Tìm hiểu về Inverted Index trong Elasticsearch
Bài đăng này đã không được cập nhật trong 6 năm
Tìm hiểu về Inverted Index trong Elasticsearch
Bài viết được dịch từ nguồn: https://codingexplained.com/coding/elasticsearch/understanding-the-inverted-index-in-elasticsearch
1. Mở đầu
Nếu bạn đã từng đọc how analyzers work in Elasticsearch trước khi đọc post này, bạn sẽ biết cách mà Elasticsearch phân tích các trường văn bản. Khi đó bạn có thể tự hỏi điều gì thực sự xảy ra với các kết quả trong quá trình phân tích. Cuối cùng chúng phải được lưu trữ ở đâu đó, chắc chắn rồi. Các kết quả từ việc phân tích thực sự được lưu trữ ở đâu đó; trong một cái gì đó được gọi là inverted index - chỉ số đảo ngược. Nghe có vẻ rất lạ và trừu tượng, nhưng một khi tôi chỉ cho bạn một minh họa đơn giản, bạn sẽ thấy rằng nó thực sự không phức tạp lắm.
2. Mục đích của một inverted index
Mục đích của một inverted index , là lưu trữ văn bản trong một cấu trúc cho phép tìm kiếm toàn văn bản rất hiệu quả và nhanh chóng. Khi thực hiện tìm kiếm toàn văn bản, chúng tôi thực sự đang truy vấn một inverted index chứ không phải các tài liệu JSON mà chúng tôi đã xác định khi lập index cho các tài liệu. Lý do tại sao tôi nói một inverted index , là bởi vì một cụm sẽ có ít nhất một inverted index . Bởi vì sẽ có một inverted index cho mỗi trường toàn văn cho mỗi index. Vì vậy, nếu bạn có một index chứa các tài liệu chứa năm trường toàn văn bản, bạn sẽ có năm inverted index .
Một inverted index bao gồm tất cả các thuật ngữ duy nhất xuất hiện trong bất kỳ tài liệu nào được bao phủ bởi index. Đối với mỗi thuật ngữ, danh sách các tài liệu trong đó thuật ngữ xuất hiện, được lưu trữ. Vì vậy, về cơ bản, một inverted index là một ánh xạ giữa các điều khoản và tài liệu nào chứa các điều khoản đó. Vì một inverted index hoạt động ở cấp trường tài liệu và lưu trữ các thuật ngữ cho một trường nhất định, nên nó không cần phải xử lý các trường khác nhau. Vì vậy, những gì bạn sẽ thấy trong ví dụ sau là ở phạm vi của một lĩnh vực cụ thể.
Ví dụ: Giả sử rằng chúng ta có hai công thức nấu ăn với các tiêu đề sau: “The Best Pasta Recipe with Pesto” and “Delicious Pasta Carbonara Recipe.” . Bảng sau đây cho thấy inverted index sẽ như thế nào.
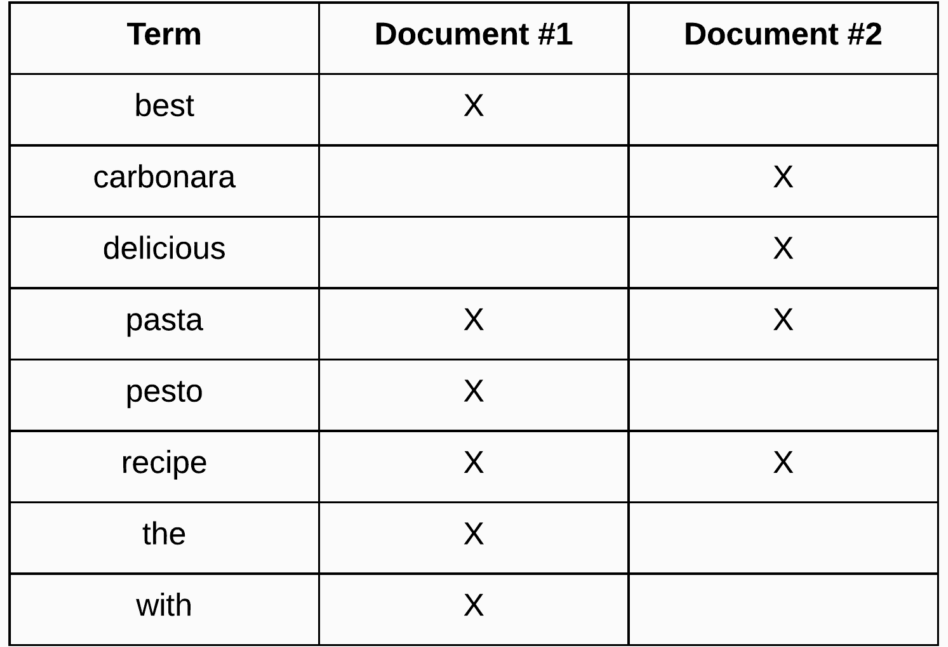
Vậy, các điều khoản từ cả hai tiêu đề đã được thêm vào index. Đối với mỗi thuật ngữ, chúng tôi có thể xem tài liệu nào chứa thuật ngữ này, cho phép Elaticsearch search hiệu quả với các tài liệu có chứa các thuật ngữ cụ thể. Một phần của những gì làm cho điều này có thể, là các điều khoản được sắp xếp. Cũng lưu ý rằng các thuật ngữ trong index là kết quả của quá trình phân tích mà bạn đã thấy trong bài viết trước trong trường hợp bạn đọc từ đó. Vì vậy, hầu hết các biểu tượng đã bị xóa tại thời điểm này và các ký tự đã được hạ xuống. Điều này tất nhiên phụ thuộc vào máy phân tích đã được sử dụng, nhưng đó thường sẽ là máy phân tích tiêu chuẩn.
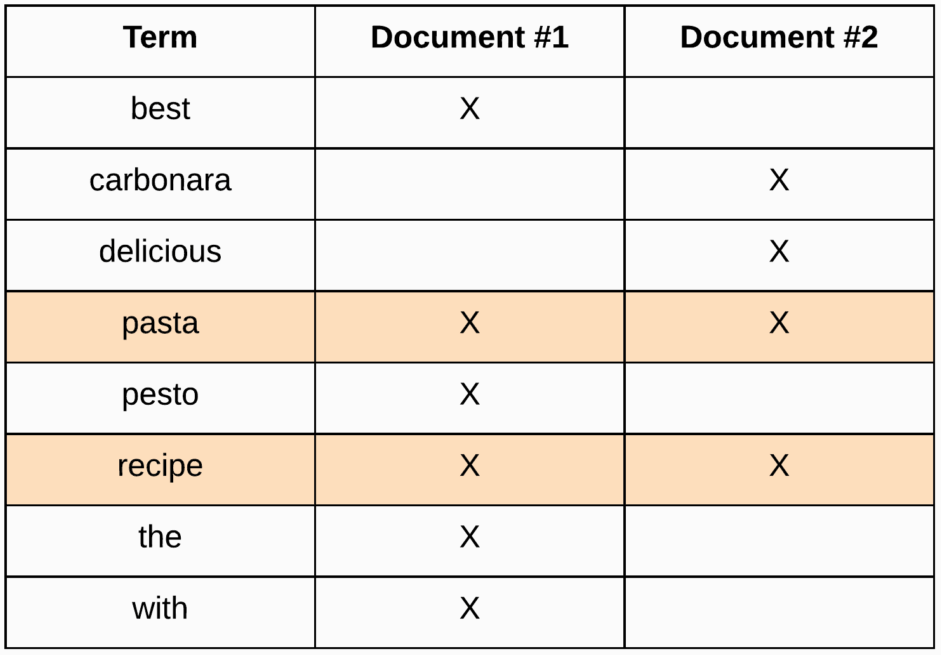
Việc thực hiện tìm kiếm liên quan đến rất nhiều thứ như mức độ liên quan, nhưng bây giờ hãy để quên đi điều đó. Bước đầu tiên của truy vấn tìm kiếm là tìm tài liệu khớp với truy vấn ở vị trí đầu tiên. Vì vậy, nếu chúng ta tìm kiếm "pasta recipe", thì chúng ta sẽ thấy rằng cả hai tài liệu đều chứa cả hai thuật ngữ.
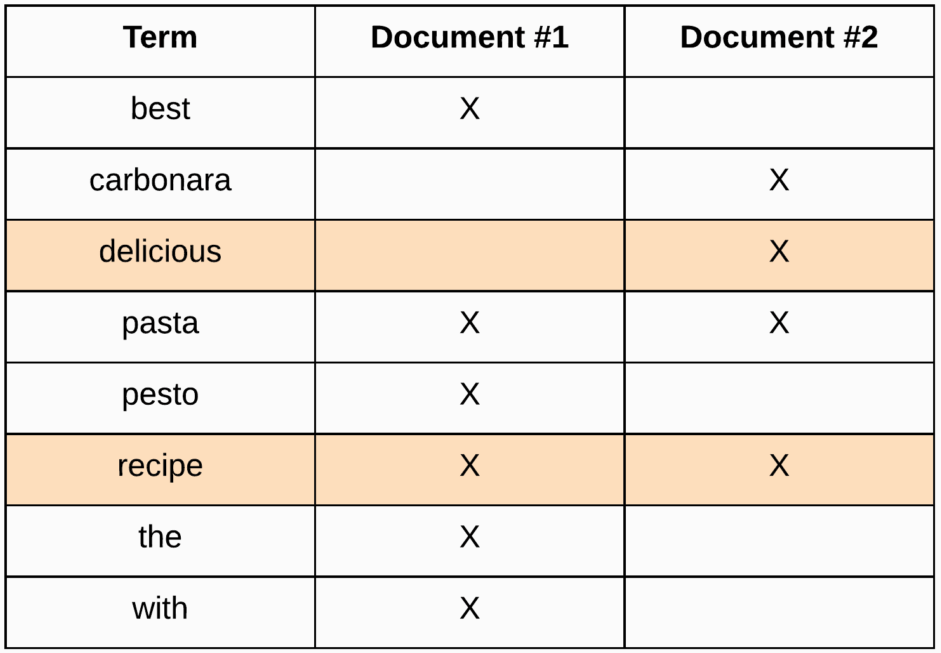
Nếu chúng ta tìm kiếm theo thuật ngữ “delicious recipe” thì kết quả sẽ như sau:
3. Kết luận
Giống như tôi đã đề cập trước đây, tất nhiên đây là sự đơn giản hóa cách thức tìm kiếm hoạt động, nhưng tôi chỉ muốn cho bạn thấy ý tưởng chung về cách sử dụng inverted index khi thực hiện các truy vấn tìm kiếm. Thật tuyệt vời khi biết nó hoạt động như thế nào, nhưng điều này hoàn toàn minh bạch đối với bạn với tư cách là người dùng Elaticsearch và bạn đã giành chiến thắng để tích cực đối phó với inverted index; Nó chỉ là thứ gì đó mà Elaticsearch sử dụng trong nội bộ. Thật hay ho khi biết những điều cơ bản về cách thức hoạt động của nó.
inverted index cũng chứa thông tin được sử dụng trong nội bộ, chẳng hạn như liên quan đến máy tính. Một số ví dụ về điều này có thể là số lượng tài liệu chứa mỗi thuật ngữ, số lần một thuật ngữ xuất hiện trong một tài liệu nhất định, độ dài trung bình của một trường, v.v. Cũng có thể áp dụng xuất phát từ các từ và từ đồng nghĩa. Điều này cũng sẽ được áp dụng cho inverted index, nhưng tôi muốn giữ mọi thứ đơn giản trong hướng dẫn cơ bản này của inverted index. Vì vậy, để tóm tắt ngắn gọn những gì chúng ta đã nói trong bài này: Một bộ phân tích được áp dụng cho các trường toàn văn bản và kết quả của quá trình phân tích này được lưu trữ trong một inverted index. Một inverted index bao gồm tất cả các điều khoản cho một trường nhất định trên tất cả các tài liệu trong một index. Vì vậy, khi thực hiện một truy vấn tìm kiếm, chúng tôi không thực sự tự tìm kiếm các tài liệu, mà là một inverted index. Điều này rất quan trọng để hiểu bởi vì nếu không, bạn có thể bị bối rối về lý do tại sao một số truy vấn không phù hợp với những gì bạn mong đợi.
Tham khảo thêm một số bài viết khác: https://codingexplained.com/coding
All rights reserved
