Tối ưu Context trong RAG bằng Cross-Encoder: Cách lọc nhiễu hiệu quả cho hệ thống AI
Khi xây dựng hệ thống RAG hoặc pipeline tạo context cho LLM, một vấn đề phổ biến là kết quả truy xuất từ vector database “trông có vẻ liên quan” nhưng thực chất lại sai ngữ cảnh. Những đoạn này không hoàn toàn vô nghĩa, nhưng đủ nhiễu để làm giảm chất lượng câu trả lời của mô hình.
Bài viết này trình bày cách ứng dụng Cross-Encoder như một tầng re-ranking, giúp loại bỏ thông tin dư thừa, giữ lại context thực sự phù hợp trước khi đưa vào LLM.
Vấn đề thực tế khi xây context từ vector search
Một pipeline RAG tiêu chuẩn thường có dạng:
User Query → Embedding → Vector Search → Top-k Documents → Context → LLM
Vấn đề nằm ở bước Vector Search. Vector database chỉ đo độ tương đồng hình học trong không gian embedding, chứ không đánh giá mức độ liên quan về mặt ngữ nghĩa sâu.
Hệ quả thường gặp:
- Context chứa nhiều đoạn “gần nghĩa” nhưng sai trọng tâm
- Prompt dài, lãng phí token
- LLM bị phân tán attention, dẫn đến hallucination
- Chi phí inference tăng không cần thiết
Nói cách khác, vector search giỏi tìm ứng viên, nhưng không giỏi chọn đoạn tốt nhất.
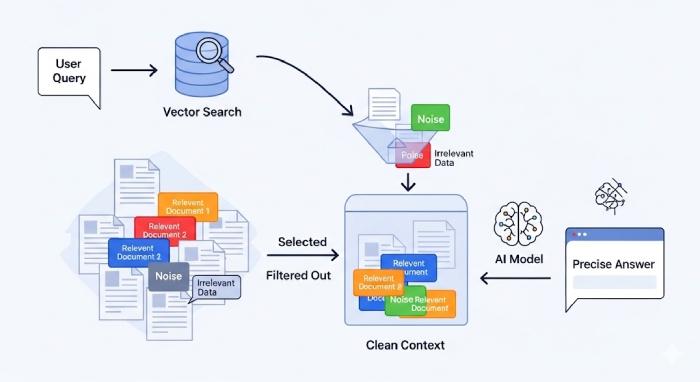
Cross-Encoder giải quyết bài toán lọc nhiễu như thế nào?
Khác biệt cốt lõi giữa Bi-Encoder và Cross-Encoder
Bi-Encoder
- Encode query và document độc lập
- So sánh embedding bằng cosine / dot-product
- Rất nhanh, phù hợp cho tìm kiếm quy mô lớn
- Độ chính xác ngữ nghĩa có giới hạn
Cross-Encoder
- Nhận query + document cùng lúc
- Đánh giá trực tiếp mức độ liên quan
- Chính xác cao, nhưng tốn tài nguyên
- Không phù hợp để chạy trên toàn bộ dữ liệu
Cross-Encoder hoạt động giống như một reviewer: đọc cả câu hỏi và đoạn văn rồi mới chấm điểm, thay vì chỉ so embedding.
Kiến trúc khuyến nghị: Two-stage Retrieval
Trong thực tế, Cross-Encoder nên được dùng như tầng lọc cuối, kết hợp với Bi-Encoder:
- Bi-Encoder: truy xuất nhanh top 30–50 documents
- Cross-Encoder: re-rank và chọn ra top 3–5 đoạn tốt nhất
- Ghép các đoạn này thành context cuối
Cách tiếp cận này cân bằng tốt giữa tốc độ – độ chính xác – chi phí.
Pipeline tích hợp Cross-Encoder trong RAG
Quy trình triển khai phổ biến:
- Nhận query từ người dùng
- Encode query bằng Bi-Encoder
- Vector search lấy top-k candidates
- Tạo cặp (query, document)
- Dùng Cross-Encoder chấm điểm từng cặp
- Sắp xếp lại và giữ top-n đoạn liên quan nhất
- Xây context và gửi vào LLM
Ví dụ Python (đơn giản hóa)
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
pairs = [(query, doc) for doc in retrieved_docs]
scores = model.predict(pairs)
reranked = sorted(
zip(retrieved_docs, scores),
key=lambda x: x[1],
reverse=True
)
final_context = [doc for doc, _ in reranked[:5]]
Trong hệ thống thực tế, bước này thường được bọc trong một service riêng (API hoặc worker).
Lợi ích thực tế khi dùng Cross-Encoder
- Context ngắn gọn, đúng trọng tâm
- Giảm đáng kể nhiễu ngữ nghĩa
- LLM trả lời chính xác và nhất quán hơn
- Kiểm soát tốt số token đưa vào prompt
- Dễ tinh chỉnh ngưỡng chất lượng theo từng use case
Đặc biệt hiệu quả với:
- FAQ nội bộ
- Trợ lý doanh nghiệp
- Knowledge base nhiều tài liệu tương tự nhau
- Dataset có nhiều đoạn “na ná” về mặt embedding
Lưu ý triển khai dành cho Developer
- Không dùng Cross-Encoder trên toàn bộ corpus
- Chỉ re-rank tập nhỏ (≤50 documents)
- Nên tách Cross-Encoder thành service độc lập
- Áp dụng cache cho query lặp
- Log kết quả trước & sau re-ranking để debug
- Theo dõi latency vì Cross-Encoder chạy theo batch size
Tổng kết
Trong hệ thống RAG, retrieval tốt chưa đủ – context sạch mới quyết định chất lượng đầu ra. Cross-Encoder đóng vai trò như một bộ lọc tinh, loại bỏ các đoạn “có vẻ đúng nhưng thực chất sai”. Kết hợp Bi-Encoder để tìm nhanh và Cross-Encoder để chọn chuẩn, bạn có thể xây dựng pipeline RAG:
- Chính xác hơn
- Ít hallucination hơn
- Tiết kiệm token và chi phí
- Dễ mở rộng trong môi trường production
Đây là một bước tối ưu quan trọng mà bất kỳ hệ thống AI dựa trên retrieval nào cũng nên cân nhắc triển khai.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-dung-cross-encoder-de-loai-bo-thong-tin-nhieu-khi-xay-context.html
All rights reserved
