Tối ưu hoá câu lệnh MySQL P2
Bài đăng này đã không được cập nhật trong 4 năm
I. Cách để tái cấu trúc lại câu lệnh sql
I.1. Một câu lệnh phức tạp so với việc viết nhiều câu lệnh sql
- Một câu hỏi quan quan trọng cho việc thiết kế câu lệnh sql là liệu rằng có thể chia nhỏ câu lệnh truy vấn phức tạp thành nhiều câu lệnh truy vấn đơn giản hơn. Các phương pháp tiếp cận truyền thống thường là thiết kế làm sao để làm được nhiều việc nhất với ít câu truy vấn nhất có thể. Phương pháp này thích hợp với thời đại trước bởi vì network thời bấy giờ, chi phí cho cho việc parsing câu truy vấn cũng như việc tối ưu stages
- Thế nhưng nhưng những điều trên không đúng với MySQL bởi vì nó được thiết kế cho việc conect và disconnect rất hiệu quả. Network hiện nay cũng nhanh hiệu quả hơn rất nhiều so với trước đây, giảm độ trễ mạng. Phụ thuộc vào MySQL server version, MySQL có thể chạy hơn 100.000 câu truy vấn mỗi giây do đó việc chạy nhiều câu truy là hoàn toàn có thể chấp nhận được trên MySQL.
- Nhưng đôi khi việc việc sử dụng quá nhiều câu truy vấn cũng là một lỗi thông thường trong việc thiết kế, ví dụ như sử dụng rất nhiều câu truy vấn để lấy dữ liệu từ một bảng trong khi ta có thể dùng một câu lệnh đơn để lấy ra dữ liệu từ bảng.
I.2. Chia nhỏ câu lệnh JOIN
Bạn có thể có thể chạy nhiều câu lệnh truy vấn đơn thay vì chạy một câu lệnh JOIN phức tạp:
Multiple JOIN
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql';
Multiple single queries:
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id in (123,456,567,9098,8904);
Khi nhìn vào những câu truy vấn đơn bên dưới trông nó có vẻ tốn thời gian thực thị bởi lượng queries nhiều mà kết quả lấy ra không khác gì câu lệnh đơn. Thế nhưng việc chia nhỏ này có thể hiệu quả về mặt performance:
- Việc caching có thể hiệu quả hơn như ở ví dụ trên nếu object nào đó match với tag
mysqlđược cache lại thì ứng dụng có thể bỏ qua câu truy vấn đầu tiên, Nếu như những posts với id 123,456 được cached lại thì bạn có thể loại bỏ nó trong điều kiện IN ở câu lệnh truy vấn thứ 3. Không những thế nếu như chỉ một bảng dữ liệu thường xuyên thay đổi thì việc phân dã câu lệnh JON có thể làm giảm đi lượng cache không hợp lệ - Thực thi câu truy vấn riêng rẽ có thể làm giảm việc ganh khoá (lock contention)
- Câu lệnh trở nên hiệu quả hơn, như ở ví dụ trên sử dụng IN thay vì JOIN sẽ giúp MySQL sắp xếp rows theo IDS và lấy rows tối ưu hơn so với việc JOIN.
- Bạn có thể giảm việc access vào những dòng dữ liệu không cần thiết. Khi JOIN bạn sẽ phải lấy tất cả các dòng , việc JOIN có thể lặp lại việc access vào các dòng dữ liệu
II. Query Execution
- Nếu như như bạn cần tăng performance trong server MySQL thì cách tốt nhất là nên tìm hiểu MySQL đã tối ưu như thế nào và việc thực thi các câu lệnh truy vấn trên MySQL
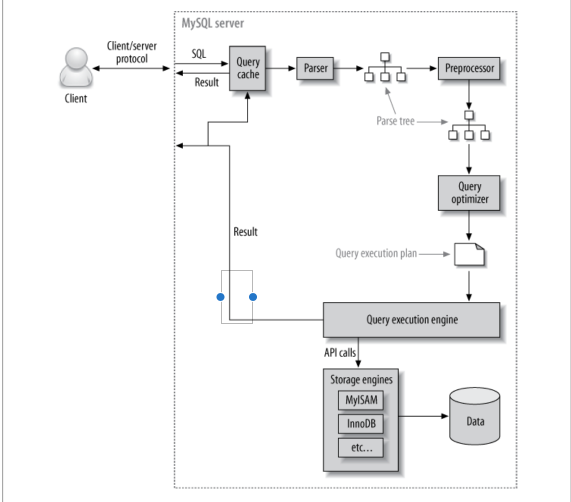
- Dưới đây là các step sẽ xảy ra khi client gửi một query đến server:
- Client gửi câu truy vấn tới server
- Server sẽ check query cache, nếu như cache hit nó sẽ trả về một store result từ cache ngược lại nó sẽ gửi câu lệnh truy vấn tới bước tiếp the
- Server thực hiện parse, tiền xử lý và tối ưu hoá câu lệnh SQL vào trong một query execution plan
- Tiếp đến query execution engine sẽ thực thi plan này bằng cách gọi storage engine API
- Cuối cùng server sẽ trả kết quả về cho client.
II.1. The MySQL Client/Server Protocol
- Để tối ưu hoá câu lệnh sql thì bạn cũng không cần thiết hiểu chi tiết bên trong MySQL Client/Server Protocol, nhưng bạn cũng nên hiểu cách làm việc của nó ở mức high level.
- Tại bất kỳ một thời điểm nào thì MySQL server chỉ có thể hoặc là gửi hoặc là nhận message, không thể cả 2 đồng thời xảy ra, điều đó có thể giải thích tại sao mà không thể chia nhỏ một message.
- Protocol giúp MySQL làm việc đơn giản và nhanh nhưng nó cũng có những giới hạn. Mỗi khi một bên gửi message thì phía bên kia phải nhận message trước khi có phản hồi lại. Đơn giản là bạn có thể hiểu nó giống như một trò chơi ném bóng khi bạn chưa nhận bóng thì bạn không thể ném bóng trở lại phía bên kia, trừ khi bạn nhận được bóng bạn mới có thể tiếp tục ném trả lại phía bên kia.
- Client sẽ gửi câu truy vấn tới server như một gói data packet đơn, đó là lý do tại sao mà việc config
max_allowed_packetlại trở nên quan trọng nếu như câu query của bạn quá lớn, server sẽ từ chối nhận data và trả về error. - Mỗi khi client gửi câu truy vấn đi thì nó chỉ có thể chờ đợi kết quả từ phía server gửi về, mặt khác khi phía server gửi respond thì client phải nhận toàn bộ result set. Nếu client chỉ cần một vài dòng dữ liệu thì hoặc là nó phải đợi cho đến khi toàn bộ server packet được gửi về, hoặc là phải ngắt kết nối đó là lí do vì sao mà LIMIT clause lại trở nên quan trọng khi bạn chỉ cần một số lượng nhỏ dữ liệu từ phía server.
- Khi client lấy các dòng dữ liệu từ phía server về, thì bạn thường nghĩ là client sẽ kéo data từ phía server nhưng sự thật là Server sẽ đẩy các dòng dữ liệu mà nó đã lấy ra về phía client, Client chỉ nhận các dòng dữ liệu được push về và không có cách nào có thể ngăn chặn được việc server gửi các dòng dữ liệu về phía client được.
- Hầu hết các thư việc connect tới MySQL đều cho phép bạn hoặc là fetch toàn bộ result set và buffer nó vào trong bộ nhớ, MySQL sẽ không giải phóng lock và những resource khác mà query cần. Query sẽ rơi vào trạng thái
sending data
II.2. Query states
- Mỗi một MySQL connection hay thread đều có state để chỉ ra nó làm gì tại mỗi thời điểm và có thể xem bằng câu lệnh sau
SHOW FULL PROCESSLIST. - Các trạng thái của MySQL:
SLEEP :
- Thread sẽ đợi query mới từ phía client
QUERY:
- Thread sẽ thực thi câu query hoặc là gửi data về phía client
LOCKED:
- Thread sẽ đợi một table lock được được cấp ở tầng server, Những locks này được thực thi bở storage engien ví dụ như InnoDB row locks.*
ANALYZING AND STATISTICS:
- Thread kiểm tra thông kê trên storage eqngine và tối ưu hoá câu query
COPY TO TMP TABLE:
- Thread xử lý query và copy kết quả sang một bảng tạm như việc
GROUP BYhay UNION. Nếu như state kết thúc với “on disk" MySQL sẽ convert một table từ memory sang một table “on-disk". SORTING RESULT: - Thread sẽ làm nhiệm vụ sắp xếp result set. SENDING DATA: - Thread có thể gửi data giữa các states của query, tạo ra result set hoặc là trả result set về phía client.
II.3. Query Optimization Process
Sau khi bước query được đọc từ cache ra sẽ là bước execution plan, ở bước này sẽ có một vài bước nhỏ: parsing, preprocessing, optimization.
II.3.1. Parser và preprocessor
- MySQL parser sẽ chuyển query thành token và build thành một “parse tree". Parser sử dụng ngữ pháp MySQL' SQL để thông dịch và validate câu query. Ví dụ để đảm boả rằng tokens của query là valid và theo thứ tự thích hợp nó sẽ kiểm tra các lỗi như các quoted string mà chưa đóng chẳng hạn
- Preprocessor sau đó kiểm tra kết quả parse tree mà parser chưa thể giải quyết. Ví dụ nó kiểm tra sự tồn tại của bảng, cột và đặt tên alias đẻ đảm bảo các cột tham chiếu trở nên rõ ràng.
- Tiếp theo Preprocessor kiểm tra quyền, thông thường thì bước này sẽ rất nhanh trừ khi server có quá nhiều các quyền.
II.3.2. Query optimizer
- Ở bước này thì parser tree đã valid và sẵn sàng tối ưu và biến nó thành một query execution plan. Một query có thể được thực thi bởi rất nhiều các khác nhau và trả về cùng một kết quả. Và công việc của optimizer là tìm ra một cách tốt nhất.
- MySQL sử dụng cost-based optimizer, có nghĩa là nó sẽ dự đoán cost của các execution plan khác nhau và chọn ra một phương án tốn ít chi phí nhất. Bạn có thể xem query cost bằng cách sau
mysql> SELECT SQL_NO_CACHE COUNT(*) FROM sakila.film_actor;
+----------+
| count(*) |
+----------+
| 5462 |
+----------+
mysql> SHOW STATUS LIKE 'Last_query_cost';
+----------------------------+-------------+
| Variable_name | Value |
+----------------------------+-------------+
| Last_query_cost | 1040.599000
| +--------------------------+-------------+
Kết quả này nghĩa là optimizer estimated có thể cần tới 1040 random data page read để thực thi câu query. Nó estimate dựa trên việc thống kê: số trang trên mỗi bảng hoặc index, số lượng các dòng, khoá, và key distribution. Optimizer không bao gồm bất cứ một loại cache nào trong estimate của nó, và có thể xem như nó đọc dữ liệu từ disk I/O operation.
Tham Khảo
Bài viết được tham khảo từ cuốn sách High Performance MySQL
All rights reserved
