Tối ưu hoá Database với Indexs
Bài đăng này đã không được cập nhật trong 4 năm
Tối ưu hoá database (Performance tuning) là một vấn đề khó và không có một quy tắc. Việc Database quá tải còn dẫn đến nhiều thiệt hại khác, các hàng đợi (Queue) dài ra, file logs lớn. Những lỗi trên thông thường bắt nguồn từ khi định nghĩa Database (define) có hay không sử dụng Indexes một cách hợp lý. Khắc phục những thiếu sót trên, Hiệu năng ứng dụng sẽ cải thiện đáng kể.
Index trong SQL Server là một trong những yếu tố quan trọng nhất góp phần vào việc nâng cao hiệu suất của cơ sở dữ liệu. Index được tạo ra trên các cột trong bảng hoặc View, phương pháp giúp bạn nhanh chóng tìm kiếm dữ liệu dựa trên các giá trị trong các cột. Nếu không có Index, SQL Server sẽ thực hiện động tác quét qua toàn bộ bảng (table scan) để xác định vị trí dòng cần tìm, table scan là một trong những động tác có hại nhất cho hiệu suất của SQL Server.
Clustered index :
Loại index theo đó các bản ghi trong bảng được sắp thứ tự theo trường index. Clustered index không đòi hỏi phải duy nhất (unique Key). Nhưng khi nó không duy nhất thì khóa index được gắn thêm một giá trị 4-byte ngẫu nhiên để đảm bảo các node index vẫn là duy nhất. Bạn có thể tạo ra Clustered Index với câu lệnh sau :
CREATE CLUSTERED INDEX index_name ON dbo.Tablename(ColumnName1, ColumnName2...)
Non-Clustered Index :
Khác với clustered Index, non-Clustered Index không sắp xếp dữ liệu theo một trật tự vật lý như clustered Index. Mặc định thì primary key là clustered index còn foreign key là non-clustered index, do đó non-clustered index không mang tính duy nhất dữ liệu. Bạn có thể tạo ra Clustered Index với câu lệnh sau :
CREATE NONCLUSTERED INDEX index_name ON dbo.Tablename(ColumnName1, ColumnName2...)
Covering Indexes :
Khi một non-clustered index được dùng để thực thi một câu lệnh, ta thường thấy trong kế hoạch thực thi thao tác Key Lookup, là thao tác mà hệ thống sau khi tìm kiếm trên cây index nhảy tới bản ghi tương ứng trong bảng để lấy các trường dữ liệu cần trả về
SELECT ProductNumber,Name FROM [AdventureWorks].[Production].[Product] where ProductNumber = 'AR-5381'
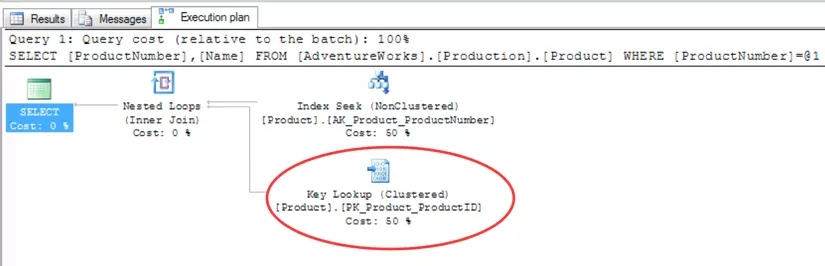
Ta thấy index IX_Product_ProductNumber trên trường ProductNumber đã được sử dụng (thao tác Index Seek). Tuy nhiên thao tác Key Lookup chiếm tới một 1/2 chi phí.
Phiên bản SQL Server 2005 bắt đầu bổ sung thêm lựa chọn INCLUDE trong lệnh CREATE INDEX để tăng khả năng covering của index :
CREATE NONCLUSTERED INDEX AK_Product_ProductNumber
ON AdventureWorks.Production.Product(ProductNumber)
INCLUDE (Name)
WITH (DROP_EXISTING = ON)
Khi thực hiện lại câu lệnh ở trên, kế hoạch thực thi đã thay đổi :
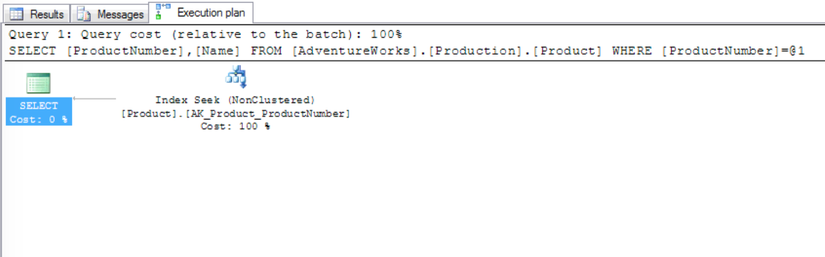
Filtered index :
Từ bản SQL Server 2008 bạn có thể dùng tính năng filtered index. Filtered index về bản chất là một non-clustered index nhưng cho phép chọn ra các bản ghi cần được index qua mệnh đề WHERE. Do vậy bạn có thể tạo một index như sau :
CREATE NONCLUSTERED INDEX AK_Product_ProductNumber
ON AdventureWorks.Production.Product(ProductNumber,SellStartDate)
INCLUDE (Name)
WHERE SellStartDate > '1998-06-01'
WITH (DROP_EXISTING = ON)
Tiêu chí chọn trường Index :
Vì Index có thể chiếm nhiều không gian lưu trữ, do đó không nên triển khai quá nhiều Index nếu như chúng không thực sự cần thiết. Ngoài ra, Index sẽ được tự động cập nhật khi bản thân các dòng dữ liệu được cập nhật, do đó có thể ảnh hưởng đến hiệu suất của quá trình xử lý dữ liệu. Khi tạo Index cần đạt được các tiêu chí sau :
-
Kích thước nhỏ: với clustered index tốt nhất là một trường kiểu số nguyên (INT hoặc BIGINT), lý tưởng nhất là tạo Clustered Index trên cột có thuộc tính Unique và khác Null.
-
Trường luôn tăng: Khi giá trị mới của trường clustered index luôn tăng lên, bản ghi mới luôn được thêm vào cuối hạn chế tình trạng phân mảnh dữ liệu.
-
Trường tĩnh: Clustered index không nên bị cập nhật thường xuyên, giá trị của nó nên được giữ nguyên. Khi nó bị cập nhật, cả clustered index và nonclustered index cần được cập nhật để sắp xếp vào vị trí mới cho đúng thứ tự dẫn đến tình trạng Index bị phân mảnh.
-
Tính duy nhất : Các giá trị trong một cột có tác động đến hiệu suất của Index, càng nhiều giá trị trùng lặp việc đọc từng bản ghi trở nên tốn kém hơn là quét bảng (table scan). Vì thế khi thấy độ selectivity thấp, bộ Optimizer sẽ tự động bỏ qua không dùng Index.
All rights reserved
