tôi làm code 241211
Object detection
https://ai.gopubby.com/making-llms-more-truthful-with-dola-the-math-stuff-part-ii-4b66a12d1197
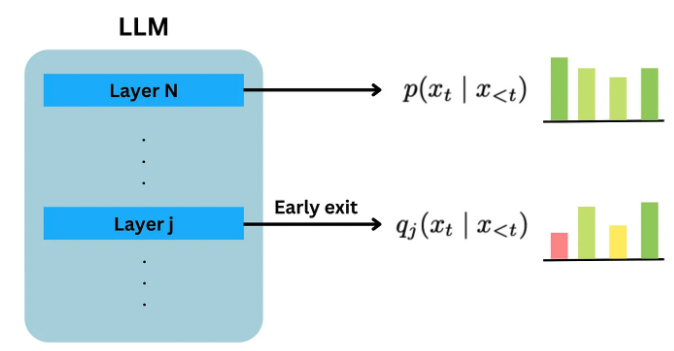
https://ai.gopubby.com/my-llms-outputs-got-1000-better-with-this-simple-trick-8403cf58691c
các topic cũng khá hay: Layer Selection , Contrasting the Predictions, Contrastive Decoding and Filtering function
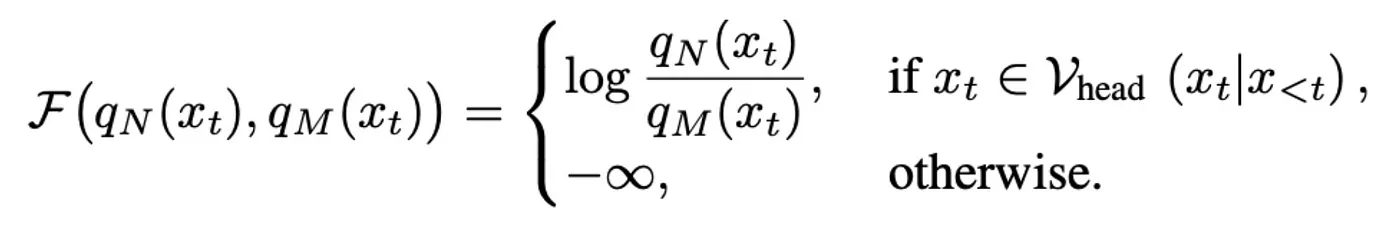
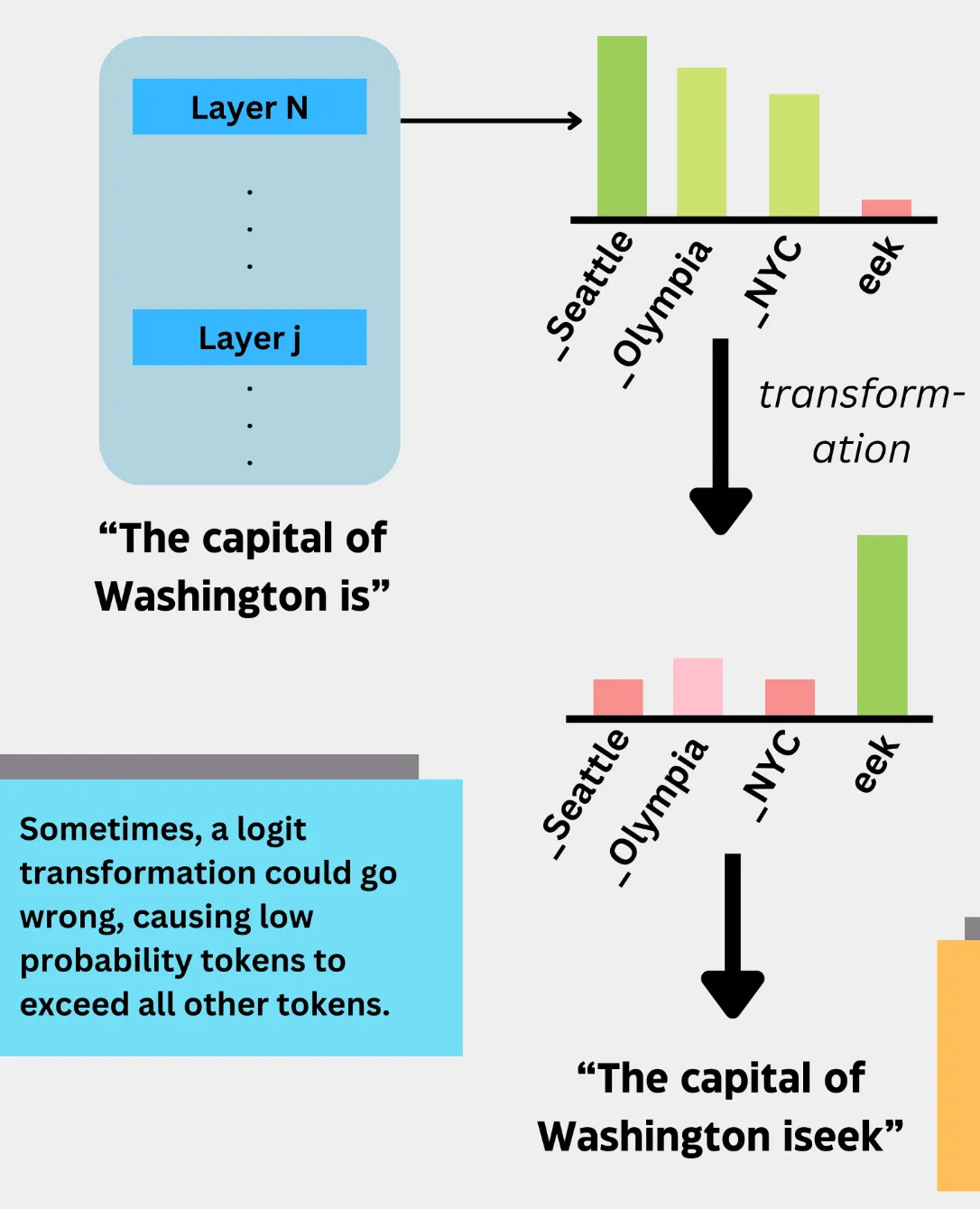
- Chỉ mới lướt qua, mà thấy cũng hay, cách giao giữa các model và loại dữ liệu.
https://github.com/ShawhinT/YouTube-Blog/blob/main/multimodal-ai/3-multimodal-rag/functions.py#L205
def embed_text(text):
"""
Convet text to embeddings using CLIP
"""
# import model
model = CLIPTextModelWithProjection.from_pretrained("openai/clip-vit-base-patch16")
# import processor (handles text tokenization and image preprocessing)
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")
# pre-process text and images
inputs = processor(text=[text], return_tensors="pt", padding=True)
# compute embeddings with CLIP
outputs = model(**inputs)
return outputs.text_embeds
Hiểu về https://modal.com/docs/examples/llm-finetuning
Parameter-Efficient Fine-Tuning (PEFT) via LoRA adapters for faster convergence Flash Attention for fast and memory-efficient attention during training (note: only works with certain hardware, like A100s) Gradient checkpointing to reduce VRAM footprint, fit larger batches and get higher training throughput Distributed training via DeepSpeed so training scales optimally with multiple GPUs
All rights reserved
