Tối ưu Chunking trong RAG: Hướng dẫn thiết kế kích thước đoạn văn bản chuẩn cho Developer
Trong các kiến trúc Retrieval-Augmented Generation (RAG) hay các pipeline NLP phức tạp, việc tách tài liệu thành các đoạn nhỏ (chunk) luôn là bước tiền xử lý quan trọng. Tuy nhiên, đa số hệ thống gặp vấn đề ở ngay bước đơn giản này: chọn chunk quá nhỏ dẫn đến mất ngữ cảnh, chọn chunk quá lớn lại làm tăng chi phí lưu trữ và suy giảm độ chính xác khi truy vấn. Bài viết dưới đây trình bày quy trình tối ưu kích thước chunk theo hướng thực nghiệm, một cách tiếp cận phù hợp cho developer khi cần triển khai hoặc tinh chỉnh RAG trong môi trường thực tế.
Vì sao xác định chunk_size là bước tối quan trọng trong RAG?
Trong bất kỳ hệ thống vector search nào từ semantic search, QA system cho đến AI Agent có khả năng lưu nhớ dài hạn, chunk là đơn vị được dùng để sinh embedding và phục vụ truy xuất.
Chunk quá nhỏ khiến LLM khó hiểu toàn bộ ngữ cảnh. Chunk quá lớn lại làm nhiễu embedding và tăng chi phí xử lý.
Ảnh hưởng trực tiếp của chunk_size & chunk_overlap:
- Độ chính xác của truy vấn (retrieval precision/recall)
- Khả năng mô hình tái hiện ngữ cảnh đầy đủ
- Tốc độ và chi phí embedding
- Khả năng mở rộng hệ thống khi dữ liệu tăng trưởng
Vì vậy, việc chọn cấu hình chunk không thể làm theo cảm tính, cần đo lường bằng thực nghiệm.

Chunk_size & Chunk_overlap – hai tham số cốt lõi
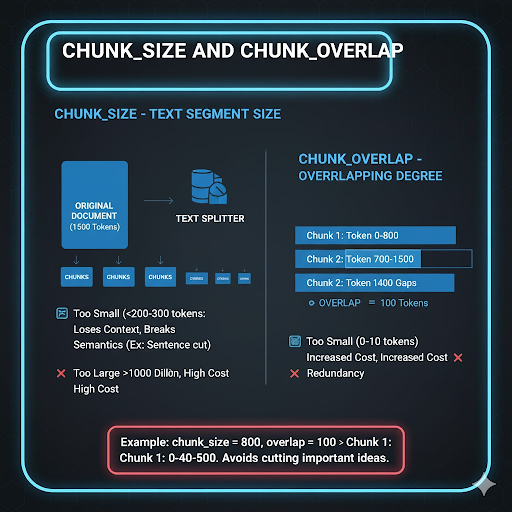
Chunk_size – kích thước đoạn văn bản tách từ tài liệu gốc
Thông thường được tính theo token hoặc ký tự.
- Chunk nhỏ → Dễ mất ngữ cảnh
- Chunk lớn → Embedding chứa quá nhiều thông tin hỗn tạp, vector database phình to nhanh chóng
Chunk_overlap – vùng chồng lấn giữa hai chunk liên tiếp
Overlap giúp tránh cắt rời các ý quan trọng khi chunk bị chia đúng điểm không phù hợp.
Ví dụ cấu hình:
chunk_size = 800
overlap = 100
Chunk 1: 0–800
Chunk 2: 700–1500
Overlap quá nhỏ làm đứt mạch thông tin; overlap quá lớn gây trùng lặp nặng và tốn tài nguyên.
Thiết kế thí nghiệm tìm ra kích thước chunk tối ưu
Dev nên áp dụng phương pháp thực nghiệm có kiểm soát thay vì chọn tùy hứng. Quy trình chuẩn:
Bước 1 – Chuẩn bị dữ liệu
- Tập tài liệu: 10–20 documents, độ dài 2.000–10.000 token
- Tập truy vấn: 50–100 câu hỏi có ground-truth rõ ràng
- Loại dữ liệu có thể là nội dung kỹ thuật, hướng dẫn sử dụng, hoặc transcript hội thoại
Bước 2 – Tạo danh sách cấu hình để thử nghiệm
| chunk_size | chunk_overlap |
|---|---|
| 200 | 50 |
| 400 | 100 |
| 800 | 100 |
| 800 | 200 |
| 1200 | 200 |
Bước 3 – Chunking, tạo embedding và thực hiện truy vấn
Dùng LangChain, LlamaIndex hoặc Haystack:
- Chunk tài liệu theo từng cấu hình
- Sinh embedding và lưu vào vector DB (Chroma, Pinecone, FAISS)
- Truy vấn top-k: 3 hoặc 5
- Đánh giá với ground truth
Các chỉ số cần thu thập:
- Precision
- Recall
- F1-Score
- MAP (nếu tập query đủ lớn)
Bước 4 – Tổng hợp & phân tích kết quả
| chunk_size | overlap | Precision | Recall | F1 | MAP | Kết luận |
|---|---|---|---|---|---|---|
| 200 | 50 | 0.72 | 0.60 | 0.65 | 0.66 | Thiếu ngữ cảnh |
| 400 | 100 | 0.81 | 0.77 | 0.79 | 0.80 | Cân bằng |
| 800 | 100 | 0.86 | 0.82 | 0.84 | 0.85 | Ổn định, hiệu quả |
| 800 | 200 | 0.87 | 0.83 | 0.85 | 0.86 | Tốt nhưng chi phí cao |
| 1200 | 200 | 0.82 | 0.89 | 0.85 | 0.84 | Dư thừa dữ liệu |
Nhận xét: Cấu hình ~800 token kết hợp với overlap 100–200 thường cho kết quả cân bằng nhất.
Bước 5 – Kiểm thử chéo (cross-validation)
Sau khi chọn cấu hình tốt nhất, hãy thử lại với bộ dữ liệu khác. Nếu kết quả giảm mạnh → cấu hình đang overfit → cần tinh chỉnh lại.
Các chiến lược nâng cao để chunking hiệu quả hơn
1. Chunk theo ngữ nghĩa (Semantic Chunking)
Sử dụng embedding để gom các câu gần nghĩa vào cùng chunk.
Ưu điểm: giữ ngữ cảnh tự nhiên Nhược điểm: tốn thêm bước tính toán similarity
Chunk theo cấu trúc tài liệu
Chia theo heading, sub-heading, danh sách bullet, bảng biểu… Phù hợp tài liệu kỹ thuật hoặc SOP.
Sliding Window
Giữ chunk_size cố định, chỉ thay đổi bước trượt (step).
Ví dụ:
chunk_size = 800
step = 600 # overlap 200
Adaptive Chunking – tự điều chỉnh động
Dành cho hệ thống RAG sản xuất: theo dõi log và tự thay đổi chunk_size dựa trên:
- Tỉ lệ chunk không được dùng
- Sai lệch truy vấn
- Chi phí embedding
- Đặc tính nguồn dữ liệu mới
Kết hợp nhiều phương pháp
Ví dụ:
- Chunk theo heading → sau đó chia nhỏ theo token
- Semantic chunk → áp dụng overlap động
Code minh họa quy trình thử nghiệm
def chunk_text(text, chunk_size, overlap):
chunks = []
start = 0
while start < len(text):
end = min(start + chunk_size, len(text))
chunks.append(text[start:end])
start += chunk_size - overlap
return chunks
configs = [(200,50),(400,100),(800,100),(800,200),(1200,200)]
results = []
for cs, ov in configs:
all_chunks = [chunk_text(doc, cs, ov) for doc in documents]
vector_db = build_vector_db(all_chunks)
metrics = evaluate_retrieval(vector_db, queries, ground_truth)
results.append({"chunk_size": cs, "overlap": ov, **metrics})
best = max(results, key=lambda r: r['F1'])
print("Best configuration:", best)
Lỗi thường gặp khi lựa chọn chunk
| Sai lầm | Hệ quả | Cách khắc phục |
|---|---|---|
| Chọn kích thước tùy hứng | Mất ngữ cảnh hoặc dư thừa dữ liệu | Luôn có quy trình test |
| Overlap quá lớn | Trùng dữ liệu, tăng chi phí embedding | Giữ overlap khoảng 10–25% chunk_size |
| Cắt chunk giữa câu/bảng biểu | Ngữ nghĩa bị méo | Chunk theo dấu câu/heading |
| Không cập nhật chunk khi đổi embedding model | Không tương thích | Điều chỉnh theo token limit của model mới |
Gợi ý cấu hình theo từng loại tài liệu
| Loại nội dung | chunk_size | overlap | Lưu ý |
|---|---|---|---|
| FAQ / Chatbot CSKH | 300–500 | 50–100 | Ngữ cảnh ngắn |
| Tài liệu kỹ thuật | 600–900 | 100–200 | Cần continuity |
| Báo cáo học thuật | 1000–1200 | 150–250 | Logic chặt chẽ |
| Transcript hội thoại | 200–400 | 50–100 | Tách theo lượt nói |
Kết luận
Tối ưu chunking không chỉ là bài toán chia văn bản mà là một phần quan trọng quyết định độ chính xác và chi phí của toàn bộ hệ thống RAG. Với cách tiếp cận theo hướng thử nghiệm từ chuẩn bị dữ liệu, xác định cấu hình, đánh giá đến kiểm thử chéo – developer có thể tìm được cấu hình chunk_size và overlap phù hợp nhất cho từng loại dự án và mô hình embedding.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-toi-uu-kich-thuoc-chunk-trong-rag-ly-tuong.html
All rights reserved
