Understand Nodejs
Bài đăng này đã không được cập nhật trong 4 năm
Nodejs hiện nay đang rất nổi như một xu thế công nghệ mới. Với sự mạnh mẽ, cấu trúc khác biệt nên Nodejs đã tạo nên một cơn sốt thời gian qua: nhanh, tốn ít tài nguyên, đáp ứng được lượng request lớn. Đặc biệt nó đáp ứng được tính realtime của ứng dụng. Mình là một người khá tò mò và thích khám phá điều mới lạ. Lúc đầu đọc qua tài liệu và ví dụ với các cụm từ event-driven, non-blocking, asynchonous, single thread... mình bị choáng. Vì các khái niệm này quá trìu tượng và khó hiểu. Đó là động lực giúp mình đi tìm câu trả lời? Điêu gì tạo nên sức mạnh của Node.js.
Nodejs là gì?
Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient.
Như vậy Node.js là Javascript thực thi, được xây dựng trên Chrome's V8 Javascript engine. Nó sử dụng mô hình event-driven, non-blocking I/O nên rất nhẹ và cực kì hiệu quả. Câu hỏi đặt ra là: vậy event-driven là gì? non-blocking I/O là như thé nào? Asynchonous là gi? Tại sao nó lại tốt hơn so với các web server, ngôn ngữ lập trình trước đây? Để làm rõ điều này chúng ta đi sâu hơn về cấu trúc của HDH và hệ thống tập tin, cũng như các thư viện tích hợp trong Node.js
Bây giờ, trước khi bắt đầu quyết định xem có nên block hoặc non block I/O hay không, có lẽ ta nên xem lại khái niệm về I/O một lần.
I/O
I/O là quá trình giao tiếp (lấy dữ liệu vào, trả dữ liệu ra) giữa một hệ thống thông tin và môi trường bên ngoài. Với CPU, thậm chí mọi giao tiếp dữ liệu với bên ngoài cấu trúc chip như việc nhập/ xuất dữ liệu với memory (RAM) cũng là tác vụ I/O. Trong kiến trúc máy tính, sự kết hợp giữa CPU và bộ nhớ chính (main memory – RAM) được coi là bộ não của máy tính, mọi thao tác truyền dữ liệu với bộ đôi CPU/Memory, ví dụ đọc ghi dữ liệu từ ổ cứng đều được coi là tác vụ I/O.
Do các thành phần bên trong kiến trúc phụ thuộc vào dữ liệu từ các thành phần khác, mà tốc độ giữa các thành phần này là khác nhau, khi một thành phần hoạt động không theo kịp thành phần khác, khiến thành phần khác phải rảnh rỗi vì không có dữ liệu làm việc, thành phần chậm chạp kia trở thành một bottle-neck, kéo lùi hiệu năng của toàn bộ hệ thống.
Dựa theo các thành phần của kiến trúc máy tính hiện đại, tốc độ thực hiện tiến trình phụ thuộc:
CPU Bound: Tốc độ thực hiện tiến trình bị giới hạn bởi tốc độ xử lý của CPUMemory Bound: Tốc độ thực hiện tiến trình bị giới hạn bởi dung lượng khả dụng và tốc độ truy cập của bộ nhớCache Bound: Tốc độ thực hiện tiến trình bị giới hạn bởi số lượng ô nhớ và tốc độ của các thanh cache khả dụngI/O Bound: Tốc độ thực hiện tiến trình bị giới hạn bởi tốc độ của các tác vụ IO
Do tốc độ I/O thường rất chậm so với các thành phần còn lại, bottle-neck thường xuyên xảy ra ở đây. Người ta thường xét đến I/O Bound và CPU Bound, cố gắng đưa các process bị giới hạn bởi I/O bound về CPU bound để tận dụng tối đa hiệu năng.
File trong Unix
Chắc hẳn bạn đã nghe On a UNIX system, Everything is a file, (Thật ra còn có vế sau: If something is not a file, it is a process, hoặc theo như Linux Torvalds - Everything is a file descriptor or a process). Mọi I/O device cũng được coi, và có thể được đối xử như là một file trong Unix filesystem. Điều này tạo ra một abtraction cho các thiết bị I/O, che dấu bản chất thật sự của các thiết bị này, kernel chỉ biết giao tiếp với file chứ không cần thiết phải nhận biết có cách hành xử riêng cho từng thiết bị.
Các hành động open, read, write trên file chính là các I/O operation. Khi open() hay create() một file, kernel sẽ tạo ra một cấu trúc file description lưu trong file table và trả lại một số nguyên chứa referent đến file description tương ứng trong bảng.
Mỗi process sẽ lưu một danh sách các file descriptor – các file mà process ấy đang sở hữu, mọi thao tác với file sẽ được thực hiện thông qua một system call với đối số là file descriptor, nghĩa là process ở user mode nhờ kernel thao tác lên một file mà nó sở hữu. Việc này để đảm bảm rằng chỉ kernel mới có quyền tác động đến hệ thống theo một cách an toàn, chương trình chỉ có thể nhờ kernel đại diện thực hiện hành động.
Trong Unix, có thể chia file thành 2 nhóm: Fast và slow file. Đừng để cái tên Nhanh và Chậm làm bạn nhầm lẫn rằng nó đề cập đến tốc độ đọc ghi thực tế với file, điều cần quan tâm đến ở đây là khả năng dự đoán của nó. Các file có thể đáp ứng yêu cầu đọc/ghi của user trong một khoảng thời gian dự đoán được là Nhanh, những file có thể cần đến vô hạn thời gian để đáp ứng lại use call, là Chậm.
Ví dụ, khi đọc dữ liệu từ ổ cứng, kernel biết rằng dữ liệu ở đó, nó chỉ cần một thời gian hữu hạn để lấy dữ liệu và trả về cho user, vậy nên việc đọc một regular file là Nhanh. Việc đọc từ một Pipe hoặc Socket, kernel không thể nào biết được khi nào thì trên file đó có dữ liệu, đồng nghĩa Pipe hay Socket là Chậm.
| #File Type | #Category |
|---|---|
| Block Device | Fast |
| Pipe | Slow |
| Socket | Slow |
| Regular | Fast |
| Directory | Fast |
| Character Device | Varies |
Khi một process cần lấy dữ liệu từ file, trong user mode, nó gọi system call read() trên một file đã mở, kernel đón nhận lời gọi này và thao tác đọc file trong kernel mode rồi trả data (block of bytes) đọc được về user mode để process xử lý.
Nếu là fast file, kernel đi lấy data ở nơi nó đã biết và trả lại user hoặc thông báo lỗi nếu xảy ra ngoại lệ (vd không xác định được vị trí file).
Với slow file, kernel sẽ trả lại bất kỳ dữ liệu sẵn có trên file thậm chí chẳng cần bắt gặp ký tự EOF (End Of File). Nếu trên file chưa có dữ liệu, kernel chỉ đơn giản là block process (với chế độ mặc định), chuyển nó vào chế độ ngủ và đánh thức nó dậy khi dữ liệu đã sẵn sàng.
Điều này là hoàn toàn hợp lý vì thông thường khi lập trình viên đọc một file, anh ta kỳ vọng một dữ liệu cần thiết cho xử lý tiếp theo trong chương trình. Đấy chính là cái mà người ta thường gọi là Bloking I/O.
Trên thực tế, sẽ có những lúc ta muốn process của mình làm một cái gì đấy khác hơn là lăn ra ngủ, kể cả khi I/O operation không thể hoàn thành ngay lập tức. Bằng việc sử dụng fcntl() interface get flag O_NONBLOCK file descriptor cụ thể, ta có thể chuyển I/O model của file sang Nonblocking I/O.
Khi ấy, nếu một operation không thể thực hiện ngay lập tức, hàm gọi sẽ trả về EAGAIN (“TRy it again”). Cờ O_NONBLOCK không có tác dụng với các fast file như regular file, directory file.
Blocking I/O vs Nonblocking I/O
Blocking I/O
Yêu cầu thực thi một IO operation, sau khi hoàn thành thì trả kết quả lại. Pocess/Theard gọi bị block cho đến khi có kết quả trả về hoặc xảy ra ngoại lệ.
Nonblocking I/O
Yêu cầu thực thi IO operation và trả về ngay lập tức (timeout = 0). Nếu operation chưa sẵn sàng để thực hiện thì thử lại sau. Tương đương với kiểm tra IO operatio có sẵn sàng ngay hay không, nếu có thì thực hiện và trả về, nếu không thì thông báo thử lại sau.
Synchronous vs Asynchronous
Synchronous
Hiểu đơn giản: Diễn ra theo thứ tự. Một hành động chỉ được bắt đầu khi hành động trước kết thúc.
Asynchronous
Không theo thứ tự, các hành động có thể xảy ra đồng thời hoặc chí ít, mặc dù các hành động bắt đầu theo thứ tự nhưng kết thúc thì không. Một hành động có thể bắt đầu (và thậm chí kết thúc) trước khi hành động trước đó hoàn thành.
Sau khi gọi hành động A, ta không trông chờ kết quả ngay mà chuyển sang bắt đầu hành động B. Hành động A sẽ hoàn thành vào một thời điểm trong tương lai, khi ấy, ta có thể quay lại xem xét kết quả của A hoặc không. Trong trường hợp quan tâm đến kết quả của A, ta cần một sự kiện Asynchronous Notification thông báo rằng A đã hoàn thành.
Vì thời điểm xảy ra sự kiện hành động A hoàn thành là không thể xác định, việc bỏ dở công việc đang thực hiện để chuyển sang xem xét và xử lý kết quả của A gây ra sự thay đổi luồng xử lý của chương trình một cách không thể dự đoán. Luồng của chương trình khi ấy không tuần tự nữa mà phụ thuộc vào các sự kiện xảy ra. Mô hình như vậy gọi là Event-Driven.
Asynchronous – Event-Driven
Asynchronous và Event-Driven không phải là một điều gì quá mới mẻ. Thực tế nó đã tồn tại trong ngành khoa học máy tính từ những ngày đầu. Cơ chế ngắt (Interrupt) là một signal thông báo cho hệ thống biết có một event vừa xảy ra.
Khi ngắt xảy ra, hệ thống buộc phải dừng chương trình đang chạy để ưu tiên chạy một chương trình khác gọi là Chương Trình Phục Vụ Ngắt (Interrupt Service Routine) rồi mới quay trở lại thực hiện tiếp chương trình đang chạy dở.
Có hai loại ngắt: Ngắt Cứng và Mgắt Mềm. Ngắt mềm được gọi bằng một lệnh trong ngôn ngữ máy. Ngắt cứng thì chỉ có thể được gọi do các linh kiện điện tử tác động lên hệ thống.
Một ví dụ về ngắt cứng là khi card mạng nhận được data từ bên ngoài. Card mạng gửi tín hiệu điện lên chân ngắt của CPU, cờ ngắt (INT) trên resigter được kích hoạt. CPU dừng lại, kiểm tra mức độ ưu tiên (tất nhiên không phải thằng nào xin ngắt cũng cho ngắt, biết đâu việc mình đang thực hiện quan trọng hơn), kiểm tra tín hiệu ngắt là gì, từ tín hiệu ngắt mà lấy được địa chỉ của chương trình phục vụ ngắt (chính là driver của device).
Drive sẽ quyết định ghi dữ liệu vào một file trên Unix Virtual File System, ở đây là vào một socket file. Việc thao tác với divice (đọc dữ liệu từ bàn phím, ghi dữ liệu ra màn hình) thực tế được quyết định bởi device và kernel. Trên góc nhìn của user, device nào thì cũng chỉ là một file đọc được, ghi được, chẳng có gì khác nhau và cũng chẳng khác gì các regular file.
Một đối tượng ví dụ tiêu biểu cho slow file là socket.
Sau khi một socket được tạo (đại diện bởi một file desciptor) và lắng nghe trên một cổng, một yêu cầu xin kết nối được gửi từ client tới và được accept() để thiết lập connection (Một file khác được tạo ra, clone từ file socket cũ kết hợp thêm cổng và địa chỉ của client. Mỗi connection tới server sẽ có một file descriptor riêng).
Sytem call recv() được gọi để sẵn sàng đón nhận message từ client, dưới góc nhìn của kernel là đọc dữ liệu từ file socket, hành động mà sẽ return -1 nếu chưa nhận được message từ client (Và với TCP socket, return 0 nếu connection đã bị ngắt bởi một phía). Nếu trong chế độ synchronous theo mặc định, process sẽ sleep cho tới khi phép đọc sẵn sàng để thực hiện. Trong thời điểm này, nếu một client khác gửi yêu cầu đến server, server của bạn sẽ không thể thực hiện yêu cầu của client ngay được, thậm chí server còn không biết đến sự tồn tại của yêu cầu ấy.
Asychronous trong NodeJS
Quay trở lại với NodeJS, đằng sau cánh gà, thứ mang lại cơ chế Asychronous Event-Driven Non-Blocking I/O là libuv – một thư viện multi-platform hỗ trợ asynchronous I/O. Thứ trong folder deps/uv trên Github repo của NodeJS chính là repo của libuv.
Đây là các strategy của libuv cho mỗi loại I/O để có thể thực hiện asynchronous:
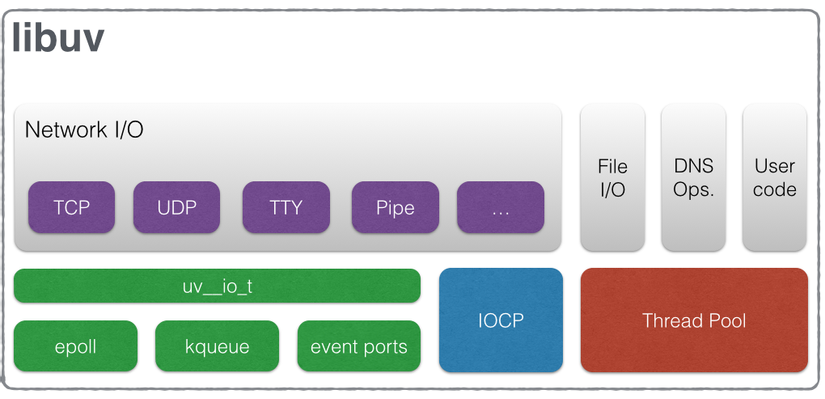 Các feature của Libuv
Các feature của Libuv
-
Full-featured event loop backed by epoll, kqueue, IOCP, event ports.
-
Asynchronous TCP and UDP sockets
-
Asynchronous DNS resolution
-
Asynchronous file and file system operations
-
File system events
-
ANSI escape code controlled TTY
-
IPC with socket sharing, using Unix domain sockets or named pipes (Windows)
-
Child processes
-
Thread pool
-
Signal handling
-
High resolution clock
-
Threading and synchronization primitives
Thread Pool
Cách truyền thống là dùng multithreading. Khi gọi một I/O operation, thread chính bỏ đi và tiếp tục thực hiện lệnh khác, việc halder operation này được giao cho một worker thread hoặc một child process (Xin đừng, process là rất tốn kém tài nguyên hệ thống). Sau khi operation này hoàn thành trong worker thread, worker thread thông báo lại cho main thread.
Vấn đề là ở đây:
- Sinh thread tiêu tốn tài nguyên để tạo mới và cần bộ nhớ cho stack của riêng nó (Như Linux là tối thiểu 2MB mỗi thread by default)
- Các vấn đề thread-safety như deadlock (do các thread chia sẻ tài nguyên), racing conditions, mutex,…
- Tiêu tốn tài nguyên cho thread context switching, scheduler của kernel cần làm việc nhiều hơn
- Worker thread là I/O bound
Những ngoằng loằng trong việc khởi tạo thread có thể được giảm bớt bằng cách sử dụng
Thread Pool. Trong mô hình cổ điển, với ví dụ về socket, các webserver cũ thường cho phép tạo 1process/threadcho mỗiincoming request. Bằng cách ấy,main threadvẫn có thể lắng nghe vàacept()các yêu cầu kết nối mới, trong khi worker thread vẫn có thể chờrecv()từ client đã kết nối một cách đồng thời (đồng thời một cách tương đối).
Tất nhiên, có những cách hiệu quả hơn việc sử dụng Thread Pool. Cùng nhìn lại mô hình của libuv, nó chỉ sử dụng thread poll choregular file I/O (Tất nhiên, vì regular file là fast file và không có chế độ nonblocking), DNS lookup và user code. Còn với các Network I/O như TCP, UDP, TTY, Pipe,… nó sử dụng nonblocking call kết hợp với một cơ chế thông báo khi nào channel sẵn sàng thực hiện I/O operation.
Các cơ chế thông báo này được từng hệ điều hành cung cấp. Khi được thông báo rằng channel đã sẵn sàng, operation được gọi lại và lấy về dữ liệu (nếu dữ liệu vẫn còn sẵn sàng trên channel).
Trong cơ chế blocking I/O, khi process thực hiện một I/O operation chưa sẵn sàng và bị đẩy vào chế độ sleep, nó đăng ký bản thân vào một hàng đợi gọi là wait queue trên file ấy. Khi một file đã sẵn sàng để đọc và ghi (điều này thường do driver của file ấy quyết định), tất cả process đang chờ sự thay đổi của file trong wait queue của event tương ứng được đánh thức.
Nonblocking I/O thì khác, hành động thử đọc/ghi dữ liệu lên file được gọi là polling (thăm dò). Nếu không có cơ chế thông báo thời điểm file operation sẵn sàng để thực hiện, chương trình của bạn sẽ phải liên tục polling một file trong một vòng lặp vô hạn cho tới khi thành công.
Quay trở lại với ví dụ về socket, mỗi connected client sẽ sinh ra mộtconnection file, chương trình cần giám sát tất cả các file này để nhận thông tin khi có imcoming request, đồng thời phải giám sát file socket gốc cho client mới. Bài toán ở đây là giám sát khả năng thực hiện đọc/ghi trên một lượng lớn các slow file khác nhau.
Unix cung cấp cơ chế I/O Multiplexing cho phép đồng thời theo dõi nhiều file descriptor để xem có thể thực hiện I/O operation nào đó trên bất kỳ file nào mà không bị hay không. Một lời gọi giám sát có thể block process gọi nó cho tới khi có bất kỳ một file nào sẵn sàng.
I/O Multiplexing
Ba system call có thể thực hiện I/O Multiplexing là select(), poll() và epoll(). Cả 3 lời gọi này đều cần đến sự hỗ trợ của device driver được cung cấp qua phương thức poll (Lưu ý rằng đây là một file operation, nó khác với system call poll cho I/O multiplexing ở trên). Phương thức này, về cơ bản sẽ đăng ký vào một hoặc nhiều wait queue của file để lắng nghe sự thay đổi trên file, đồng thời trả về một bit mask biểu diễn tất cả những operation có thể thực hiện ngay lập tức với file mà không bị block.
Select System Call
Đây là lời gọi của select:
select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *errorfds, struct timeval *timeout);
Các pointer readfds và writefds có kiểu dữ liệu là fd_set – file descriptor set, chứa danh sách của các file descriptor mà ta quan tâm đến khả năng đọc (readfds) và các file descriptor ta quan tâm đến khả năng ghi (wtireds). fd_set type được biểu hiện dưới dạng một bit mask, các file descriptor được lưu như là một bit field trong mảng của các số nguyên. Unix cung cấp cho chúng ta 4 macro để làm việc với fd_set:
- FD_ZERO(): Tạo một fd_set rỗng.
- FD_SET(): Thêm một file descriptor vào fd_set
- FD_CLR(): Xoá một file descriptor khỏi fd_set
- FD_ISSET(): Kiểm tra xem một file descriptor có nằm trong fd_set hay không Trước khi bắt đầu select, ta dùng FD_ZERO để tạo các fd_set rỗng, thêm file cần quan tâm vào fd_set qua FD_SET vào truyền nó vào tham số tương ứng trong lời gọi làm. Nếu chỉ quan tâm đến một event, ví dụ readable, ta chỉ cần tạo một fd_set (ví dụ tên là readale_set) và truyền nó vào vị trí cua readfds, còn writefds và errorfds để NULL.
Ở bên trên chúng ta đã biết mỗi process có một danh sách các file descriptor mà nó đang mở, danh sách ấy được đánh số bắt đầu từ 0. Thông thường, mỗi process sẽ có sẵn 3 file descriptor là 0, 1, 2, lần lượt trỏ vào stdin, stdout, stderr.
Mỗi file desciptor này sẽ chỉ đến một file description trong file table – nơi kernel kiểm soát tất cả các file đang mở bởi tất cả process trên hệ thống. Đầu vào nfds của select() sẽ chỉ đến chỉ số file description lớn nhất mà process muốn kiểm tra.
Khi select được gọi, nó sẽ pollling tất cả các file có file descriptor từ 0 đến nfds - 1 trong process. Với mỗi file được poll, select sẽ kiểm tra xem file ấy có nằm trong bất kỳ fd_set nào hay không bằng FD_ISSET. Nếu file ấy có trong readfds mà kết quả polling là việc đọc chưa sẵn sàng, FD_CLR sẽ được dùng để xoá file ấy khỏi fd_set readfds. Tương tự với writefds và errorfds.
Nếu timeout được set bằng 0, select chỉ đơn giản là thử kiểm tra trạng thái sẵn sàng của tất cả các file quan tâm rồi trả về ngay lập tức. Nếu giá trị timeout lớn hơn 0, select sẽ chờ cho đến khi ít nhất một sự kiện được quan tâm trên một file descriptor nào đó là sẵn sàng hoặc hết timeout. Giá trị mặc định của timeout (nếu đối số timeout là NULL) khác nhau trên từng hệ thống nhưng có thể lên tới vài năm.
select return một số nguyên, -1 nếu xảy ra lỗi, 0 nếu timeout và trả về tổng số file descriptor sẵn sàng trên từng fd_set. Nếu 1 file descriptor được quan tâm đến cả hai khả năng đọc và ghi, tức cùng có mặt trong readfds và writefds, nó sẽ được đếm 2 lần.
Một cách không tường minh như một side-effect, select thay đổi các fd_set đầu vào thành các ready set, tức readfds và writefds sau lời gọi select không còn là danh sách của các file descriptor ta cần biết về tính readable hay writeable nữa, mà trở thành danh sách con của danh sách ban đầu, chứa các file descriptor đã sẵn sàng đọc hoặc ghi mà không bị block.
Với kết quả này, nếu trước đó ta có lưu lại một danh sách các file descriptor mà ta quan tâm, vì readfds writefds hiện là các ready set, ta chỉ cần loop qua hết các file descriptor ban đầu, dùng FD_ISSET để kiểm tra xem file descriptor ấy có nằm trong readfds (hoặc writefds) hay không, nếu có thì bắt đầu đọc (ghi) data.
Vì các fd_set đầu vào đã bị thay đổi sau lời gọi select, trước khi bắt đầu lại lời gọi tiếp theo, ta phải khởi tạo lại các fd_set này bằng FD_ZERO và FD_SET.
Một ví dụ nhặt được trên mạng về select:
HTTPS://GITHUB.COM/YANGRUJING/SELECT-POLL-EPOLL/BLOB/MASTER/SELECT/SERVER.C
Poll System Call
Poll cung cấp một chức năng tương tự, thường được khuyến khích sử dụng thay thế cho select. Điểm khác biệt chính giữa 2 phương pháp là cách mà danh sách file desctiptor được quản lý. Với select, ta truyền vào 3 fd_set – các bit mask chứa danh sách của các file desciptor cần quan tâm. Trong poll system call, ta sử dụng một mảng duy nhất để lưu các file muốn theo dõi, được bao bọc bởi một struct gọi là pollfd.
int poll(struct pollfd fds[], nfds_t nfds, int timeout);
Tham số nfds là tổng số phần tử của mảng với kiểu dữ liệu nfds_t là một số nguyên dương. fds là một mảng của các pollfs, cấu trúc mà được định nghĩa như sau:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
}
;
Đây là cấu trúc quan trọng nhất của poll tạo nên sự khác biệt với select. Trước khi gọi poll, ta cần khởi tạo mảng fds. Trong mỗi phần tử pollfd, fdlưu giá trị file descriptor của file cần quan tâm, events lưu bit mask của các event ta quan tâm trên file tương ứng.
Mỗi lần poll được gọi, nó sẽ chạy một vòng lặp từ 0 đến nfds - 1, trong mỗi lần lặp nó sẽ thử polling một file tương ứng trong fds[i].fd, kết hợp kết quả trả về (các operation sẵn sàng để thực hiện ngay lập tức với file ấy mà không bị block) với fds[i].events để cho ra dfs[i].revents – bit mask lưu các operation đã sẵn sàng – trong số các operation mà ta quan tâm trên file.
Tham số timeout, tương tự với select, sẽ xác định blocking behavior của poll system call:
Timeout bằng 0, poll kiểm tra tính sẵn sàng của tất cả các file trong fds một lượt rồi trả về kết quả ngay lập tức. Với timeout khác 0, poll process bị block cho đến khi ít nhất một file descriptor trong fds sẵn sàng cho một hành động nào đó trong requested events tương ứng hoặc hết thời gian chờ. Timeout = -1 tương ứng với thời gian chờ là tối đa. Nhận vào một danh sách fds, sau mỗi lần gọi, poll system call trả về lỗi hoặc tổng số file descriptor đã sẵn sàng cho một operation nào đó. Bất kể file ấy sẵn sàng cho bao nhiêu operation, nó chỉ được đếm một lần trong kết quả trả về.
Cũng ngấm ngầm thay đổi đối số đầu vào chứa danh sách các file descriptor quan tâm nhưng không như select, poll chỉ thay đổi revents trong cấu trúc pollfd. Điều này khiến cho danh sách đầu vào gồm các file và các sự kiện quan tâm tương ứng được bảo toàn, kết quả là ta có thể tái sử dụng fds cho mỗi lần gọi poll system call.
Khi nhận kết quả trả về từ poll system call, để biết trạng thái hiện tại của từng file mà ta quan tâm, việc cần làm là loop qua danh sách fds, kiểm tra revents và thực hiện hành động tương ứng với các operation đã sẵn sàng.
Ví dụ về poll cho socket server:
HTTPS://GITHUB.COM/YANGRUJING/SELECT-POLL-EPOLL/BLOB/MASTER/POLL/SERVER.C
Còn nhớ với select ta phải tạo một mảng lưu file descriptor của các file mà ta quan tâm, rồi dùng FD_ISSETđể kiểm tra xem file ấy đã sẵn sàng cho operation nào không? Với poll, ta không cần phải có riêng một mảng như vật nữa, fds đã đóng luôn vai trò của nó rồi.
So sánh hiệu năng của select và poll
Ưu điểm của poll so với select là thấy rõ:
Trong select, vì các fd_set là value-result, tức vừa là đầu vào vừa là đầu ra, nó bị thay đổi và cần phải khởi tạo lại với mỗi lần gọi, việc sử dụng mảng pollfdcủa poll giúp tránh được điều này.
Hơn thế, vì select kiểm tra tất cả các file process đang mở có file descriptor nhỏ hơn nfds, nếu ta không quan tâm đến tất cả các file đang mở, hành động này có thể gây ra lãng phí, nhất là khi các file cần quan tâm phân bố không đều. Giả dụ ta chỉ cần biết tính readable của 2 file có file descriptor lần lượt là 1 và 1000, hiệu năng của select sẽ là một thảm hoạ so với poll – thứ mà chỉ kiểm tra duy nhất nhưng file mà ta quan tâm.
Một yếu điểm nữa của select so với poll là nó có FD_SETSIZE – giới hạn số lượng các file descriptor có thể theo dõi. Mặc định, giới hạn này là 1024 trên Linux, và đáng buồn là sự thay đổi giới hạn yêu cầu chương trình phải được recompile.
Sự lựa chọn của libuv
Cả select và poll đều không phải là phương pháp được sử dụng trong libuv. Kiến trúc của libuv sử dụng epoll, kqueue và dev/poll cho các hệ điều hành Unix-like.
epoll là system call của Linux, kqueue là system call tương tự trong các hệ đều hành phát triển từ BSD (Một phiên bản của Unix) trong đó có Mac OS X, cuối cùng là dev/poll cho họ Solaris. Tất cả đều được bọc bởi giao diện uv__oi_t. Riêng Windows thì sử dụng IOCP (Mình cũng chẳng biết nó là cái gì nữa).
Các phương pháp này (có lẽ) chia sẻ chung một cơ chế để theo dõi I/O event notification của nhiều file descriptor khác nhau. Hãy cùng lôi epoll ra làm đại diện để nhìn xem điểm khác biệt giữa nó và select, poll system call.
Yếu điểm của select và poll
Vấn đề chung của select và poll khi giám sát một số lượng lớn các file descriptor là:
- Với mỗi lần gọi, select và poll phải kiểm tra (polling) tất cả các file descriptor cần giám sát.
- Với mỗi lần gọi, process phải truyền một cấu trúc dữ liệu (các fd_set hoặc fds – mảng của các pollfd) từ user mode, thông qua systel call vào kernel, kernel polling các file descriptor, lấy kết quả để sửa đổi lại các cấu trúc dữ liệu này trước khi gửi trả lại cho user mode (Khủng khiếp hơn là với select, ta cần tái khởi tạo cấu trúc dữ liệu này trước mỗi lần gọi). Việc copy một đống data qua lại giữa user mode và kernel mode qua system call cũng tiêu tốn tài nguyên hệ thống. Thực tế là kernel và user mode có các stack và heap riêng, dù chúng cùng là các thành phần trong một process.
- Sau mỗi lần gọi, để kiểm tra xem file descriptor nào đã sẵn sàng, chương trình của chúng ta phải duyệt qua và kiểm tra từng phần tử trong danh sách các file descriptor quan tâm. Yếu điểm của select và poll đến từ một hạn chế trong thiết kế của chúng:
Thông thường, chương trình sẽ giám sát liên tục, lặp đi lặp lại cùng một danh sách file descriptor, tuy nhiên kernel không ghi nhớ danh sách này giữa các lần gọi liên tiếp.
Dưới cái nhìn của kernel, danh sách file chỉ tồn tại duy nhất trong duration của một select/poll system call. Có thể trên chương trình của bạn, tức trong user mode, danh sách này được lưu ở đâu đó (một danh sách số nguyên đối với select hoặc danh sách pollfd với poll) để tái sử dụng, nhưng với kernel thì không.
Giải pháp của epoll
Ở trên bàn tay còn lại a.k.a mặt khác, epoll không như vậy. Bắt đầu với epoll là xác định bước vào một long-term relationship.
Trên thực tế, epoll là subsystem của 3 system call khác nhau. Trái tim của epoll subsystem là epoll instance, đại diện bởi một file description và tất nhiên như mọt file, có một số integer file descriptor trỏ đến nó.
Epoll instance, một cách dài lâu và bền chặt, lưu giữ một danh sách các file-descripton-quan-tâm (lại nữa, tần suất xuất hiện của cụm từ này có vẻ hơi nhiều), và còn lưu một danh sách các ready file descriptor (Nhớ chứ? Chính là các file descriptor đã sẵn sàng cho việc đọc hoặc ghi).
Tồn tại như là một file, epoll instance chỉ mất đi khi lỗi hoặc gọi lệnh close(), sống xuyên suốt qua các kernel system call, có thể share giữa các thread/process, và, đoán xem còn gì nữa? Epoll file descriptor, giờ đây là pollable, tức là sẽ có wait queue của riêng mình, sẵn sàng để wake up call tất cả các process đang xếp hàng đứng chờ trong đó. Thậm chí nó có thể được giám sát bởi một system call poll, select hay một epoll khác.
Ok, thú thực là mình không hào hứng với việc epoll lồng epoll lắm, nhưng khả năng share epoll instancenhư là một file giữa các process thì khá hữu ích.
Như chúng ta đã biết (hoặc dành cho các bạn chưa biết), chúng ta có một thủ thuật khá thú vị với multiprocessing trên Unix mang tên pre-fork. Unix process có thể sinh ra child process bằng cách copy toàn bộ context của chính nó thông qua lệnh fork().
Thông thường tài nguyên giữa các process là độc lập, nhưng khi một child process vừa được sinh ra, nó thừa hưởng toàn bộ tài nguyên của cha và chỉ clone dữ liệu sang memory của riêng nó khi nó bắt đầu thay đổi giá trị khác với process cha. Cơ chế này có một cái tên rất dễ liên tưởng là copy-on-write.
Các file mà process cha sở hữu cũng sẽ được process con thừa hưởng. Lợi dụng điều này, ta có thể tạo một epoll theo dõi một socket đang lắng nghe trước, sau đó fork() ra nhiều process con, các process này cùng chia sẻ một epoll instance. Các webserver sử dụng pre-fork để tự động load-balancing ở tầng kernel thông qua process scheduler.
Epoll API được cung cấp qua 3 system call sau:
epoll_create(): Tạo ra một epoll instance và trả về file descriptor trỏ đến nó hoặc return -1 nếu tạo không thành công.epoll_ctl(): Quản lý các danh sách các file descriptor cần theo dõi (Thêm, bớt, sửa các event cần quan tâm).epoll_wait(): Trả lại một số item trong ready list sẵn có. Với cơ chế cũ, tất cả các file cần giám sát được polling mỗi lần hàm selecthoặc poll được gọi. Trong epoll, từng file riêng lẻ được polling mỗi lần nó được thêm hoặc sửa trong danh sách thông qua lệnh epoll_ctl:
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *ev);
Lời gọi này đơn giản return 0 nếu thành công hoặc -1 nếu thất bại. Thất bại có thể xảy ra chẳng hạn như khi thêm một file descriptor mà file ấy đã tồn tại hoặc khi thay đổi các event quan tâm trên một file mà file ấy không nằm trong danh sách. epoll sử dụng một cấu Red-Black Tree để lưu danh sách file, với độ phức tạp là O(log n) cho các hành động thêm bớt sửa xoá.
Đối số epfd là file descriptor của epoll instance tạo ra từ lệnh epoll_create. Đối số fd là file descriptor của file cần giám sát. Đối số op xác định hành động của lệnh epoll_ctl, có thể có các giá trị sau: EPOLL_CTL_ADD, EPOLL_CTL_MOD, EPOLL_CTL_DEL tương ứng với thêm, sửa, xoá phần tử trong danh sách. Đối số cuối cùng là một cấu trúc của riêng epoll subsystem:
struct epoll_event {
uint32_t events; /* epoll events (bit mask) */
epoll_data_t data; /* User data */
};
Trong đó data chứa thông tin giúp ta tìm được file mà ta quan tâm, ví dụ file descriptor và events là bit mask đánh dấu các event ta quan tâm trên file ấy. Một danh sách các epoll_event cũng chính là kết quả quan trọng ta lấy được sau khi gọi epoll_wait().
Epoll_wait System Call
int epoll_wait(int epfd, struct epoll_event *evlist, int maxevents, int timeout);
Tương tự như với poll, epoll sẽ chỉ đơn giản là trả về trạng thái sẵn sàng hiện tại của các file descriptor trong danh sách nếu timeout bằng 0. Khi timeout khác 0 (-1 chẳng hạn), epoll sẽ ngủ và chỉ return khi có ít nhất một file descriptor sẵn sàng cho I/O operation.
Ảo diệu ở đây như sau: Khác với poll và select, như đã nói, quá trình polling một file được thực hiện bằng lệnh epoll_ctl, lệnh này chỉ cần gọi một lần khi khởi tạo epoll instance.
Khi có bất kỳ một file descriptor nào thay đổi trạng thái, nó sẽ kích hoạt wait queue của bản thân và đánh thức epoll instance.
Epoll instance sẽ kiểm tra xem file nào vừa đánh thức nó, các ready operation trên file ấy là gì, nếu operation ấy được quan tâm, nó sẽ thêm một epoll_event vào danh sách các ready event mà nó giữ.
Xong việc, epoll instance lăn ra ngủ tiếp. Khi epoll_wait được gọi (và đây có vẻ là thằng được gọi nhiều nhất, gọi đi gọi lại sau mỗi lần lặp trong một vòng lặp vô hạn), user mode không truyền nhiều dữ liệu cho kernel, có chỉ đơn giản yêu cầu kernel trả về một số lượng epoll_event (<= maxevents) dequeue ra từ danh sách các ready event mà epoll instance nắm giữ (Đồng nghĩa các event đã được user mode biết sẽ được xoá khỏi ready list).
Nếu có nhiều sự thay đổi trên một file giữa các lần gọi epoll_wait, epoll instance tìm thấy file ấy đã tồn tại trong ready list, nó lấy epoll_eventấy ra và thay đổi events bit mask của nó.
Dựa trên một thực tế là tần suất xảy ra các sự kiện và kích thước của ready list thường chỉ là một phần rất nhỏ trên tổng số các file descriptor cần theo dõi, epoll chỉ update readly list mỗi lần có một sự kiện xảy ra chứ không polling rồi update mỗi một lần gọi hàm (mỗi một lần lặp trong một vòng lặp vô hạn, hoặc nói dân dã là rất-rất-nhiều-lần), và epoll trả lại một deady list dưới dạng một danh sách epoll_event, nơi mà từ đó ta có thể có lấy ra được file đã thay đổi trạng thái thông qua epoll_event.data.
Tham số số evlist trong epoll_wait system call là một danh sách chỉ chứa các ready file, việc cần làm là duyệt qua từng phần tử của nó để có hành động đọc, ghi tương ứng mà không cần lội qua tất cả các file quan tâm như 2 cách truyền thống.
Ví dụ về epoll:
https://github.com/yangrujing/select-poll-epoll/blob/master/epoll/server.c
Bằng cách tiếp cận như vậy, epoll đặc biệt hiệu quả hơn select và polltrong việc giám sát hàng ngàn, thậm chí hàng chục ngàn file, nhất là khi số lượng event là thưa thớt so với tổng số file cần giám sát.
Thực tế The C10K problem, vấn đề xảy ra khi một webserver có 10000 lượt truy cập đồng thời luôn là một chủ đề gây đau đầu, epoll kết hợp một process/thread quản lý nhiều connection là cách hiệu quả để đối phó với vấn đề này. Xin được giới thiệu bài article về The 10k problem cho bạn nào chưa đọc, bao ngon bao bổ ích bao thú vị:
http://www.kegel.com/c10k.html
Hai khái niệm nữa cần nhắc đến ở đây, và nếu bạn đã nhìn vào bài article trên thì các bạn cũng đã bắt gặp khái niệm này rồi, đó là Level-Triggered và Edge-Triggered.
Level-Triggered vs Edge-Triggered
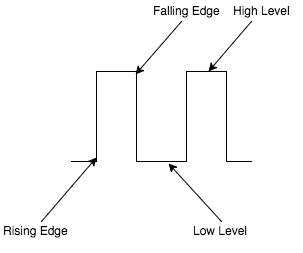
Level-Triggered và Edge-Triggered là hai khái niệm mượn từ đâu thì mình cũng không rõ nữa, chắc từ ngành điện tử, bởi vì hình ảnh một sóng tín hiệu là mô tả tuyệt vời nhất cho các khái niệm này.
Nói cho dễ hiểu thì với mô hình Level-Triggered, ta quan tâm đến trạng thái của đối tượng, miễn là đối tượng còn ở trạng thái ấy thì ta còn quan tâm.
Với Edge-Triggered, cái ta quan tâm là sự thay đổi trạng thái của đối tượng, và nó chỉ thay đổi một lần ở mỗi cạnh-của-trạng-thái: Thay đổi từ thấp lên cao hoặc thay đổi từ cao xuống thấp. Nó là thông báo cho một sự kiện mà ta quan tâm.
Tóm lại:
- Level-Triggered: Quan tâm đến trạng thái
- Edge-Triggered: Quan tâm đến sự kiện
- Edge-Triggered model dựa trên giả định rằng nếu ta đã biết trạng thái của đối tượng thay đổi và đã có biện pháp xử lý rồi, việc tiếp tục thông báo về trạng thái hiện tại ấy là không cần thiết.
Level-Triggered tương tự như một ông bố có trách nhiệm, bỏ giở việc nhà ngồi chơi với con khi nó chán (tiếng khóc thông báo cho ông bố về trạng thái chán đời của con) đến bao giờ nó nín mới thôi. Edge-Triggereddaddy thì quẳng cho nó cái iPad khi thấy nó khóc, rồi kệ đấy tiếp tục rửa bát lau nhà.
Loanh quanh với việc gia đình vậy thôi, trở lại câu chuyện I/O Multiplexingcủa chúng ta. Dễ thấy, với mỗi lần gọi select hoặc poll, hai system call này đều kiểm tra tất cả các file descriptor và trả lại tất cả những trường hợp thoả mãn (ready file). Một file mà có sẵn sàng để đọc từ đầu năm đến cuối năm thì lần nào gọi, select và poll cũng kiểm tra rồi báo lại là file ấy đang sẵn sàng.
Select và poll là hai ông bố có trách nhiệm dù trong ví dụ hiện tại với socket server, ta cần một người thiếu trách nhiệm hơn: epoll.
Xem xét cách thức epoll hoạt động, một epoll_event chỉ được thêm vào ready list khi có một sự kiện xảy ra (epoll instance nhận được thông báo rằng một file đang theo dõi thay đổi trạng thái sẵn sàng).
Sau lời gọi epoll_wait, một số event_polll được xoá khỏi ready list do chương trình đã biết về sự tồn tại của các event này. Nếu một file trong danh sách chỉ thay đổi trạng thái một lần trong năm, chẳng bao giờ nó có cơ hội được chương trình để mắt đến lần thứ 2.
epoll là the recommended edge-triggered poll từ 2.6 Linux kernel, nhưng bên cạnh đó, có còn hỗ trợ cả level-triggered mode, và đây là chế độ mặc định của nó. Để kích hoạt edge-triggered mode, ta thiết đặt cờ EPOLLETcho events bit mask của file descriptor tương ứng.
Trong chế độ này, miễn là operation của file còn sẵn sàng, nó sẽ không bao giờ bị xoá khỏi ready list. Việc này được thực hiện không có gì phức tạp cả, đơn giản là sau lời gọi epoll_wait, các event_poll được dequeue khỏi ready list, nếu file nào kích hoạt cờ EPOLLET, epoll instance sẽ kiểm tra tính sẵn sàng của file ấy, nếu thoả mãn thì add trở lại vào ready list.
Signal Driven I/O và Asynchronous I/O
Và, đấy là tất cả những gì ẩn dưới lời quảng cáo Asychronous Event-Driven Non-Blocking I/O của NodeJS. Ngoài các I/O model trên, trong Unix còn hỗ trợ thêm hai model nữa.
Thứ nhất là signal driven I/O, một cơ chế non-blocking và sử dụng signal để thông báo khi operation sẵn sàng. Signal chính là tin hiệu ngắt mềm của hệ đều hành đã được nhắc ở phần trên.
Còn nhớ kill -9 pid thường dùng trong Unix chứ? Kill chính là lệnh để truyền đi một signal, và process mang pid khốn khổ kia vừa đón nhận singal có số hiệu là 9 – SIGKILL – giết không cần hỏi, không từ chối, không ngoại lệ. Không rõ cơ chế này hoạt động ra sao, chỉ thấy chẳng được dùng mấy và nghe bảo hiệu năng thì kém hơn epoll.
Cơ chế cuối cùng mang tên asynchronous I/O được cung cấp qua các system call có prefix là aoi_. Với asynchronous I/O, ta chỉ cần gọi kernel một lần, không cần biết là bị block hay không block nhưng tốc độ thực thi chậm (đọc dữ liệu từ regular file trên ổ HDD đời cũ siêu rùa bò chẳng hạn), miễn là kernel chưa thể trả data ngay lập tức, ta có thể kệ nó đi thực hiện việc khác. Sau khi operation hoàn thành, kernel sẽ báo lại và trả dữ liệu cho user mode. Không rõ cách thực hiện và hiệu năng của cách này, chỉ biết nó cũng chẳng được phổ biến rộng.
Kết luận
Bài viết hơi dài nhưng cũng đã làm sáng tỏ khá nhiều khái niệm trìu tượng trong NodeJS. Chính những điểm cơ bản này đã tạo nên sức mạnh của NodeJs.
All rights reserved
