ngay cả khi CPU có thể nhanh hơn do overhead chuyển dữ liệu.
Milvus giải quyết hai hạn chế này. Nó cải thiện việc sử dụng I/O bằng cách sao chép nhiều cụm nếu có thể trong thời gian thực. Nó cũng thực hiện các truy vấn theo cách hỗn hợp khi cần như sau:
- Nếu kích thước lô truy vấn lớn hơn một ngưỡng, thì tất cả các truy vấn sẽ được thực hiện trên GPU vì khối lượng công việc nặng hơn về tính toán.
- Ngược lại, Milvus thực hiện các truy vấn theo cách hỗn hợp. Phép toán đầu tiên của xử lý truy vấn (tìm các cụm liên quan) sẽ được thực hiện bởi GPU, và phép toán thứ hai (tìm kiếm trong từng cụm liên quan) sẽ được thực hiện bởi CPU.
Giờ đây, khi chúng ta đã hiểu cách Milvus tối ưu hóa xử lý truy vấn bằng cách tận dụng nền tảng tính toán không đồng nhất, chúng ta sẽ tìm hiểu về xử lý truy vấn nâng cao bao gồm lọc thuộc tính và truy vấn multi-vector.
7. Advance Query Processing
- Attribute Filtering
- Lọc Thuộc Tính
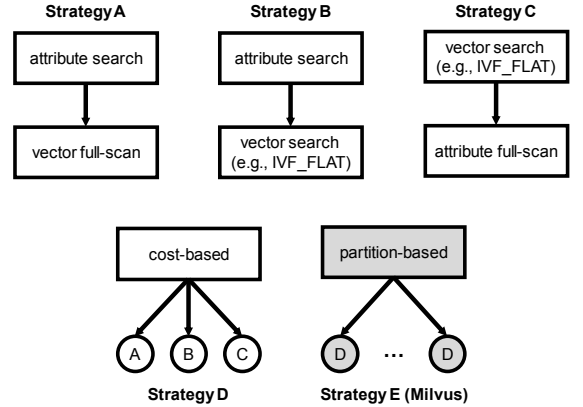
Milvus đã triển khai bốn phương pháp lọc thuộc tính (chiến lược A, B, C, D) dựa trên các nghiên cứu trong AnalyticDB-V. Chiến lược D là một chiến lược dựa trên chi phí, ước lượng chi phí của các chiến lược A, B và C và chọn chiến lược có chi phí thấp nhất. Milvus đã phát triển một chiến lược mới dựa trên phân vùng E nhanh hơn so với chiến lược D. Chúng ta sẽ giải thích ngắn gọn từng chiến lược:
-
Chiến lược A: Chiến lược này đầu tiên sử dụng ràng buộc thuộc tính để thu được các vector liên quan. Các vector liên quan sau đó được quét toàn bộ để so sánh với vector truy vấn để tạo ra kết quả top-k cuối cùng. Chiến lược này phù hợp khi ràng buộc thuộc tính rất chọn lọc.
-
Chiến lược B: Chiến lược này tương tự như chiến lược A, nhưng sau khi lọc thuộc tính, thay vì quét toàn bộ, xử lý truy vấn vector bình thường được thực hiện trên các vector liên quan để có kết quả top-k cuối cùng. Chiến lược này phù hợp khi ràng buộc thuộc tính và ràng buộc truy vấn vector đều có tính chọn lọc vừa phải.
-
Chiến lược C: Chiến lược này đầu tiên áp dụng xử lý truy vấn vector bình thường để thu được các vector liên quan. Các vector liên quan sau đó được quét toàn bộ để xác minh xem chúng có thỏa mãn ràng buộc thuộc tính không.
-
Chiến lược D: Chiến lược này là một phương pháp dựa trên chi phí, ước lượng chi phí của các chiến lược A, B và C và chọn chiến lược có chi phí thấp nhất.
-
Chiến lược E: Đây là một chiến lược dựa trên phân vùng mà Milvus sử dụng. Ý tưởng chính là phân vùng tập dữ liệu dựa trên thuộc tính thường xuyên được tìm kiếm và áp dụng phương pháp dựa trên chi phí cho mỗi phân vùng.
Điều này cho thấy cách Milvus cải thiện hiệu suất lọc thuộc tính bằng cách phát triển một chiến lược mới dựa trên phân vùng, sử dụng và cải thiện các phương pháp hiện có. Tiếp theo, chúng ta sẽ thảo luận về truy vấn multi-vector.
8. Multi-Vector Queries
Trong các truy vấn multi-vector, mục tiêu của chúng ta là tìm các multi-vector top-k theo một hàm điểm tổng hợp nào đó trên hàm tương đồng của từng vector. Giả sử mỗi multi-vector chứa n vector và chúng ta có một hàm điểm tổng hợp ( g ), một hàm tương đồng ( f ), và hai multi-vector ( X ) và ( Y ). Quy trình tính toán sự tương đồng giữa ( X ) và ( Y ) được mô tả dưới đây.
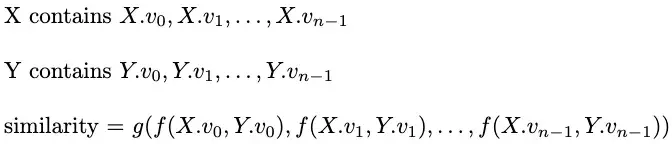
Milvus phát triển hai phương pháp (hợp nhất vector và hợp nhất lặp) để tìm các multi-vector top-k một cách hiệu quả cho các kịch bản khác nhau.
Hợp Nhất Vector:
Phương pháp này giả định rằng hàm tương đồng có thể phân rã, chẳng hạn như tích nội, điều này áp dụng trong hầu hết các trường hợp khi dữ liệu cơ sở được chuẩn hóa.
Giả sử ( e ) là bất kỳ multi-vector nào trong tập dữ liệu, mỗi multi-vector có ( n ) vector. Phương pháp này lưu trữ ( e ) dưới dạng một vector nối tiếp ( v ) như sau.
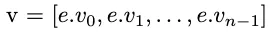
Giả sử ( q ) là multi-vector truy vấn. Phương pháp này áp dụng hàm tổng hợp ( g ) cho ( n ) vector của ( q ), tạo ra một vector truy vấn tổng hợp như sau.
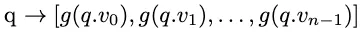
Bây giờ, áp dụng xử lý truy vấn vector để tìm các multi-vector top-k sử dụng các vector nối tiếp và vector truy vấn tổng hợp.
Tiếp theo, chúng ta sẽ xem xét phương pháp thứ hai, hợp nhất lặp, cho các trường hợp khi dữ liệu cơ sở không được chuẩn hóa và hàm tương đồng không thể phân rã.
Hợp Nhất Lặp:
Phương pháp này được xây dựng dựa trên Thuật toán Fagin’s No Random Access (NRA), một kỹ thuật tổng quát cho xử lý truy vấn top-k.

Giả sử ( q ) là multi-vector truy vấn và ( k ) là số lượng kết quả mà chúng ta muốn. Giả sử ( k' ) là một biến bắt đầu với giá trị ( k ), nhưng liên tục thích ứng (gấp đôi) khi thuật toán tiến triển. Giả sử ( D ) là tập dữ liệu và ( D_i ) là tập hợp các ( v_i ) của tất cả các multi-vector ( e ).
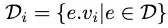
Thuật toán lặp đi lặp lại xử lý truy vấn top-k’ cho mỗi ( q.v_i ) trên ( D_i ) và đưa kết quả vào ( R_i ). Sau đó, nó thực hiện thuật toán NRA trên tất cả các ( R_i ). Nếu ( k ) kết quả có thể được xác định hoàn toàn sau khi áp dụng NRA trên tất cả các ( R_i ), thì thuật toán có thể dừng lại và trả về kết quả top-k. Nếu không, gấp đôi giá trị ( k' ) và chạy lại thuật toán cho đến khi ( k' ) đạt đến một ngưỡng.
9. Storage Engine
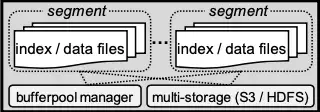
Engine Lưu trữ
Engine lưu trữ chủ yếu bao gồm các phân đoạn dữ liệu, trình quản lý bộ nhớ đệm, và lưu trữ đa dạng, chúng ta sẽ thảo luận dưới đây.
Phân Đoạn Dữ Liệu
Milvus hỗ trợ dữ liệu vector động thông qua các thao tác chèn và xóa. Nó sử dụng log-structured merge-tree (LSM) để lưu trữ dữ liệu mới chèn vào bộ nhớ trước, sau đó ghi vào đĩa dưới dạng phân đoạn không thay đổi khi kích thước tích lũy đạt đến một ngưỡng. Các phân đoạn nhỏ hơn được gộp vào các phân đoạn lớn hơn để truy cập tuần tự nhanh hơn. Dữ liệu đã bị xóa được loại bỏ trong quá trình gộp phân đoạn.
Trình Quản Lý Bộ Nhớ Đệm
Hầu hết dữ liệu và chỉ mục được giữ trong bộ nhớ để đạt hiệu suất cao. Nếu không, engine lưu trữ sử dụng trình quản lý bộ đệm dựa trên LRU để lưu trữ các phân đoạn.
Lưu Trữ Đa Dạng
Milvus hỗ trợ nhiều hệ thống tệp bao gồm hệ thống tệp cục bộ, Amazon S3, và HDFS cho lưu trữ dữ liệu cơ sở.
10. Triển Khai Hệ Thống
Xử Lý Bất Đồng Bộ
Milvus cải thiện thông lượng với xử lý bất đồng bộ, trong đó các thao tác ghi được xử lý và các chỉ mục được xây dựng một cách bất đồng bộ. Milvus cung cấp API flush() để chặn tất cả các yêu cầu đến cho đến khi hệ thống hoàn tất việc xử lý tất cả các thao tác còn tồn đọng.
Snapshot Isolation
Milvus đảm bảo Snapshot Isolation để duy trì cái nhìn nhất quán cho các thao tác đọc và ghi vì nó hỗ trợ quản lý dữ liệu động. Mỗi truy vấn hoạt động trên ảnh chụp có sẵn tại thời điểm bắt đầu truy vấn, và các cập nhật tiếp theo tạo ra các snapshot mới mà không làm gián đoạn các truy vấn đang diễn ra.
13. Distributed System
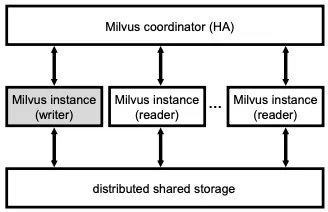
Milvus là một hệ thống phân tán hỗ trợ quản lý dữ liệu qua nhiều node. Kiến trúc tổng thể bao gồm ba lớp:
-
Lớp Điều Phối (Coordinator Layer): Lớp điều phối duy trì siêu dữ liệu như thông tin phân mảnh và cân bằng tải.
-
Lớp Tính Toán (Computing Layer): Được quản lý bởi Kubernetes, lớp này xử lý các yêu cầu của người dùng. Nó có một writer duy nhất để xử lý các thao tác chèn, xóa và cập nhật dữ liệu, và đảm bảo tính nguyên tử với nhật ký ghi trước (WAL). Nó có nhiều reader để xử lý các truy vấn của người dùng, tự động mở rộng dựa trên tải. Dữ liệu được phân mảnh giữa các reader bằng cách băm nhất quán và lưu trữ dữ liệu cục bộ để giảm thiểu việc truy cập thường xuyên vào lớp lưu trữ.
-
Lớp Lưu Trữ (Storage Layer): Lớp lưu trữ chia sẻ sử dụng Amazon S3 để có khả năng sẵn sàng cao.
References
- Milvus: A Purpose-Built Vector Data Management System. In Proceedings of the 2021 International Conference on Management of Data (SIGMOD ‘21). Association for Computing Machinery, New York, NY, USA, 2614–2627.
- Exploring Vector Databases with Milvus.
All rights reserved
