Triển khai Data Synchronization đa nguồn cho hệ thống AI
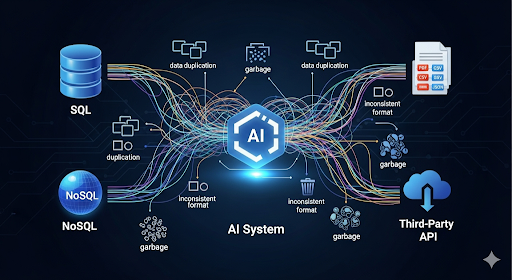
Trong các dự án AI Agent, dữ liệu không chỉ “nhiều”, mà còn “phân tán” và “không đồng nhất”. Việc gom dữ liệu từ cơ sở dữ liệu, API, file tài liệu cho đến các dịch vụ SaaS về một pipeline thống nhất là yêu cầu cơ bản để xây dựng hệ thống thông minh, đặc biệt trong các ứng dụng Retrieval-Augmented Generation (RAG). Một quy trình đồng bộ hóa dữ liệu bài bản giúp kiểm soát chất lượng, đảm bảo đầu vào sạch và dễ mở rộng.
Bối cảnh & vấn đề đặt ra khi đồng bộ dữ liệu cho hệ thống AI
Trong môi trường doanh nghiệp, developer thường phải xử lý dữ liệu phát sinh từ nhiều hệ thống khác nhau:
- CSDL quan hệ: MySQL, PostgreSQL, SQL Server
- NoSQL: MongoDB, Elasticsearch
- Tài liệu: PDF, DOCX, HTML, CSV
- API từ CRM/ERP/eCommerce
Nếu không có pipeline xử lý chuẩn, hệ thống rất dễ gặp các lỗi phổ biến:
- Dữ liệu trùng lặp hoặc thiếu cấu trúc
- Văn bản chứa ký tự lỗi, text rác
- Metadata không nhất quán, gây khó khăn cho truy vấn và phân tích
- Khó mở rộng khi bổ sung nguồn dữ liệu mới
Các LLM dùng trong RAG sẽ phải “chịu đựng” dữ liệu không tiêu chuẩn, dẫn đến giảm độ chính xác hoặc phát sinh hallucination.
Kiến trúc ETL cơ bản để xây dựng dữ liệu cho RAG
Một pipeline ETL được thiết kế đúng sẽ giúp dữ liệu đi qua ba giai đoạn rõ ràng, đảm bảo AI có ngữ cảnh tốt hơn và tránh nhiễu.
Extract – Thu thập dữ liệu đa nguồn
Mục tiêu của lớp Extract là lấy dữ liệu tự động hóa tối đa, hạn chế thao tác thủ công.
Từ Database
- Python: SQLAlchemy
- Node.js: Prisma hoặc Sequelize
Từ file tài liệu
- PDF →
pdfplumber - DOCX →
python-docx - HTML → BeautifulSoup (Python) hoặc Cheerio (Node.js)
Từ API
- Python:
requests,httpx - Node.js:
axios - Dùng
.envvàdotenvđể tránh lộ secret key
Transform – Làm sạch và chuẩn hóa dữ liệu
Đây là phần ảnh hưởng trực tiếp đến khả năng hiểu của AI.
Các bước quan trọng gồm:
- Chuẩn hóa encoding về UTF-8
- Loại bỏ ký tự rác, HTML tag, dấu xuống dòng thừa
- Chuyển đổi thời gian về ISO 8601
- Chunking nội dung: 500–1000 token/chunk
- Tạo embedding qua
sentence-transformershoặc API OpenAI/Anthropic
Kết quả cuối cùng là bộ dữ liệu sạch, đồng nhất và dễ xử lý trong phase nạp.
Load – Đưa dữ liệu vào hệ thống AI
Developer cần chọn hạ tầng vector phù hợp:
- Pinecone, Weaviate, Milvus
- Local: FAISS
Schema đề xuất cho mỗi bản ghi:
{
"id": "...",
"text_chunk": "...",
"embedding": [...],
"metadata": {
"source": "...",
"created_at": "...",
"tags": [...]
}
}
RAG layer có thể được triển khai bằng:
- LangChain
- LlamaIndex
Lợi ích khi dùng Data Synchronization + ETL cho RAG
3.1 Tối ưu tốc độ và độ chính xác khi truy vấn
Dữ liệu đã index theo vector giúp mô hình tìm kiếm nhanh hơn nhiều so với quét dữ liệu thô. Ví dụ câu hỏi về “Top khách hàng chi tiêu cao nhất Q2/2025” chỉ cần vector search thay vì query toàn DB.
Giảm tối đa rủi ro hallucination
- Dữ liệu sạch → mô hình ít bị nhiễu
- Metadata đầy đủ → AI trả lời có căn cứ
- Loại bỏ trùng lặp → tránh câu trả lời mâu thuẫn
Dễ mở rộng luồng dữ liệu
Nhờ cấu trúc modular:
- Thêm nguồn dữ liệu mới chỉ cần viết connector
- Thay đổi embedding model mà không phá pipeline cũ
- Dễ chuyển đổi từ FAISS nội bộ sang Pinecone/Weaviate khi hệ thống lớn hơn
Gia tăng giá trị vận hành & kinh doanh
- Chatbot AI phản hồi nhanh dựa trên dữ liệu chuẩn hóa
- Marketing cá nhân hóa nhờ dữ liệu đa kênh đã đồng bộ
- Ban lãnh đạo có thể hỏi AI dưới dạng ngôn ngữ tự nhiên để lấy báo cáo ngay lập tức
Kết luận
Đồng bộ hóa dữ liệu từ nhiều nguồn vào một pipeline AI không chỉ là một bài toán kỹ thuật, mà là nền tảng cho mọi ứng dụng RAG hiện đại. Khi dữ liệu được chuẩn hóa, phân tách, embedding và lưu trữ đúng cách, hệ thống AI sẽ hoạt động ổn định hơn, nâng cao hiệu quả truy vấn và tạo ra giá trị thực cho doanh nghiệp.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-dong-bo-du-lieu-tu-nhieu-nguon-ve-mot-he-thong-ai.html
All rights reserved
