Ưu và nhược điểm của Cassandra
Bài đăng này đã không được cập nhật trong 5 năm
Tại sao nên sử dụng NoSQL
Hiện nay, các dịch vụ trên Internet phải đối mặt với khối lượng thông tin, dữ liệu rất lớn và có mối liên hệ phức tạp với nhau. Hầu hết dữ liệu sẽ được lưu trữ phân tán trên nhiều máy chủ khác nhau để đảm bảo truy cập cho người dùng. Vì vậy, các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS: Relational Database Management System) tỏ ra không còn phù hợp với các dịch vụ như thế này nữa. Người ta bắt đầu nghĩ tới việc phát triển các DBMS (Database Management System) mới phù hợp để quản lí các khối lượng dữ liệu phân tán này và đó chính là NoSQL.
Trong RDBMS, việc lựa chọn hệ quản trị cơ sở dữ liệu là rất dễ dàng bởi vì tất cả các hệ quản trị cơ sở dữ liệu như MySQL, Oracle, MS SQL,.. sử dụng cùng loại giải pháp hướng tới các thuộc tính ACID (Atomicity, Consitency, Isolation, và Durability). Khi sử dụng NoSQL, quyết định trở nên khó khăn vì cơ sở dữ liệu NoSQL cung cấp các giải pháp khác nhau và cần hiểu rõ từng giải pháp để chọn ra giải pháp phù hợp nhất với yêu cầu ứng dụng/ hệ thống của mình.
VD: Nếu dữ liệu của bạn có dạng:
-
Document Databases (ví dụ: MongoDB): Các cơ sở dữ liệu dạng document thường được sử dụng để lưu trữ các JSON document trong các collection và truy vấn các trường liên quan. Có thể sử dụng cơ sở dữ liệu này để xây dựng các ứng dụng không có quá nhiều mối quan hệ giữa các document.
- Ví dụ tốt của dạng ứng dụng này là - Blog Engine / Nếu bạn muốn lưu trữ một danh mục sản phẩm.
-
Graph Databases (ví dụ: Neo4j): Các cơ sở dữ liệu dạng đồ thị (graph) thường được sử dụng để lưu trữ mối quan hệ giữa các thực thể, trong đó các node là các thực thể và cạnh nối là mối quan hệ giữa chúng.
- Ví dụ: nếu bạn đang xây dựng một mạng xã hội và nếu user A follow user B. Thì user A và user B có thể là các node và "follow" là cạnh nối giữa chúng. Đồ thị (graph) là cách tuyệt vời để làm công việc join giữa các node, thậm chí trong trường hợp chiều sâu của liên kết đến 100 cấp.
-
Cache (ví dụ: Redis): Cache thường được sử dụng khi bạn cần truy cập cực nhanh đến dữ liệu của mình.
- Ví dụ, nếu bạn đang xây dựng một ứng dụng thương mại điện tử. Bạn có các danh mục sản phẩm phải load trên mỗi sự kiện page load.
Thay vì việc cứ phải truy cập cơ sở dữ liệu cho mỗi hoạt động đọc đó (cho mỗi lần page load) thường tốn nhiều thời gian, bạn có thể lưu trữ nó trong cache sẽ giúp cho công việc đọc/ghi có tốc độ cực nhanh. Cache giống như Redis sẽ là một bộ đệm cho cơ sở dữ liệu của bạn phục vụ cho những truy xuất dữ liệu thường xuyên. Có thể lưu trữ dữ liệu trong cache và không phải truy xuất cơ sở dữ liệu trong toàn bộ quá trình.
- Ví dụ, nếu bạn đang xây dựng một ứng dụng thương mại điện tử. Bạn có các danh mục sản phẩm phải load trên mỗi sự kiện page load.
-
Search Databases (ví dụ: ElasticSearch): Nếu bạn muốn thực hiện một full text search trên dữ liệu của mình (ví dụ: các sản phẩm trong một ứng dụng thương mại điện tử) thì bạn cần một search database như ElasticSearch, nó có thể giúp bạn thực thi việc tìm kiếm trên một lượng dữ liệu lớn và mang lại cho bạn một tập các đặc trưng thú vị.
-
Row Store (ví dụ: Cassandra): Cassandra thường được sử dụng để lưu trữ dạng dữ liệu theo thời gian như các phân tích / logs/ dữ liệu số lượng lớn được thu về từ các bộ cảm biến sensor. Nếu bạn có một dạng ứng dụng kiểu đó mà có số lượng dữ liệu cần ghi rất lớn và ít phải đọc và dữ liệu là không có mối quan hệ (non-relational) thì Cassandra là một cơ sở dữ liệu mà bạn nên quan tâm tới.
Cassandra là gì?

Cassandra là một cơ sở dữ liệu phân tán kết hợp mô hình dữ liệu của Google Bigtable với thiết kế hệ thống phân tán như bản sao của Amazon Dynamo.
-
Tháng 7/2008: Cassandra được tạo ra bởi Facebook để giải quyết các vấn đề về cơ sở dữ liệu của chính nó, sau đó được chuyển qua cho cộng đồng mã nguồn mở.
-
Tháng 3/2009: Cassandra trở thành dự án phát triển của Apache.
-
Ngày 17/2/2010: Apache đưa Cassandra trở thành dự án hàng đầu của mình.
Sau hơn 10 năm phát triển, Cassandra trở thành một trong những hệ quản trị hàng đầu được rất nhiều tổ chức sử dụng.
Một số tổ chức sử dụng Cassandra làm hệ quản trị cơ sở dữ liệu

Ưu điểm của Cassandra
1, Mã nguồn mở
Cassandra là dự án mã nguồn mở của Apache, điều này có nghĩa là nó hoàn toàn miễn phí. Bạn có thể tải ứng dụng và sử dụng theo cách bạn muốn. Vì là mã nguồn mở nên nó tạo ra một cộng đồng sử dụng lớn để mọi người chia sẻ kinh nghiệm, kiến thức và gợi ý của họ liên quan đến Big Data. Hơn nữa Cassandra có thể tích hợp với các dự án mã nguồn mở Apache khác như Hadoop, Apache Pig và Apache Hive.
2, Kiến trúc ngang hàng (Peer to peer)
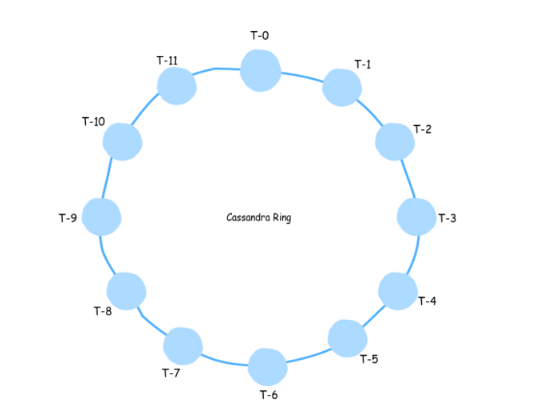
Cassandra theo một kiến trúc ngang hàng, thay vì kiến trúc client/ server. Các node trong cassandra có vai trò tương tự nhau, đều đảm nhận việc đọc ghi dữ liệu, làm giảm nguy cơ bị bottlenect (thắt cổ chai). Do đó, không có bất cứ điểm chết nào. Hơn nữa, bất kỳ số lượng máy chủ/nút nào cũng có thể thêm vào bất kỳ cụm Cassandra nào trong bất kì data center nào. Chắc chắn, với kiến trúc mạnh mẽ và đặc điểm đặc biệt của nó, Cassandra đã nâng cao hơn nhiều so với các cơ sở dữ liệu khác.
Các node giao tiếp với nhau bằng giao tiếp Gossip - Gossip là một giao thức dùng để cập nhật thông tin về trạng thái của các node khác đang tham gia vào cluster. Đây là một giao thức liên lạc dạng peer-to-peer trong đó mỗi node trao đổi định kỳ thông tin trạng thái của chúng với các node khác mà chúng có liên kết. Tiến trình gossip chạy mỗi giây và trao đổi thông tin với nhiều nhất là ba node khác trong cluster. Các node trao đổi thông tin về chính chúng và cả thông tin với các node mà chúng đã trao đổi, bằng cách này toàn bộ những node có thể nhanh chóng hiểu được trạng thái của tất cả các node còn lại trong cluster. Một gói tin gossip bao gồm cả version đi kèm với nó, như thế trong mỗi lần trao đổi gossip, các thông tin cũ sẽ bị ghi đè bởi thông tin mới nhất ở một số node.
Số lượng các hãng sử dụng NoSQL ngày một tăng và Cassandra cũng ngày càng được sử dụng rộng rãi. Các hãng nổi tiếng như NetFlix, eBay, Reddit, Ooyala sử dụng Cassandra để làm tăng thêm hiệu quả cấu trúc của họ.
Một hệ thống Cassandra lớn nhất được biết đến là hệ thống chứa đựng 300TB data trải dài trên 400 máy riêng biệt.
Bởi vì khả năng xử lý tốt khối dữ liệu lớn nên nó được sử dụng cho nhiều ứng dụng khác nhau, từ những ứng dụng phù hợp về tốc độ xử lý, đến việc kết hợp các công nghệ khác trong việc xử lý thời gian thực của BigData.
3, Khả năng mở rộng đàn hồi
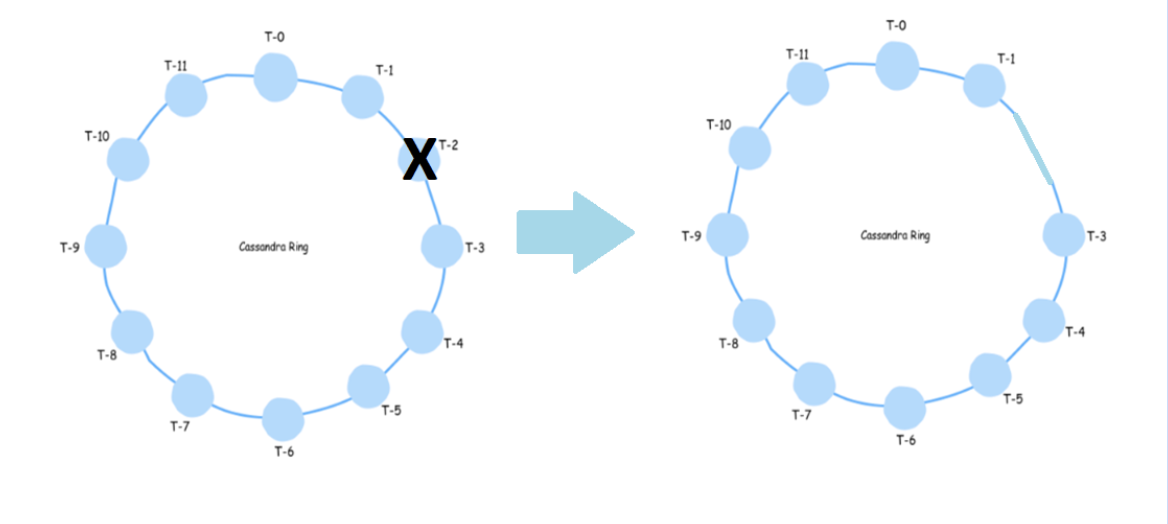
Một trong những lợi thế khi sử dụng Cassandra là khả năng mở rộng đàn hồi của nó. Cụm Cassandra có thể dễ dàng thu nhỏ hoặc mở rộng. Bất kỳ số lượng các nút có thể được thêm vào hoặc xóa đi trong cụm Cassandra mà không gây ra xáo trộn nào. Bạn không cần phải khởi động lại cụm hoặc thay đổi truy vấn liên quan tới ứng dụng Cassandra trong khi mở rộng hoặc thu nhỏ. Khi mở rộng quy mô đọc và ghi thông lượng đều tăng đồng thời với thời gian ngưng hoạt động bằng 0 hoặc bất kỳ tạm dừng nào với ứng dụng.
4, Highly Availbility và Fault Tolerance
-
Một tính năng nổi bật khác của Cassandra là sao chép dữ liệu khiến cho Cassandra có khả năng chịu lỗi cao. Sao chép có nghĩa là mỗi dữ liệu được lưu trữ tại nhiều nơi. Điều này cho phép ngay cả khi một node bị lỗi, người dùng vẫn có thể truy xuất dữ liệu từ một vị trí khác. Trong một cụm Cassandra, mỗi hàng được nhân rộng dựa trên keyspaces. Bạn có thể đặt số lượng bản sao mà bạn muốn. Cũng giống như nhân rộng, sao chép dữ liệu cũng có thể xảy ra trên nhiều data center. Điều này dẫn đến khả năng phục hồi cao ở Cassandra.
-
Khi thực hiện các tác vụ đọc ghi, Cassandra có thể thực hiện trên bản sao gần nhất hoăc trên tất cả các bản sao. Điều này tùy thuộc vào thông số ConsitencyLevel do bạn thiết lập.
5 Hiệu suất cao
Ý tưởng cơ bản đằng sau việc phát triển Cassandra là khai thác khả năng ẩn của một số máy đa lõi. Cassandra đã biến ước mơ này thành sự thật. Cassandra đã chứng minh hiệu suất rực rỡ dưới một lượng lớn dữ liệu. Vì vậy, Cassandra được yêu thích bởi những tổ chức có số lượng dữ liệu lớn và không thể để mất dữ liệu.
Một chút so sánh thú vị giữa Cassandra với MySQL với dữ liệu lớn hơn 50GB:
| Column 1 | thời gian đọc trung bình | thời gian ghi trung bình |
|---|---|---|
| Cassandra | ~300ms | 0.12ms |
| MySQL | ~350ms | 15ms |
Hiệu suất của Cassandra cao hơn các hệ quản trị SQL khi lượng dữ liệu đầu vào lớn hơn 50GB vì nó tận dụng được hết khả năng của các máy đa nhân.
6, Định hướng cột
Cassandra có một mô hình dữ liệu cao - định hướng cột. Có nghĩa là, Cassandra lưu trữ các cột dựa trên các tên cột, dẫn đến việc cắt rất nhanh. Không giống như các cơ sở dữ liệu truyền thống, trong đó tên cột chỉ bao gồm siêu dữ liệu, trong tên cột Cassandra cũng có thể bao gồm dữ liệu thực tế. Vì vậy, các hàng trong Cassandra có thể chứa số lượng cột khác nhau. Mô hình dữ liệu trong Cassandra rất phong phú.
Các RDBMS hướng dòng (row-oriented) phải định nghĩa trước các cột (column) trong các bảng (table). Đối với Cassandra thì chúng ta không phải làm điều đó, thích thêm bao nhiêu cột vào hàng đều được.
7, Tính nhất quán có thể điều chỉnh.
Tính nhất quán của dữ liệu trong các nút có thể được điều chỉnh tùy ý:
- Bản sao dữ liệu được lưu trên tất cả các nút
- Có thể tùy chỉnh được số nút lưu bản sao của dữ liệu
8, Schema-less
Trong Cassandra, các cột có thể được tạ theo ý muốn của bạn trong các hàng. Mô hình dữ liệu Cassandra nổi tiếng được biết là mô hình dữ liệu tùy chọn lược đồ. Ngược lại với cơ sở dữ liệu truyền thống, các hàng có số tập hợp cột có thể khác nhau.
9, Cassandra dễ học và sử dụng
Cassandra sử dụng ngôn ngữ CQL - Cassandra Query Language. Về cơ bản nó là SQL nhưng không có các tính năng nâng cao. Nghe có vẻ đây là một nhược điểm nhưng nó lại là lợi thế lớn của Cassandra. Do sự đơn giản này, nên bạn hoàn toàn có thể làm chủ Cassandra trong thời gian ngắn.
10, Tính phân tán không tập chung ( DISTRIBUTED AND DECENTRALIZED)
Khả năng chia dữ liệu thành nhiều phần đặt trên nhiều nút khác nhau trong khi người dùng vẫn thấy dữ liệu này là một khối thống nhất.
11, Khả năng phân tích
Có 4 phương pháp thực hiện phân tích chính trên Cassandra:
- Tìm kiếm tích hợp dựa trên Solr
- Phân tích hàng loạt tích hợp Hadoop và Cassandra
- Phân tích theo lô bên ngoài được hỗ trợ vơí Hadoop và Cloudera/Hortonworks.
- Spark dựa trên phân tích thời gian thực.
Nhược điểm
- Cassandra không hỗ trợ nhiều cho việc tính toán trên storage, nó không hỗ trợ các hàm sum, group, join, max, min và bất kì hàm nào khác mà developer muốn sử dụng để tính toán dữ liệu khi query.
- Vì là dữ liệu phân tán, dữ liệu được lan truyền trên nhiều máy, nên khi có 1 lỗi trong cơ sở dữ liệu thì lỗi này sẽ lan truyền ra toàn bộ các máy trên hệ thống
Kết luận
Có thể thấy ưu điểm của Cassandra bắt nguồn từ việc nó có thể lưu trữ dữ liệu, tạo bản sao trên nhiều máy. Vây chính xác cơ chế đó là như thế nào.
-
Thiết kế của Cassandra là thiết kế phân tán trên hàng ngàn máy chủ mà không có bất kì điểm tập trung nào. Cassandra có thiết kế dựa trên kiến trúc ngang hàng (Peer to Peer) tất cả các nút máy chủ trong hệ thống đóng vai trò như nhau và không có nút máy nào khi xảy ra sự cố có thật đánh sập được cả hệ thống như kiến trúc Client/Server truyền thống. Các nút má chủ của Cassandra độc lập với nhau và tham gia vào kết nối với các máy chủ khác trong hệ thống.
-
Mỗi nút đều có thể xử lý các thao tác đọc ghi dữ liệu, không phân biệt là dữ liệu được lưu trữ vật lý trên máy chủ nào trong hệ thống. Khi một nút hỏng, máy móc dừng hoạt động thì thao tác sẽ được thực thi trên máy chủ khác.
Bài viết được tham khảo từ nhiều nguồn ^^
All rights reserved
