Tìm hiểu về Semantic Annotation - Phần 2: Cách thức Semantic Annotation hoạt động
Bài đăng này đã không được cập nhật trong 6 năm
Ở bài trước, mình đã giới thiệu sơ qua về khái niệm Semantic Annotation là gì, và một số ứng dụng của Semantic Annotation Trong bài này, mình sẽ viết về cách thức Semantic Annotation làm việc và trình bày nó một cách đơn giản và dễ hiểu nhất!
1: Ví dụ đơn giản
Để dễ hiểu, ta sẽ bắt đầu từ các ví dụ đơn giản nhất:
Nguyễn Sinh Cung được sinh ra tại Nghệ An năm 1890, người mà sau này trở thành chủ tịch Hồ Chí Minh, vị lãnh tụ vĩ đại của Việt Nam.
Là một người bình thường, ta có thể dễ dàng hiểu được ý nghĩa của câu trên. Tuy nhiên, với máy tính, câu văn tưởng chừng đơn giản trên lại rất phức tạp. Máy tính phải có được nhận thức rằng "Nguyễn Sinh Cung" , "Hồ Chí Minh" là con người và là cùng một người , Nghệ An , Việt Nam là địa danh, "sinh ra" - "trở thành" là các động từ nối, liên kết chủ ngữ với các địa danh trên... Mới kể ra thôi mà đã thấy thật là phức tạp, đúng không? Vậy ta sẽ cùng thử xem Semantic Annotaion hoạt động như thế nào nhé
2: Cách thức Semantic Annotation hoạt động
Semantic Annotation làm giàu nội dung thông tin có thể xử lý bằng máy bằng cách liên kết thông tin cơ bản với các khái niệm được trích xuất. Những khái niệm này, được tìm thấy trong một tài liệu hoặc một phần nội dung khác, được xác định rõ ràng và liên quan với nhau trong và ngoài nội dung. Nó biến nội dung thành một nguồn dữ liệu dễ quản lý hơn. Trong bài này, mình sẽ chỉ nói về cách thức nó trích xuất và xử lý dữ liệu, còn cách quản lý và lưu trữ dữ liệu mình sẽ nói trong một bài khác nhé!
1. Tiền xử lý dữ liệu
Bất kỳ công cụ nào, đều phải có bước tiền xử lý dữ liệu. Semantic Annotation coi việc tiền xử lý dữ liệu là bước nhận diện văn bản. Tức là các dữ liệu như hình ảnh, video, âm nhạc... đều được chuyển thành văn bản. Văn bản này thường là văn bản phi cấu trúc. Ví dụ, sau khi tiền xử lý dữ liệu ta có đoạn văn bản sau:

2. Phân tích văn bản
Thực hiện phân tích dữ liệu ngữ nghĩa: Chia tách câu, gắn tag các đối tượng, thực hiện nhận dạng thực thể được đặt tên.

Thuật toán phân tách câu và xác định các khái niệm như người, vật, địa điểm, sự kiện, số, v.v. Như trên ví dụ, thuật toán nhận diện: Rome, Roman Empire là các thực thể, 400000km là các con số...
3. Trích xuất khái niệm
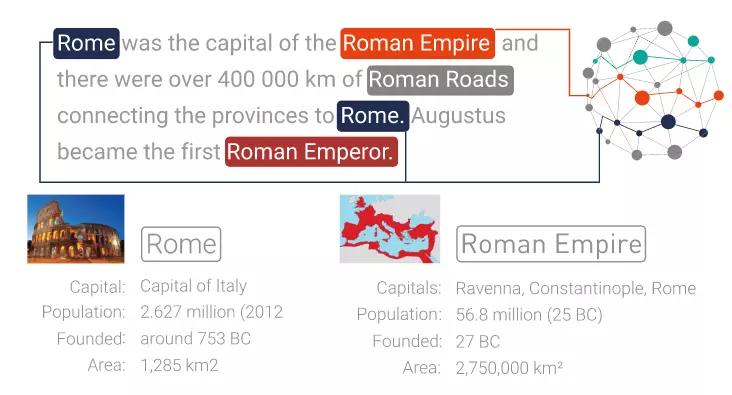
Tất cả các khái niệm được thừa nhận sẽ được phân loại, đó là chúng được xác định như là con người, các tổ chức, các con số… Tiếp theo, chúng được làm sáng tỏ, đó là chúng được xác định một cách rõ ràng không mù mờ theo cơ sở tri thức đặc thù lĩnh vực. Ví dụ, Rome được phân loại như là thành phố và được làm sáng tỏ tiếp như là Rome, nước Ý chứ không phải Rome, Iowa.
Đây là giai đoạn quan trọng nhất của chú giải ngữ nghĩa. Nó rất giống với Nhận dạng Thực thể Được đặt tên - NER (Named Entity Recognition) nhưng là khác vì nó không chỉ thừa nhận các đoạn văn bản mà còn làm cho chúng trở thành các mẩu dữ liệu có thể hiểu được và máy tính có thể xử lý được bằng cách liên kết chúng với các tập hợp rộng lớn hơn các dữ liệu đang tồn tại rồi.
4. Trích xuất quan hệ
Các mối quan hệ giữa các khái niệm được trích xuất sẽ được nhận diện và được liên kết với tri thức theo lĩnh vực có liên quan cả bên trong và bên ngoài.
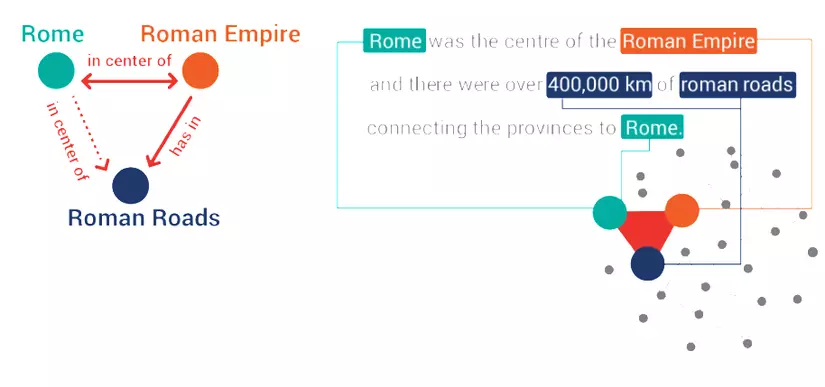
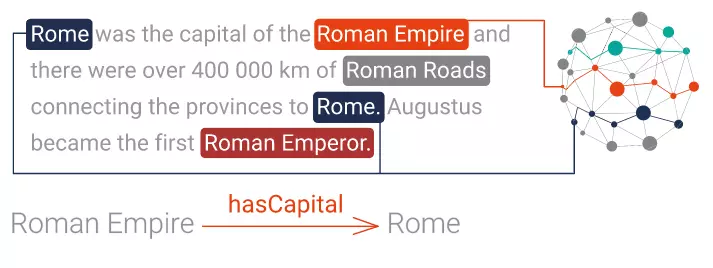
Trong ví dụ trên ta có 3 địa điểm là : Rome - Roman Empire - Roman Roads và có quan hệ như trong hình. Từ đây, ta có thể rút được ra rất nhiều quan hệ, một ví dụ đơn giản nhất là :
5. Đánh chỉ số và lưu trữ trong cơ sở dữ liệu đồ họa ngữ nghĩa
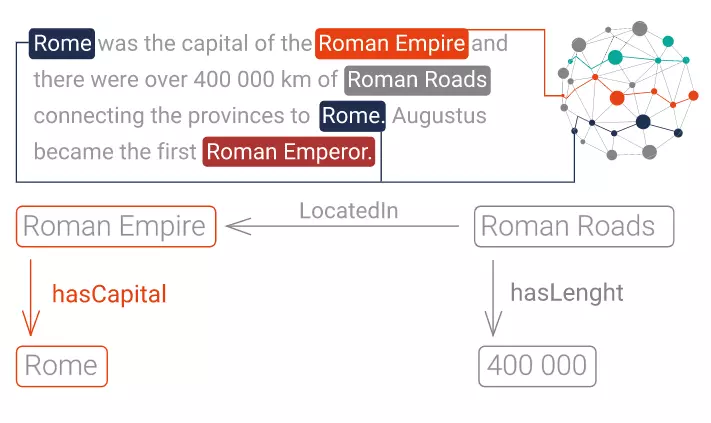
Sau khi đã có các khái niệm, các quan hệ giữa các khái niệm. Ta sẽ thực hiện đánh chỉ số và lưu trữ dữ liệu. Tất cả các dữ liệu được thừa nhận và được làm giàu cùng với các dữ liệu máy tính đọc được đề cập tới con người, các đồ vật, các con số … và các mối quan hệ giữa chúng sẽ được đánh chỉ số và được lưu trữ trong cơ sở dữ liệu đồ họa ngữ nghĩa để tham chiếu và sử dụng sau đó.
Chú thích ngữ nghĩa được dùng ở đâu
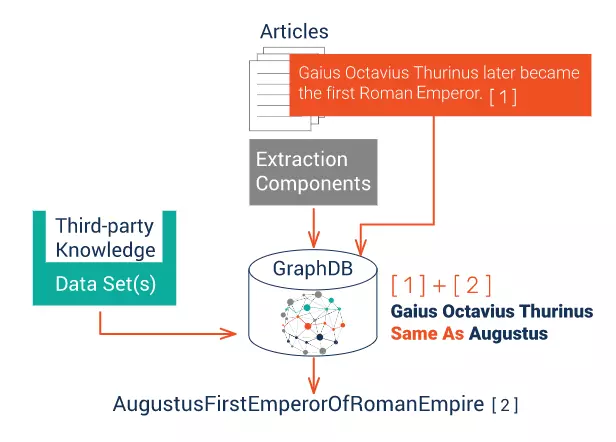
Những gì chú giải ngữ nghĩa mang tới là các mẩu dữ liệu thông minh chứa các chú giải có cấu trúc cao và có đầy đủ thông tin cho các máy tính để tham chiếu tới. Semantic Annotation được sử dụng rộng rãi để phân tích rủi ro, khuyến cáo nội dung, phát hiện nội dung, dò tìm sự tuân thủ điều chỉnh pháp lý và hơn thế nữa.
Nội dung được chú giải có hệ thống mở ra các cơ hội có hiệu quả về chi phí:
* Tìm kiếm vượt ra khỏi các từ khóa
* Tổng hợp nội dung vượt ra khỏi việc sàng lọc bằng tay
* Phát hiện các mối quan hệ vượt ra khỏi nghiên cứu của con người
Semantic Annotation có thể sử dụng dễ dàng để:
* Tìm ra thông tin thích hợp giữa hàng núi các tài liệu với sự trợ giúp của máy tính để làm hộ các công việc phải đi đây đi đó
* Trích xuất tri thức từ các nguồn rời rạc phân tán
* Cung cấp nội dung được cá nhân hóa, dựa vào ngữ cảnh máy tính hiểu được
* Tự động kết nối các nội dung liên quan lẫn nhau
Bài biết có tham khảo từ: https://www.ontotext.com/knowledgehub/fundamentals/semantic-annotation/
All rights reserved
