Unicode Basics: What's Character Set, Character Encoding, UTF-8?
Bài đăng này đã không được cập nhật trong 7 năm
Tạm thời dừng các chủ đề về công nghệ. Nay mình sẽ đi dịch bài viết về Character encoding. Chả là đợt dự án gần đây bọn mình có export dữ liệu trong database ra file *.csv với encoding là Shift-JIS nên tiện thể tìm hiểu về encoding là gì và mình sẽ dịch chia sẻ luôn tới mọi người. Chúng ta cùng đi tìm hiểu nhé.
Bộ ký tự (character set) là gì?
Bộ ký tự (character set) là tập hợp các ký tự cố định. Ví dụ: Trong bảng chữ cái của tiếng Anh thì các ký tự từ "A" đến "Z" và "a" đến "z" có thể là một bộ ký tự với tổng cộng là 52 ký tự (bao gồm 26 ký tự chữ hoa và 26 ký tự chữ thường).
ASCII (American Standard Code for Information Interchange) là một trong những bộ ký tự đơn giản nhất được tiêu chuẩn hóa, nó được bắt đầu từ những năm 1960 và gần như là bộ ký tự được sử dụng duy nhất ở Mỹ cho đến những năm 1990.
ASCII chứa 128 ký hiệu. Trong đó bao gồm tất cả các ký hiệu (chữ cái, chữ số và các dấu chấm câu) mà bạn có thể nhìn thấy trên bàn phím thông thường được bán ở Mỹ. Và ASCII được thiết kế cho những ngôn ngữ chỉ sử dụng những chữ cái trong bảng chữ cái tiếng Anh.
- ASCII không chứa một số ký tự của Châu Âu như: è é å ñ ü.
- ASCII không chứa các ký hiệu như: ™ © ♥ • † ∑ « » →
- ASCII không thể sử dụng cho các ký tự của Trung Quốc, bảng chữ cái Ả Rập, bảng chữ cái tiếng Nga, ...
Bạn có thể xem danh sách đầy đủ của các ký tự ASCII: tại đây
Mã hóa ký tự là gì (character encoding)
Tất cả các tập tin (file) đều phải đi qua công đoạn mã hóa/giải mã để được lưu trữ đúng cách dưới dạng file hoặc khi hiển thị. Máy tính của chúng ta cần phải có một cách để dịch bộ ký tự của ngôn ngữ chúng ta sử dụng sang dạng ngôn ngữ của hệ thống là các số 0 và 1. Quá trình chuyển đổi này được gọi là Mã hóa ký tự.
Chúng ta có rất nhiều hệ thống mã hóa. Các hệ thống mã hóa được sử dụng phổ biến nhất hiện nay là:
- ASCII cho tiếng Anh. Được sử dụng rộng rãi trước những năm 2000.
- UTF-8 Unicode (được sử dụng mặc định trong Linux và hầu hết các dữ liệu trên Internet).
- UTF-16 Unicode (được sử dụng trong hệ thống tập tin bởi Microsoft Windows và Mac OSX, trong ngôn ngữ Java, ...)
- GB 18030 (được sử dụng ở Trung Quốc, chứa tất cả các ký tự Unicode)
- EUC (Extended Unix Code). Được sử dụng ở Nhật Bản
- Các series IEC 8859 (được sử dụng cho hầu hết các ngôn ngữ ở Châu Âu)
Bộ ký tự và Hệ thống mã hóa
Bộ ký tự (character set) và Hệ thống mã hóa (Encoding system) là các khái niệm khác nhau nhưng thường bị nhầm lẫn với nhau.
- Bộ ký tự (Character set): Là một bộ các ký tự đã được tiêu chuẩn hóa
- Hệ thống mã hóa (Encoding system): Là một tiêu chuẩn cho một cách thức mã hóa một chuỗi ký tự (của một bộ ký tự đã cho trước) thành chuỗi ngôn ngữ máy 0 và 1.
Trong những ngày đầu của máy tính thì hai khái niệm này không được phân biệt rõ ràng và chúng chỉ được gọi là một bộ ký tự hoặc hệ thống mã hóa. Dưới đây là một ví dụ cho sự nhầm lần này:
<meta http-equiv="Content-Type" content="text/html;charset=utf-8">
Trong cú pháp có chứa từ "charset", nhưng nó thực sự lại là về mã hóa (encoding) chứ không phải bộ ký tự (charset). Bạn có thể xem thêm tại HTML: Character Sets and Encoding.
Một tiêu chuẩn của mã hóa là sự định nghĩa của một bộ ký tự. Vì nó cần phải xác định những ký nó được thiết kế ra để xử lý.
Bộ ký tự và hệ thống mã hóa của Unicode
Unicode là một tiêu chuẩn được tạo bởi Unicode Consortium vào năm 1991. Và nó chủ yếu định nghĩa cho hai thứ:
- Là một bộ ký tự (bao gồm các ký tự cần thiết cho tất cả các ngôn ngữ trên thế giới)
- Là một số hệ thống mã hóa (phổ biến nhất là UTF-8, UTF-16)
Bộ ký tự Unicode
Bộ ký tự Unicode bao gồm tất cả các ký tự viết bằng ngôn ngữ của con người. Nó bao gồm hàng chục ngàn ký tự của Trung Quốc, các ký hiệu toán học cũng như các ký tự đã chết (không được sử dụng nữa) như các chữ tượng hình Ai Cập và các biểu tượng cảm xúc (hay còn được gọi là "emoji" - xem thêm Unicode Emoji 😄)
Điểm mã (code point)
Mỗi ký tự trong Unicode được cấp một mã định danh (ID) duy nhất. ID này là một số nguyên, bắt đầu từ 0 và được gọi là điểm mã của ký tự. Để dễ hình dung, bạn có thể hiểu rằng "điểm mã" (code point) là một mã định danh của một ký tự chứ không phải là ID của một ký tự, bởi vì một số ký tự không thực sự là một ký tự như là dấu cách (space), dấu trở về (return \r), dấu tab (\t), ...
Điểm mã được biểu diễn theo dạng thập phân (Decimal) hay thập lục phân (Hexadecimal). Ví dụ ký tự α:
- Tên: GREEK SMALL LETTER ALPHA
- Điểm mã biểu diễn ở dạng thập phân: 945
- Điểm mã biểu diễn ở dạng thập lục phân: 3B1
- Ký hiệu chuẩn: U+3B1
Tên ký tự
Là một tên duy nhất được gán cho từng ký tự Unicode. Tuy nhiên, đôi khi một ký tự Unicode có nhiều hơn một tên (một hoặc nhiều tên cũ) do sự thay đổi tên của ký tự trong những ngày đầu của Unicode phiên bản 2 vào năm 1996. Ví dụ:
- A (U+41): LATIN CAPITAL LETTER A
- α (U+3B1): GREEK SMALL LETTER ALPHA
- Ж (U+416): CYRILLIC CAPITAL LETTER ZHE
- → (U+2192): RIGHTWARDS ARROW
- ♥ (U+2665): BLACK HEART SUIT
- ¥ (U+A5): YEN SIGN
- ✂ (U+2702): BLACK SCISSORS
- 😂 (U+1F602): FACE WITH TEARS OF JOY
Hệ thống mã hóa Unicode: UTF-8, UTF-16, ...
Sau cùng, Unicode định nghĩa một số hệ thống mã hóa. UTF-8 và UTF-16 là hai hệ thống mã hóa phổ biến. Mỗi hệ thống có những ưu và nhược điểm riêng như:
- UTF-8 phù hợp cho các văn bản chủ yếu là chữ cái tiếng Anh. Ví dụ như: tiếng Anh, tiếng Tây Ban Nha, tiếng Pháp và hầu hết các công nghệ Web như HTML, JavaScript hay CSS. Mặc định trong hệ thống của Linux thì hầu hết các tập tin là UTF-8. UTF-8 tương thích ngược với ASCII (nghĩa là nếu một tập tin chỉ chứa các ký tự ASCII thì khi mã hóa tập tin bằng UTF-8 sẽ tạo ra cùng một chuỗi các byte như đang sử dụng ASCII)
- UTF-16 là một hệ thống mã hóa khác của Unicode. Với UTF-16 thì tất cả các ký tự sẽ được mã hóa thành ít nhất 2 byte. Đối với các ngôn ngữ Châu Á chứa nhiều ký tự Trung Quốc như tiếng Trung và tiếng Nhật thì UTF-16 sẽ tạo ra tập tin có kích thước nhỏ hơn. Ngoài ra còn UTF-32 luôn luôn sử dụng 4 byte cho mỗi ký tự. Nó tạo ra tập tin có kích thước lớn hơn, nhưng lại dễ để phân tích hơn. Hiện tại thì UTF-32 không được sử dụng nhiều nữa.
Giải mã (Decoding)
Khi một trình chỉnh sửa (editor) mở một tập tin, nó cần được biết rằng tập tin này sử dụng hệ thống mã hóa nào để giải mã và ánh xạ nó vào các phông chữ để hiện thị các ký tự gốc được chính xác. Nói chung là thông tin về hệ thống mã hóa được sử dụng trong tập tin không đi chung với tập tin.
Trước khi có internet thì không có nhiều vấn đề bởi vì hầu hết các quốc gia nói tiếng Anh sử dụng ASCII, còn các khu vực không sử dụng tiếng Anh thì sử dụng các chương trình mã hóa đặc biệt cho khu vực của họ.
Khi bắt đầu có internet. Các tập tin với các ngôn ngữ khác nhau bắt đầu được trao đổi qua lại nhiều lên thì khi chúng ta mở một tập tin, các ứng dụng trên Windows sẽ thử phỏng đoán hệ thống mã hóa được sử dụng trong tập tin bằng một số chuẩn đoán có sẵn. Và khi mở một tập tin với bộ mã hóa không chính xác thì kết quả hiển thị sẽ trở nên vô nghĩa (không thể đọc được). Và thông thường thì chúng ta sẽ nói rõ cho ứng dụng đó rằng tập tin này sử dụng bộ mã hóa nào (như với Firefox, chúng ta có thể truy cập menu này tại View -> Text Encoding). Tương tự với khi mở tập tin, khi chúng ta lưu tập tin thường sẽ có tùy chọn để bạn có thể chỉ định bộ mã hóa nào sẽ sử dụng. Ví dụ như Notepad của Windows, khi bạn lưu một tập tin, sẽ có tùy chọn "Encoding" ở hộp thoại Save.
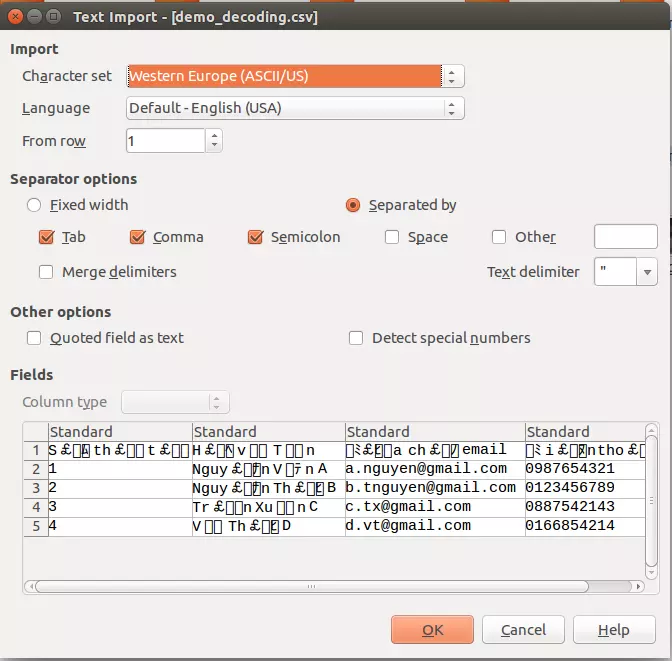
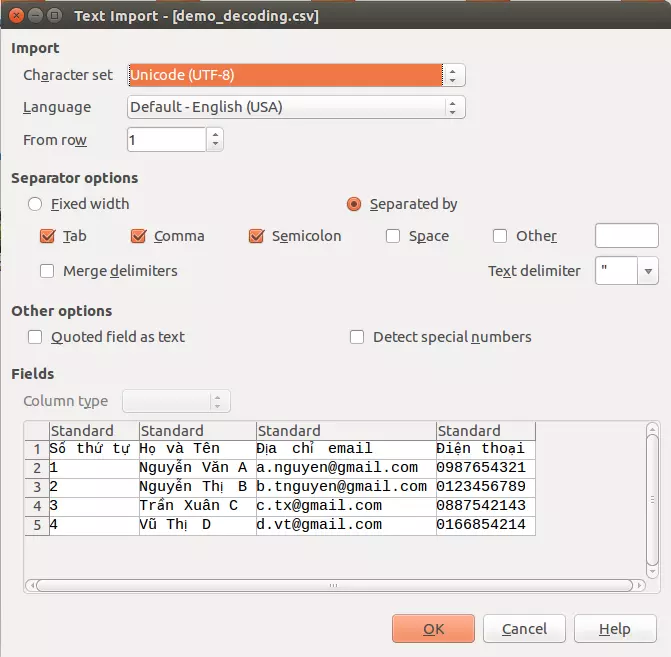
Phông chữ (Font)
Khi máy tính giải mã một tập tin, sau đó hiển thị các ký tự dưới dạng tượng hình lên màn hình thì bộ tượng hình này được gọi là phông chữ (font), và máy tính cần phải ánh xạ các điểm mã Unicode tới các hình tượng trong phông chữ đó. Đối với các ngôn ngữ của Châu Á như tiếng Trung, tiếng Nhật, tiếng Hàn hay các ngôn ngữ sử dụng bảng chữ cái tiếng Ả Rập làm hệ thống chữ viết thì bạn cần phải có một phông chữ thích hợp để hiển thị tập tin được chính xác.
Phương pháp nhập (Input method)
Đối với các ngôn ngữ không dựa trên bảng chữ cái chẳng hạn như tiếng Trung thì chúng ta cần phải có một cách để gõ chúng. Cách đó được gọi chung là "hệ thống đầu vào (input system)" hay "phương pháp nhập (input method)". Bạn có thể xem thêm tại:
Lời kết
Vâng, đến đây là kết thúc bài dịch về Unicode basics. Qua bài này, hy vọng sẽ giúp mọi người có cái nhìn rõ hơn về encoding, character set hay UTF-8 (seeyou) !
!
- Nguồn bài viết: http://ergoemacs.org/emacs/unicode_basics.html
All rights reserved
