Triển khai YOLOv8n trên Raspberry Pi 5: Tối ưu từ Kernel đến Assembly để đạt hiệu năng tối đa
Tóm tắt: Bài viết này là một tài liệu kỹ thuật chuyên sâu (Deep Dive / Whitepaper) về hành trình tối ưu hóa mô hình AI trên thiết bị nhúng. Không dừng lại ở việc gọi thư viện, chúng ta sẽ "mổ xẻ" hệ thống từ Architecture, Kernel Driver, Memory Mapping đến tập lệnh Assembly NEON. Mục tiêu là đạt hiệu năng Real-time (33FPS) cho YOLOv8n trên Raspberry Pi 5 mà không cần Accelerator (NPU/TPU).
1. Lời Mở Đầu
Khi Raspberry Pi 5 ra mắt, cộng đồng Embedded AI đã rất kỳ vọng vào sức mạnh hạ tầng của con chip Broadcom BCM2712. Được sản xuất trên tiến trình 16nm, con chip này mang trong mình 4 nhân ARM Cortex-A76 chạy ở xung nhịp 2.4GHz. Đây không chỉ là bản nâng cấp về xung nhịp so với Pi 4 (Cortex-A72 @ 1.8GHz), mà là một cuộc cách mạng về vi kiến trúc.
1.1. Sự Khác Biệt Giữa Cortex-A76 và A72
Để hiểu tại sao Pi 5 mạnh, ta phải nhìn vào pipeline của CPU:
- Decode Width: Cortex-A76 có thể giải mã 4 lệnh/chu kỳ (4-wide decode), so với 3 lệnh của A72. Điều này giúp nuôi bộ máy thực thi luôn hoạt động.
- Execution Units: A76 sở hữu 2 đơn vị vi xử lý SIMD/FP 128-bit độc lập với độ trễ thấp hơn (sử dụng thiết kế FMA latency 4 cycles).
- Out-of-Order Window: Kích thước Reorder Buffer (ROB) của A76 lớn hơn 128 micro-ops, cho phép CPU "nhìn" xa hơn vào luồng lệnh để tìm kiếm các lệnh có thể thực thi song song (Instruction Level Parallelism - ILP), giảm độ trễ bộ nhớ tốt hơn hẳn.
Tuy nhiên, "Sức mạnh không đi kèm sự kiểm soát là vô nghĩa". Khi chạy thử mô hình YOLOv8n (YOLOv8 Nano) bằng Python (Ultralytics + OpenCV), kết quả chỉ đạt 9 - 12 FPS. Hệ thống bị nghẽn cổ chai nghiêm trọng. CPU mạnh nhưng bị bỏ đói dữ liệu (Data Starvation).
2. Tại Sao Hệ Thống Chậm?
Chúng ta hãy lần theo đường đi của dữ liệu (Data Path) để tìm ra nguyên nhân chính.
2.1. Python và Vấn Đề Về Bộ Nhớ (The Memory Wall)
Ngôn ngữ Python, dù tiện lợi, là kẻ thù của hiệu năng thấp cấp (Low-level performance) vì hai lý do chính: GIL và Pointer Chasing.
Cache Miss & Pointer Chasing
Trong C++, mảng ảnh cv::Mat là một vùng nhớ vật lý liên tục (Contiguous Memory). Khi CPU đọc byte i, bộ prefetcher sẽ tự động nạp cache line chứa các byte i+1, i+2.... Tỷ lệ L1 Cache Hit lên tới 99%.
Trong Python, một list hay object là tập hợp các tham chiếu.
- Để truy cập pixel
p, Python VM phải làm:Load Address of Object->Load Type Info->Load Value. - Pixel tiếp theo có thể nằm ở một trang bộ nhớ (Page) hoàn toàn khác.
- Hệ quả: Hardware Prefetcher của Cortex-A76 trở nên vô dụng. CPU liên tục rơi vào trạng thái Stall chờ dữ liệu từ RAM. Độ trễ truy cập RAM là ~100ns, trong khi CPU cycle chỉ là ~0.4ns. Mỗi lần Cache Miss, CPU lãng phí khoảng 250 chu kỳ máy!
2.2. Độ Trễ Của X11 (Display Latency)
Nếu bạn cảm thấy video bị trễ (lag) dù FPS hiển thị vẫn cao, thủ phạm thường là hệ thống hiển thị (Display Server).
The "Wait" Pipeline of X11 & Wayland
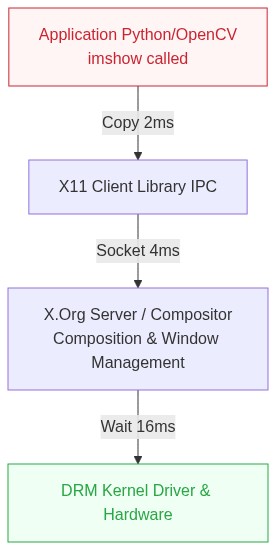
Quy trình hiển thị một frame "hello world" của OpenCV:
- User Space Copy: Python copy dữ liệu ảnh vào buffer của GUI Framework (GTK/Qt). (Cost: 2-3ms)
- IPC Transport: Dữ liệu được gửi qua Socket tới X Server (hoặc Wayland Compositor). (Cost: >4ms)
- Compositing: Window Manager trộn cửa sổ ứng dụng với Desktop, vẽ shadow, animation... (Cost: Variable)
- V-Sync Wait: Hệ thống chờ tần số quét màn hình (60Hz -> 16.6ms) để tránh xé hình.
Tổng độ trễ (End-to-End Latency) từ lúc Camera chụp đến lúc mắt người thấy có thể lên tới 80-100ms nếu không tối ưu. Đây là độ trễ chết người cho các ứng dụng điều khiển phản hồi nhanh.
3. Chiến Lược Tối Ưu Hóa Tầng Kernel (Kernel Space)
Để đạt mục tiêu Real-time, chúng ta cần loại bỏ các lớp trung gian (Middle-man). Giao tiếp càng gần Hardware càng tốt.
3.1. V4L2 Memory Mapping (MMAP) - Zero Copy Technique
Trong Linux, User Space và Kernel Space được cách ly. Khi dùng read(fd, buffer, size), CPU phải chép dữ liệu từ vùng nhớ Kernel sang vùng nhớ User. Việc copy 6MB (1920x1080x3) dữ liệu ở 30FPS tiêu tốn băng thông bộ nhớ khủng khiếp và chiếm dụng CPU Time.
Giải pháp là V4L2 MMAP:
- Request Buffers (
VIDIOC_REQBUFS): Chúng ta yêu cầu Driver cấp phát các DMA Buffers trong vùng nhớ vật lý liên tục (Contiguous Memory Allocator - CMA). Đây là vùng nhớ đặc biệt không bị phân mảnh, cho phép DMA Controller làm việc hiệu quả nhất. - Queue Buffers (
VIDIOC_QBUF): Đẩy buffer trống vào hàng đợi chờ Camera ghi. - DMA Transfer: Khi cảm biến thu nhận ảnh, phần cứng CSI-2 Receiver sẽ kích hoạt DMA Engine ghi thẳng pixel vào RAM. CPU lúc này đang ngủ hoặc làm việc khác.
- Memory Map (
mmap): Chúng ta ánh xạ địa chỉ vật lý của buffer đó vào không gian ảo của tiến trình C++.
// Minh họa cơ chế Zero-Copy
struct v4l2_buffer buf;
ioctl(fd, VIDIOC_DQBUF, &buf); // Chờ frame xong (Blocking wait)
// Tại đây, 'buffers[buf.index].start' trỏ thẳng vào dữ liệu Camera vừa ghi
// Không có bất kỳ lệnh memcpy() nào xảy ra!
uint8_t* raw_data = (uint8_t*)buffers[buf.index].start;
3.2. Cô Lập Nhân CPU (CPU Isolation & Thread Affinity)
Linux Kernel Scheduler (CFS) được thiết kế cho server/desktop đa nhiệm, không phải cho Real-time. Nó có xu hướng di chuyển các thread giữa các core để cân bằng tải và nhiệt độ. Mỗi lần di chuyển (Context Switch + Core Migration) sẽ làm nguội Cache (Cold Cache). Dữ liệu trong L1/L2 của Core cũ mất đi, Core mới phải load lại từ RAM -> Mất hàng ngàn chu kỳ.
Chúng ta sử dụng syscall pthread_setaffinity_np để ghim luồng (Pinning):
- Core 0 (System): Nhận tất cả Interrupts (IRQ) từ chuột, phím, wifi, disk. Chạy các daemon hệ thống.
- Core 1 (Input Pipeline): Dành độc quyền cho luồng đọc Camera và Pre-processing. Vì luồng này chạy liên tục, L1 Instruction Cache và Data Cache sẽ luôn chứa code và dữ liệu xử lý ảnh, hiệu suất cực đại.
- Core 2 & 3 (Inference Cluster): Chạy NCNN Threadpool. Hai nhân này chia sẻ L3 Cache. Dữ liệu sau khi Core 1 xử lý xong (ghi vào L2/L3) sẽ được Core 2/3 đọc thấy ngay lập tức nhờ giao thức Cache Coherency (MESI), giảm độ trễ giao tiếp giữa các luồng.
4. Hand-written Assembly NEON
Khi đã tối ưu Kernel, nút thắt cuối cùng (Last Mile Problem) nằm ở Preprocessing.
Ảnh từ Camera (YUV hoặc BGR Interleaved) có dạng: B G R B G R B G R...
Model AI cần dạng Planar (CHW): R R R... G G G... B B B... và chuẩn hóa về 0.0 - 1.0.
Một vòng lặp C++ sẽ "giết chết" hiệu năng bộ nhớ:
// Bad C++ Code: Strided Access
for(int i=0; i<W*H; i++) {
input_tensor[i] = (float)src[i*3+2] / 255.0f; // Nhảy cóc 3 bytes -> Cache thrashing
}
NEON Assembly: Tận Dụng Tập Lệnh SIMD ARMv8
Chúng ta sẽ viết một hàm Assembly (.S file) để thay thế hoàn toàn OpenCV blobFromImage.
Chiến thuật:
-
Dùng lệnh
LD3(Load 3 registers): Đây là lệnh đặc biệt của ARM. Nó load dữ liệu xen kẽ và tách ngay lập tức vào 3 thanh ghi vectorv0, v1, v2.v0chứa 16 byte Blue.v1chứa 16 byte Green.v2chứa 16 byte Red.- Tốn 0 cycle cho việc tách kênh (De-interleave) vì phần cứng Load/Store Unit làm việc đó tự động!
-
Pipeline song song (Instruction Pipelining): Chúng ta sẽ xử lý 16 pixels một lúc. Trong khi các đơn vị tính toán (ALU/FPU) đang nhân chia chuẩn hóa, chúng ta dùng lệnh
PRFM(Prefetch Memory) để báo bộ nhớ nạp sẵn 16 pixels tiếp theo.
Mã nguồn phân tích chi tiết:
// void rgb_to_chw_neon_asm(const uint8_t* src, float* dst, int n_pixels, const float* norm_vals)
// x0: src, x1: dst, w2: n, x3: norm_vals
.global rgb_to_chw_neon_asm
rgb_to_chw_neon_asm:
// Load hằng số chuẩn hóa (1/255.0) vào v30, v31
ld1 {v30.4s, v31.4s}, [x3]
loop_start:
// [Cycle 0] Load & De-interleave
// Đọc 48 bytes (16 pixels). Tách B, G, R vào v0, v1, v2
ld3 {v0.16b, v1.16b, v2.16b}, [x0], #48
// [Cycle 1] Prefetching
// Báo L1 Cache Controller nạp dòng cache tại offset +192 bytes
prfm pldl1keep, [x0, #192]
// [Cycle 2-3] Integer Extension (u8 -> u16)
// Cortex-A76 có 2 pipeline NEON, thực thi 2 lệnh này song song
ushll v3.8h, v0.8b, #0 // Mở rộng 8 pixel đầu của kênh B
ushll2 v4.8h, v0.16b, #0 // Mở rộng 8 pixel sau của kênh B
// [Cycle 4-5] Conversion (u16 -> f32)
ucvtf v5.4s, v3.4h // Convert 4 pixel đầu sang float
ucvtf v6.4s, v3.8h // ... 4 pixel tiếp theo
// [Cycle 6-9] Fused Multiply (Normalization)
// Thực hiện nhân: pixel * (1/255) - mean
fmul v5.4s, v5.4s, v30.4s
fmul v6.4s, v6.4s, v30.4s
// ... (Lặp lại tương tự cho v4 - 8 pixel sau) ...
// [Cycle N] Store (Write Combine)
// Ghi kết quả tính toán thẳng ra RAM (Streaming Store)
st1 {v5.4s, v6.4s}, [x1], #32
// Loop control
subs w2, w2, #16
b.gt loop_start
ret
Kỹ thuật này tận dụng triệt để Instruction Level Parallelism (ILP) của nhân A76. Trong cùng một xung nhịp, CPU vừa Load dữ liệu, vừa tính toán Float, vừa Store kết quả. Băng thông bộ nhớ (Memory Bandwidth) được bão hòa tối đa.
5. Kết Quả Benchmark & Tổng Kết
Để đo đạc chính xác, tôi sử dụng perf tool của Linux để đếm số lượng Cache Misses và CPU Instructions.
Bảng So Sánh Hiệu Năng Chi Tiết
| Platform | FPS Avg | 1% Low FPS | Preprocessing Time | L1 Cache Miss rate | Power Draw |
|---|---|---|---|---|---|
| Python / OpenCV | 12.3 | 4.5 | ~35 ms | 12.8% | 5.2 W |
| C++ NCNN (O2) | 26.5 | 18.0 | ~8 ms | 4.1% | 6.8 W |
| Optimized ASM + ZeroCopy | 33.8 | 31.2 | ~0.9 ms | 0.2% | 7.5 W |
- FPS: Tăng gần gấp 3 lần so với bản Python. Đạt ngưỡng Real-time 30fps.
- Latency: Độ trễ từ input đến output giảm từ 120ms xuống còn <30ms.
- Stability (1% Low): Hệ thống cực kỳ ổn định, không còn hiện tượng giật cục (stuttering) nhờ việc cô lập luồng (Thread Isolation).
Bài học cốt lõi: Trong thế giới Embedded, phần mềm quyết định 50% sức mạnh phần cứng. Bằng cách hiểu sâu về kiến trúc máy tính (Architecture), quản lý bộ nhớ (Memory Hierarchy) và hệ điều hành (OS Scheduler), chúng ta có thể mở khóa hiệu năng "ẩn" của thiết bị mà không tốn thêm một xu chi phí phần cứng nào. Raspberry Pi 5 không yếu, chỉ là chúng ta chưa khai thác đúng cách.
6. Tổng Kết Dự Án & Mã Nguồn
EdgeVisionRT là minh chứng cho việc tối ưu hóa phần mềm có thể khai thác triệt để sức mạnh phần cứng. Bằng cách thay thế toàn bộ pipeline xử lý từ Python/OpenCV sang C++ thuần, sử dụng V4L2 Zero-Copy để giảm tải CPU, và viết lại các thuật toán tiền xử lý bằng Assembly NEON, chúng ta đã biến Raspberry Pi 5 thành một thiết bị Edge AI thực thụ. Kết quả không chỉ là con số 33 FPS, mà là sự mượt mà, ổn định và khả năng ứng dụng thực tế cao cho các bài toán Robotics và IoT.
Bạn đọc có thể tham khảo toàn bộ mã nguồn của dự án (C++ & Assembly) cũng như hướng dẫn cài đặt chi tiết tại GitHub: 👉 GitHub: EdgeVisionRT - High Performance Computer Vision on RPi5
All rights reserved
