Tối ưu hóa Elasticsearch Queries với Pagination
Bài đăng này đã không được cập nhật trong 4 năm
Elasticsearch có lẽ là thứ không phải xa lạ gì với anh em developer chúng ta vì nó làm quá tốt về searching . Hôm nay mình xin phép trình bày một số cách để optimize tốc độ search với phân trang (Pagination) trong Elasticsearch.
Elasticsearch cung cấp ba cách phân trang :
- From/Size Pagination
- Search After Pagination
- Scroll Pagination
1. From/Size Pagination
Trong Elasticsearch cũng có cơ chế phân trang giống như OFFSET và LIMIT trong SQL đó là FROM và SIZE, cụ thể các bạn có thể xem ở đây search-request-from-size. Mặc định Elasticsearch sẽ settings:
- FROM = 0
- SIZE = 10
GET shakespeare/_search
{
"from" : 0, "size" : 10,
"query" : {
"term" : { "play_name" : "linh" }
}
}
Trong thực tế sau khi search bằng elasticsearch kết quả trả về thường sẽ được phân trang. để hỗ trợ cho việc phân trang elasticsearch cung cấp cho chúng ta from/size. Tham số from xác định phần bù từ kết quả đầu tiên bạn muốn tìm nạp. Tham số size cho phép bạn định cấu hình số lần truy cập tối đa được trả về. Mặc dù from và size có thể được đặt làm tham số yêu cầu, chúng cũng có thể được đặt trong body search. from có giá trị mặc định là 0 và size mặc định là 10.
Lưu ý rằng from + size không thể lớn hơn index.max_result_window mặc định là 10.000. Điều này có thể hiểu đơn giản là kết qura sau khi search trả về mặc định sẽ nhỏ hơn hoặc bằng 10000. Vấn đề xảy ra khi chúng ta muốn lấy về tất cả kết quả của việc search và số lượng kết quả lại lớn hơn có số 10000.
Điều này có nghĩa là để làm việc với dữ liệu nhỏ thì phân trang theo cách trên là hiệu quả nhất vì Elasticsearch mặc định settings cho mục index.max_result_window là 10000. Nhưng khi dữ liệu bạn vượt quá mức giới hạn thì Elasticsearch sẽ cảnh báo bạn và nó cũng không quên đưa ra giải pháp cho bạn:
Để giải quyết vấn đề này có 3 cách:
- Cách đơn giản nhất là thay đổi index.max_result_window, nhưng có thể thấy cách này khá là cứng chúng ta có thể set index.max_result_window lên 20000, 30000 nhưng có trời mới biết đc biết đâu có 1 ngày kết quả trả về còn lớn hơn con số chúng ta cấu hình ngoài ra thì khi kết quả trả về quá lớn, quá trình sắp xếp có thể thực sự trở nên rất nặng nề, sử dụng lượng lớn CPU, bộ nhớ và băng thông.
- Scroll API: Để truy xuất một lượng dữ liệu lớn 1 cách hiệu quả thì chúng ta nên dùng Scroll Api, nó giống như cách bạn sử dụng con trỏ trên cơ sở dữ liệu truyền thống. Để sử dụng Scroll, bạn sẽ chỉ định tham số scroll trong chuỗi truy vấn để cho Elasticsearch biết nó nên giữ "ngữ cảnh tìm kiếm" trong bao lâu, ví dụ: scroll = 1m( 1 phút).
- Search After: ý tưởng vẫ nlaf sử dụng 1 con trỏ để lấy ra kết quả ở trang sau từ trang trước. Nhưng ở đây là một con trỏ trực tiếp (có thể sử dụng một trường giá trị unique để làm việc này).
Vì cách 1 khá là try hard và rủi do nên elastic đã khuyên sử dụng cách 2,3.
2. Scroll Pagination
Bây giờ chúng ta sẽ đi vào tìm hiểu Scroll Api trong Elasticsearch, cụ thể hơn bạn có thể đọc thêm tài liệu ở đây Scroll . Để truy xuất một lượng dữ liệu lớn 1 cách hiệu quả thì chúng ta nên dùng Scroll Api, nó giống như cách bạn sử dụng con trỏ trên cơ sở dữ liệu truyền thống. Để sử dụng scroll, bạn sẽ chỉ định tham số scroll trong chuỗi truy vấn để cho Elasticsearch biết nó nên giữ "ngữ cảnh tìm kiếm" trong bao lâu, ví dụ: scroll = 1m( 1 phút).
POST /twitter/_search?scroll=1m
{
"size": 100,
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
Truy vấn đầu tiên, thiết lập cho nó thêm một tham số là scroll gán bằng khoảng thời gian giữ cho con trỏ tìm kiếm tồn tại, ví dụ 30 giây 30s, 3 phút là 3m. Nếu có tham số này thì kết quả truy vấn đầu tiên sẽ trả về, có kèm một một tham số là id của con trỏ _scroll_id - nó trỏ đến dòng kết quả của ngữ cảnh tìm kiếm hiện tại. Từ con trỏ này, yêu cầu lấy các giá trị tiếp theo
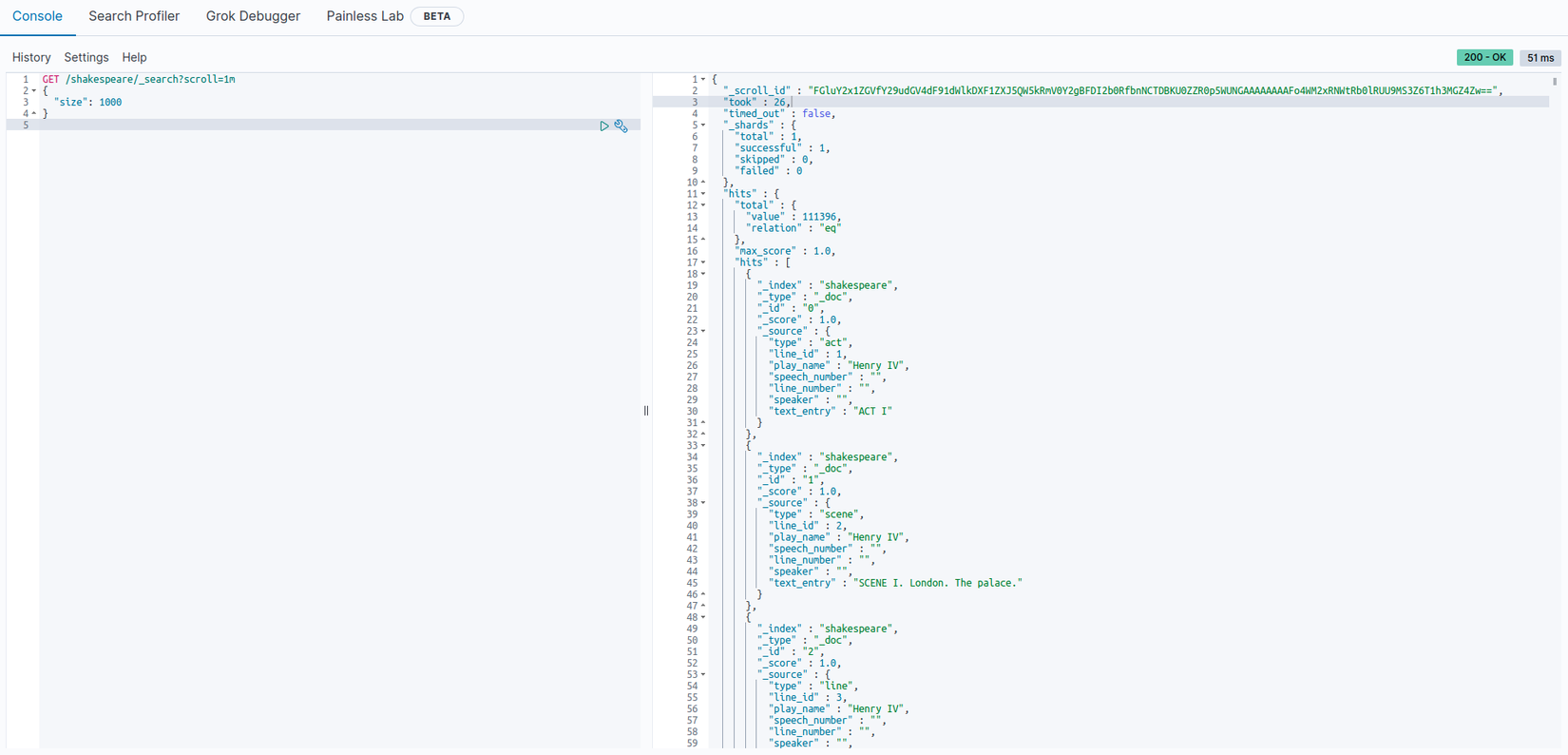
Kết quả từ yêu cầu trên bao gồm _scroll_id "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFDI2b0RfbnNCTDBKU0ZZR0p5WUNGAAAAAAAAFo4WM2xRNWtRb0lRUU9MS3Z6T1h3MGZ4Zw==", nó được chuyển đến API scroll để truy xuất lô kết quả tiếp theo.
Khi ban sử dụng Scroll Api thì bạn sẽ phải loại bỏ đi tham số FROM , tham số SIZE cho phép bạn định cấu hình số lần truy cập tối đa được trả về với mỗi lô kết quả. Mỗi cuộc gọi đến API scroll sẽ trả về lô kết quả như vậy với 1 _scroll_id mới cho đến khi không còn kết quả nào để trả lại, tức là mảng truy cập trống.
Kết quả được trả về từ một scroll request phản ánh trạng thái của index tại thời điểm search yêu cầu ban đầu được thực hiện, giống như một snapshot tại một thời điểm. Những thay đổi tiếp theo đối với documents (index, update or delete) sẽ chỉ ảnh hưởng đến các yêu cầu tìm kiếm sau này. Tức là Scroll API không dành cho các requestcủa user trong thời gian thực.
3. Search After Pagination
Về Scroll Pagination thì elastic không được khuyến cáo với dữ liệu lớn và không hỗ trợ realtime search. Nên đối với dữ liệu lớn và realtime search thì Search After thì được lựa chọn tốt.
Y tưởng sử dụng 1 con trỏ để lấy ra kết quả ở trang sau từ trang trước. Nhưng ở đây là một con trỏ trực tiếp (có thể sử dụng một trường giá trị unique để làm việc này).
Search After hoạt động tương tự như Scroll nhưng nó không có trạng thái. Điều đó có nghĩa là không có dữ liệu được lưu trữ trên máy chủ để điều này hoạt động. Những gì nó cần là một khóa sắp xếp. Search After khi sắp xếp dữ liệu theo khóa và sau đó truy xuất tất cả dữ liệu sau giá trị khóa sắp xếp.
GET shakespeare/_search
{
"size": 10,
"query": {
"match" : {
"speech_number" : "38"
}
},
"search_after": [1463538857, "654323"],
"sort": [
{"line_id": "asc"}
]
}
Một trường có một giá trị duy nhất cho mỗi document nên được sử dụng làm dấu ngắt của đặc tả sắp xếp. Nếu không, thứ tự sắp xếp cho các document có cùng giá trị sắp xếp sẽ không được xác định và có thể dẫn đến kết quả bị thiếu hoặc trùng lặp. Các _id field có giá trị duy nhất cho mỗi tài liệu nhưng nó không được khuyến khích để sử dụng nó như một sợi giây trực tiếp. Hãy cẩn thận khi search_aftertìm kiếm tài liệu đầu tiên khớp hoàn toàn hoặc một phần với giá trị được cung cấp của tiebreaker. Do đó, nếu một tài liệu có giá trị tiebreaker là "654323"và bạn search_aftercho "654"nó sẽ vẫn khớp với tài liệu đó và trả về kết quả tìm thấy sau nó. Giá trị tài liệu bị vô hiệu hóa trên trường này nên việc sắp xếp trên trường này yêu cầu tải nhiều dữ liệu vào bộ nhớ. Thay vào đó, elastic khuyên bạn nên sao chép (client side hoặc với đặt bộ ingest processor ) nội dung của _id fieldg trong một trường khác đã bật giá trị doc và sử dụng trường mới này làm dấu ngắt cho việc sắp xếp.
Ví dụ dưới đây mình sử dụng code ruby khi muốn lấy ra hết tất các Product thỏa mãn điều kiện name là samsung:
records = []
after = 0
total = 0
loop do
results = Product.search body: query_with_search_after(after)
total ||= results.response["hits"]["total"]
records += results
after = records.last&.id
break if records.count < 10000
end
records
def query_with_search_after after
{
size: 10,
query: {
bool: {
must: [
{
term: {
"name": "samsung"
}
}
]
}
},
search_after: [after],
sort: [
id: {
order: "asc"
}
]
}
end
Một số lưu ý khi sử dụng search after :
Nếu sort key trả về cùng một giá trị, thì bạn có thể bỏ lỡ các mục nhập vì trang tiếp theo sẽ bỏ qua chúng. Vậy làm cách nào để đảm bảo rằng khóa sắp xếp là duy nhất có thể. Giải pháp tốt nhất là tạo một trường văn bản là duy nhất và sau đó tạo một hàm băm trên trường văn bản.
Đây là bài viết của mình tìm hiểu được, có thể sai xót nên mong mọi người góp ý. Chúc mọi người cuối tuần tốt lành.
Tài liệu tham khảo :
https://medium.com/everything-full-stack/elasticsearch-scroll-search-e92eb29bf773 https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-request-search-after.html
All rights reserved
