Tổng quan về Tin sinh học
Bài đăng này đã không được cập nhật trong 5 năm
Giới thiệu chung về Tin sinh học
Tin sinh học là gì?
Tin sinh học là một lĩnh vực nghiên cứu liên ngành ở khoa học sinh học và khoa học tính toán. Mặc dù thuật ngữ 'Tin sinh học' không thực sự được xác định rõ ràng, chúng ta có thể nói rằng lĩnh vực khoa học này liên quan đến việc quản lý tính toán của tất cả các loại thông tin sinh học phân tử. Hầu hết các công việc tin sinh học đang được thực hiện liên quan đến phân tích dữ liệu sinh học hoặc tổ chức thông tin sinh học. Tin sinh học sử dụng các công nghệ của các ngành toán học ứng dụng, tin học, thống kê, khoa học máy tính, trí tuệ nhân tạo, hóa học và hóa sinh (biochemistry) để giải quyết các vấn đề sinh học.
Tin sinh học và khoa học tính toán
Một thuật ngữ thường được dùng thay thế cho Tin sinh học là Sinh học tính toán (computational biology). Tuy nhiên, chỉ có một ranh giới rất nhỏ về sự khác biệt giữa Tin sinh học và Sinh học tính toán, khác biệt đó có thể phát biểu như sau:
- Sinh học tính toán tập trung vào phát triển và ứng dụng các phương pháp phân tích dữ liệu, lý thuyết, mô hình toán học và mô phỏng tính toán để nghiên cứu về sinh học, hành vi và hệ thống xã hội.
- Trong khi đó, Tin sinh học tập trung vào nghiên cứu, phát triển hoặc ứng dụng các công cụ và phương pháp tính toán để mở rộng việc sử dụng dữ liệu sinh học, y tế, hành vi hoặc sức khỏe, bao gồm cả những dữ liệu để thu thập, lưu trữ, tổ chức, phân tích hoặc trực quan hóa dữ liệu đó
Hình ảnh sau đến từ một cuộc thảo luận trên ResearchGate cho chúng ta cái nhìn trực quan hơn về hai lĩnh vực này.
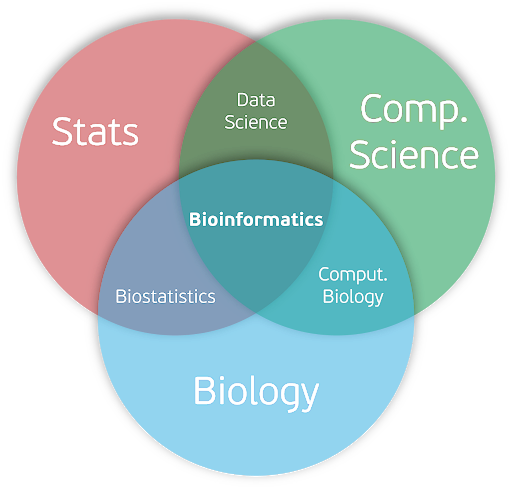
Samuel, Johnson. (2020). Re: What are the differences between Bioinformatics and Computational Biology ? . Retrieved from: https://www.researchgate.net/post/What_are_the_differences_between_Bioinformatics_and_Computational_Biology/5f51aad578613d7eea78eadc/citation/download.
Lịch sử phát triển của Tin sinh học
Tin sinh học không phải là một ngành nghiên cứu truyền thống. Thuật ngữ Tin sinh học được giới thiệu lần đầu tiên vào những năm 90 thế kỉ trước. Ban đầu, nó xử lý việc quản lý và phân tích dữ liệu liên quan đến chuỗi DNA, RNA và protein bởi vì dữ liệu sinh học được tạo ra với tốc độ chưa từng có, việc quản lý và giải thích nó luôn đòi hỏi phải có các công cụ tính toán mạnh mẽ như máy tính được sử dụng trong Tin sinh học. Vì vậy, tin sinh học hiện nay bao gồm nhiều loại dữ liệu sinh học khác. Bỏ qua những mốc thời gian quan trọng của Sinh học cũng như Khoa học máy tính cũng như thống kê, chúng ta có thể liệt kê các mốc thời gian quan trọng của Tin sinh học hiện đại như sau:
- 1962 - Thuyết tiến hóa phân tử của Pauling được công bố
- 1967 - Bản đồ protein của Margaret Dayhoff được công bố. Cuốn sách này nói về sự mã hóa thoái hóa của các axit amin, là tiền đề cho cơ sở dữ liệu Protein Information Resource về trình tự protein, hệ thống cơ sở dữ liệu trực tuyến đầu tiên có thể được truy cập bằng máy tính từ xa.
- 1970 - Thuật toán Needleman-Wunsch được công bố. Thuật toán Needleman – Wunsch là một thuật toán được sử dụng trong tin sinh học để sắp xếp trình tự protein hoặc nucleotide.
- 1977 - Giải trình tự DNA và các phần mềm để phân tích nó xuất hiện, có thể kể đến là Staden Package
- 1981 - Khái niệm về mô típ trình tự (Doolittle) xuất hiện. Một trình tự motif có thể hiểu là một đoạn trình tự nucleotide hoặc amino acid phổ biến và có, hoặc cho là có, một chức năng sinh học nào đó.
- 1982 - Các nghiên cứu về Thực khuẩn thể Lambda được công bố
- 1983 - Phương pháp truy vấn các cơ sở dữ liệu được công boos: thuật toán Wilbur-Lipman
- 1985 - FASTP/FASTN(fast sequence similarity searching) được công bố
- 1987 - Sequence profiles
- 1987 - Các cơ sở dữ liệu EMBL, Genbank,Swiss Genbank,Swiss-Prot xuất hiện
- 1988 - Trung tâm Thông tin Công nghệ sinh học Quốc gia Hoa Kỳ được thành lập
- 1988 - Mạng lưới các phân tán các cơ sở dữ liệu EMBnet xuất hiện
- 1990 - BLAST: fast sequence similarity searching BLAST: fast sequence similarity searching
- 1991 - EST: expressed seque EST: expressed sequence tag sequencing nce tag sequencing
- 1993 - Trung tâm Sanger, Hinxton, Vương quốc Anh được thành lập
- 1994 - Viện Tin sinh học Châu Âu: EMBL(European Bioinformatics Institute), Hinxton, Vương quốc Anh được thành lập
- 1995 - Bộ gen vi khuẩn đầu tiên được công bố
- 1996 - Bộ gen của men bia được công bố
- 1997 - Công cụ tìm kiếm căn chỉnh cục bộ cơ bản liên tục PSI-BLAST(Position-Specific Iterative Basic Local Alignment Search Tool)) xuất hiện
- 1998 - Giun (bộ gen đa bào)
- Những năm 2000 đến nay - Các nghiên cứu về bộ gen của người và lúa được công bố.
Trong thời gian gần đây, cùng với sự phát triển vượt bậc của khoa học tính toán cũng như sức mạnh của máy tính được gia tăng với tốc độ cao, các nhà nghiên cứu của Tin sinh học thu được rất nhiều thành tựu đáng kể trong việc xử lý các dữ liệu lớn trong lĩnh vực sinh học. Một trong những nguồn dữ liệu tin cậy để tra cứu các công bố về Tin sinh học là PubMed - một cơ sở dữ liệu miễn phí truy cập chủ yếu qua cơ sở dữ liệu MEDLINE về các tài liệu tham khảo và tóm tắt về các chủ đề khoa học đời sống và y sinh học.
Các vấn đề cơ bản của Tin sinh học
Bài tổng quan về Tin sinh học trên Wikipedia liệt kê các lĩnh vực nghiên cứu chính bao gồm Genomics - Hệ gene học, Sinh học tiến hoá, Phân tích chức năng gene, Các hệ thống sinh học kiểu mẫu và Phân tích hình ảnh mức độ cao và cùng với đó là các phân vùng nghiên cứu nhỏ hơn của chúng. Bài viết này không nhắc lại toàn bộ các phần trên mà chỉ tập trung vào hai phần chính là Genomics (hệ gen học) và Proteomics cũng như Transcriptomics: lĩnh vực được một số bài viết liệt kê bên cạnh hai phần trên tuy nhiên không được đề cập đến trong bài viết trên Wikipedia.
Genomics
Trọng tâm của genomics là bộ gen, là bộ gen tất cả DNA trong một sinh vật, bao gồm cả gen của nó. Các gen mang thông tin để tạo ra tất cả các protein được yêu cầu bởi tất cả các sinh vật. Những protein này quyết định hình dạng của sinh vật, cách cơ thể nó chuyển hóa thức ăn hoặc chống lại nhiễm trùng tốt như thế nào, và đôi khi thậm chí cả cách nó hoạt động. DNA được tạo thành từ bốn chất hóa học giống nhau (được gọi là bazơ và viết tắt là A, T, C, và G) được lặp lại hàng triệu hoặc hàng tỷ lần trong toàn bộ hệ gen. Thứ tự cụ thể của các A, T, C và G là cực kỳ quan trọng. Thứ tự làm nền tảng cho sự đa dạng của sự sống, thậm chí quyết định xem một sinh vật là người hay một loài khác như nấm men, lúa gạo hay ruồi giấm, tất cả đều có bộ gen của riêng mình và tự chúng là trọng tâm của các dự án bộ gen. Bởi vì tất cả các sinh vật có liên quan với nhau thông qua những điểm tương đồng trong trình tự DNA, những hiểu biết sâu sắc thu được từ bộ gen không phải của con người thường dẫn đến kiến thức mới về sinh học của con người.
Một trong những ứng dụng của hệ gen học có thể kể đến được minh họa dựa trên hình sau:
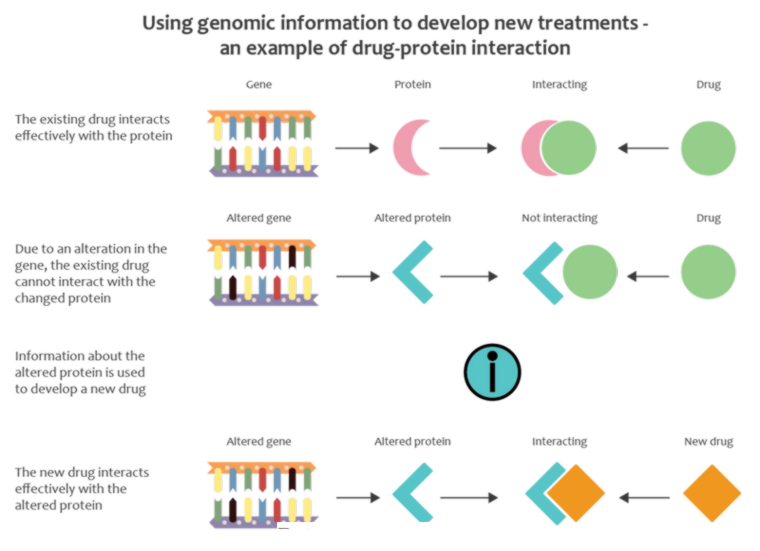
Using genomic information to develop new treatments-an example of drug protein interaction. This image was created by the NHS HEE Genomics Education Programme. For further information and resources please visit our website www.genomicseducation.hee.nhs.uk
Proteomics
Proteomics tập trung vào việc xác định cấu trúc ba chiều của protein, sự tương tác và chức năng của nó. Các nghiên cứu công bố thường tập trung vào dự đoán cấu trúc và tương tác protein-protein được trình bày trong phần này. Các phân tích chức năng bao gồm lập hồ sơ biểu hiện gen, dự đoán tương tác protein-protein, dự đoán bản địa hóa dưới tế bào protein, tái tạo lại con đường trao đổi chất và mô phỏng.
Proteomics tập trung vào tìm hiểu:
- Khi nào và ở đâu protein được biểu hiện
- tỷ lệ sản xuất, phân hủy protein và sự phong phú ở trạng thái ổn định;
- Protein được biến đổi như thế nào
- Sự di chuyển của protein giữa các ngăn dưới tế bào;
- Sự tham gia của protein trong các con đường trao đổi chất;
- Cách các protein tương tác với nhau.
Proteomics có thể cung cấp thông tin sinh học quan trọng cho nhiều vấn đề sinh học, chẳng hạn như:
- Những protein nào tương tác với một protein cụ thể được quan tâm
- Những protein nào được bản địa hóa trong một ngăn dưới tế bào
- Những protein nào tham gia vào một quá trình sinh học
Hình sau đến từ bài viết What is proteomics? cho chúng ta cái nhìn tổng quát về các lĩnh vực nghiên cứu của Proteomics
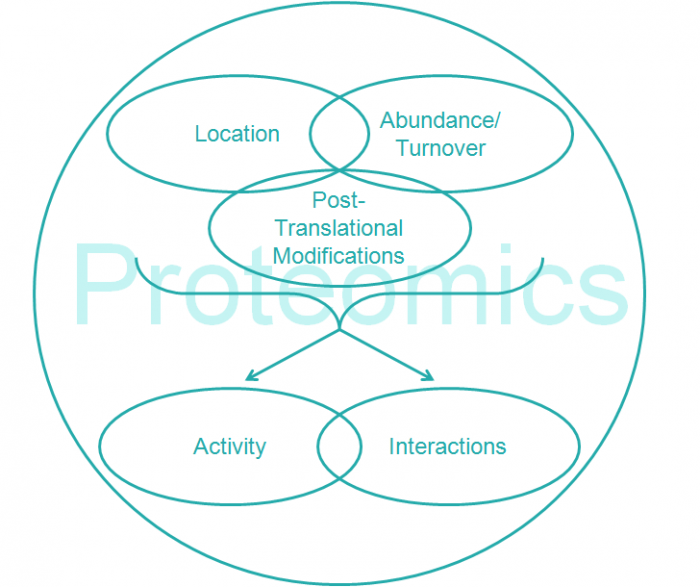
Từ hình trên chúng ta có thể thấy các thí nghiệm về proteomic thường thu thập dữ liệu về ba đặc tính của protein trong một mẫu: vị trí, sự phong phú/chu chuyển và các sửa đổi sau dịch mã. Tùy thuộc vào thiết kế thử nghiệm, các nhà nghiên cứu có thể quan tâm trực tiếp đến những dữ liệu này hoặc có thể sử dụng chúng để suy ra thông tin bổ sung như có thể suy ra các đối tác tương tác của protein trong số các đối tác khác có màu với nó, hoặc để đánh giá xem một protein có hoạt động từ các sửa đổi sau dịch mã hay không.
Nội dung phần tham khảo bài viết What is proteomics? được đăng tải trên trang web của Viện Tin sinh học Châu Âu (The European Bioinformatics Institute < EMBL-EBI)
Transcriptomics
Transcriptomics là lĩnh vực nghiên cứu về bộ phiên mã — tập hợp đầy đủ các bản sao RNA được tạo ra bởi bộ gen, trong những trường hợp cụ thể hoặc trong một tế bào cụ thể — bằng cách sử dụng các phương pháp thông lượng cao, chẳng hạn như phân tích microarray. So sánh các transcriptomes cho phép xác định các gen được biểu hiện khác biệt trong các quần thể tế bào riêng biệt hoặc để đáp ứng với các phương pháp điều trị khác nhau.
Các hướng chính của nghiên cứu Transcriptomics:
- Mô tả các trạng thái khác nhau của tế bào (tức là các giai đoạn phát triển), các mô hoặc các giai đoạn chu kỳ tế bào bằng các kiểu biểu hiện;
- Khám phá các cơ chế phân tử bên dưới một kiểu hình;
- Xác định các dấu ấn sinh học biểu hiện khác nhau giữa trạng thái bị bệnh và trạng thái khỏe mạnh;
- Phân biệt các giai đoạn hoặc loại bệnh phụ (ví dụ: giai đoạn ung thư);
- Thiết lập mối quan hệ nhân quả giữa các biến thể di truyền và các kiểu biểu hiện gen để làm sáng tỏ căn nguyên của các bệnh.
Tham khảo từ phần 3 - Transcriptomics trong Bioinformatics for Biomedical Science and Clinical Applications, Woodhead Publishing Series in Biomedicine trang 49-82 của tác giả Kung-HaoLiang xem thêm tại đây
Transcriptomics hiện vẫn là một lĩnh vực mới đang phát triển bởi vậy chúng ta không thể liệt kê hết tiềm năng của nó. Tuy nhiên, chúng ta vẫn có thể liệt kê một số ứng dụng quan trọng của nó như sau:
- Nhân giống và lai tạo cây trồng.
- Nghiên cứu tế bào gốc và ung thư.
- Nghiên cứu phát sinh phôi và thụ tinh trong ống nghiệm.
- Nghiên cứu biểu hiện gen cụ thể trên mô.
- Đặc điểm của các RNA không mã hóa.
- Các retrotransposon như TE được kết hợp vào hệ gen thông qua phiên mã ngược, các chuyển vị hoạt động có thể phá vỡ các chức năng * của gen và gây ra đột biến hoặc thay đổi biểu sinh.
- Phiên mã giống như các công nghệ được sử dụng để phát hiện sự hiện diện của các phần tử có thể chuyển vị trong bộ gen.
- Công nghệ RNA-seq dựa trên transcriptomics được sử dụng để phát hiện các chủng gây bệnh và độc lực có trong mẫu.
Kết luận trên tham khảo từ bài viết Transcriptomics technologies của các tác giả Rohan Lowe,Neil Shirley,Mark Bleackley,Stephen Dolan,Thomas Shafee có thể xem thêm tại đây
Kết luận
Bài viết ngắn trên đã trình bày sơ qua các thông tin cơ bản của Tin sinh học bao gồm khái niệm cơ bản, lịch sử hình thành, phân biệt nó với các lĩnh vực liên quan khác cũng như các lĩnh vực nghiên cứu chính. Cùng với sự phát triển của công nghệ, các lĩnh vực mới như Tin sinh học có cơ hội phát triển nhanh hơn trước rất nhiều và dần được chú ý nhiều hơn, ví dụ như môn Tin sinh học ở trường mình năm nay mở hẳn 3 lớp chứ không như nhiều năm trước ít người đăng ký nên không mở được lớp (học lấy kiến thức chứ không phải vì điểm cao). Tin sinh học là lĩnh vực liên ngành vậy nên để có khả năng làm việc trong lĩnh vực này, chúng ta cần tự trang bị cho mình một lượng lớn kiến thức về Sinh học cũng như BigData và thống kê hơn nữa nó lại là một ngành khó cũng như là lĩnh vực trẻ nên sẽ có một số khó khăn cho mọi người để có thể bắt đầu làm quen. Bởi vậy để có thể cập nhật các kiến thức về lĩnh vực này, chúng ta có thể tham khảo các tài liệu cũng như công bố từ các cơ sở uy tín như European Bioinformatics Institute, National Center for Biotechnology Information, ... cũng như các trang web như PubMed hoặc nature research. Bài viết đến đây là hết cảm ơn mọi người đã giành thời gian để đọc.
All rights reserved
