Tìm hiểu về hash table
Bài đăng này đã không được cập nhật trong 8 năm
Giới thiệu
Thuật toán liên quan đến hash table được ứng dụng ở hầu hết các ngôn ngữ, là một trong những nền tảng về thuật toán và cấu trúc dữ liệu.
Trong computing, hash table là một cấu trúc dữ liệu dùng để lưu theo các cặp key value, nó dùng hash function để tính toán tới một index, nơi lưu trữ một bucket các giá trị rồi từ đó sẽ retrieve ra value, mục tiêu là để độ phức tạp ở mức O(n)
Giải thích:
Có thể lấy một ví dụ đơn giản là việc lấy sách ở thư viện, mỗi cuốn sách trong thư viện đều có môt unique number, những cuốn sách này sẽ sắp xếp trong cùng một địa chỉ (call number) toạ lạc bên trong thư viện, chúng ta sẽ dựa vào call number và unique number để tìm ra được cuốn sách đang cất ở đâu
Id của sách sẽ được sinh ra dựa trên một function gọi là hash function,
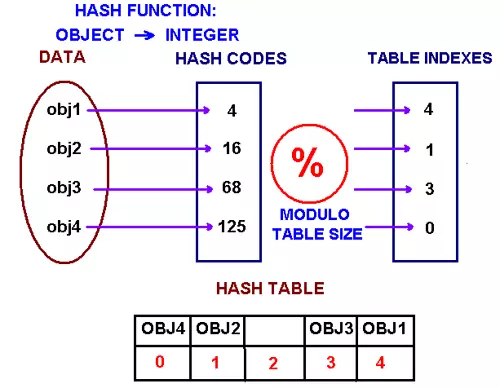
Hash function có thể được implement theo nhiều cách, cách cơ bản nhất dựa trên mã ascii của kí tự.
Ví dụ như dựa trên công thức
s.charAt(0) * 31n-1 + s.charAt(1) * 31n-2 + ... + s.charAt(n-1)
Ở đây s là string cần chuyển, n là độ dài của nó, ví dụ:
"ABC" = 'A' * 312 + 'B' * 31 + 'C' = 65 * 312 + 66 * 31 + 67 = 64578
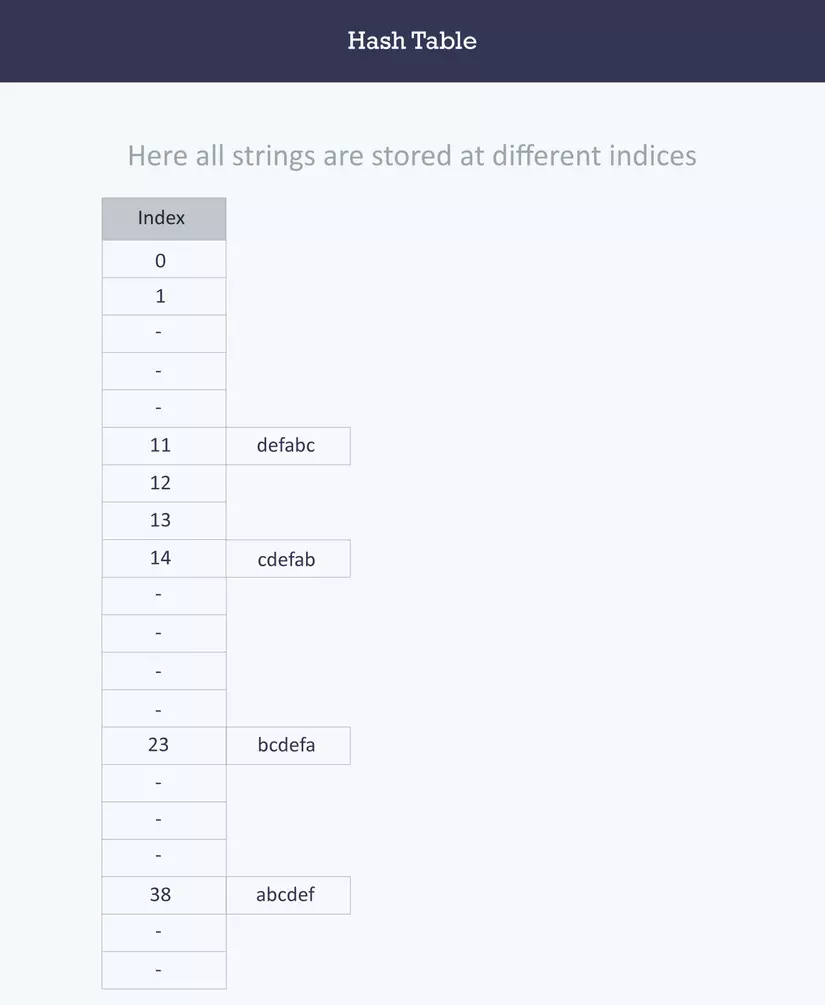
Giả sử chúng ta lưu một bảng string {“abcdef”, “bcdefa”, “cdefab” , “defabc” }. Mã ASCII a, b, c, d, e, và f là 97, 98, 99, 100, 101, 102 , như ta thấy các phần tử phía trên đều có cùng số kí tự và chỉ khác ở sự hoán vị. Thì index của phần tử đó sẽ bằng tổng (mã ascii của kí tự * vị trí của kí tự đó trong chuỗi)
Chúng ta sẽ dùng mã ASCII để sinh ra các đoạn hash code cho một phần tử, tổng tất các mã ascii có thể xác định được kí tự là 2069, nên chúng chia lại cho con số đó để tạo index
String Hash function Index
abcdef (971 + 982 + 993 + 1004 + 1015 + 1026)%2069 38
bcdefa (981 + 992 + 1003 + 1014 + 1025 + 976)%2069 23
cdefab (991 + 1002 + 1013 + 1024 + 975 + 986)%2069 14
defabc (1001 + 1012 + 1023 + 974 + 985 + 996)%2069 11
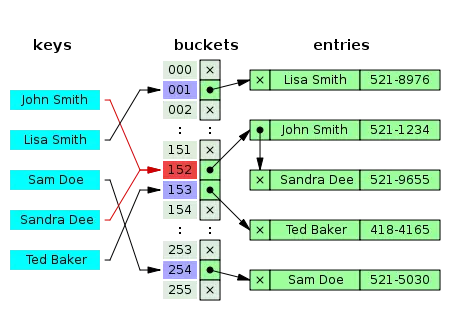
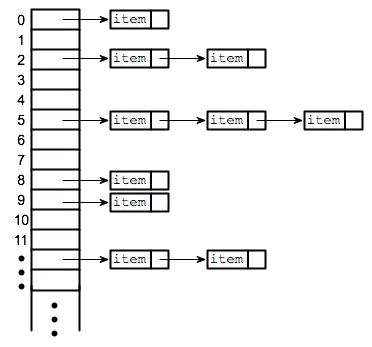
Giải quyết collision
Vấn phát sinh các trường hợp trùng vị trí (index) nếu thuật toán hash không được tốt và hâù như không có thuật toán hash nào thực sự hoàn hảo để sinh ra unique key nếu lưu trữ một lượng lớn dữ liệu , để giải quyết vấn đề này chúng ta dùng linked list để lưu trữ thêm một tầng nữa các phần tử cho index đó.
Có thể coi việc sinh hash là để tạo keyHash và lưu vào trong mảng giá trị nơi chứa một linked list có phần tử chứa key thật của chúng ta, sau khi tới đó chúng ta sẽ dùng key thật để retrieve giá trị
Đây là đoạn code mình thấy khá hay và dễ hiểu về implement hastable:
import LinkedList from '../linked-list/LinkedList';
// Hash table size directly affects on the number of collisions.
// The bigger the hash table size the less collisions you'll get.
// For demonstrating purposes hash table size is small to show how collisions
// are being handled.
const defaultHashTableSize = 32;
export default class HashTable {
/**
* @param {number} hashTableSize
*/
constructor(hashTableSize = defaultHashTableSize) {
// Create hash table of certain size and fill each bucket with empty linked list.
this.buckets = Array(hashTableSize).fill(null).map(() => new LinkedList());
// Just to keep track of all actual keys in a fast way.
this.keys = {};
}
/**
* Converts key string to hash number.
*
* @param {string} key
* @return {number}
*/
hash(key) {
const hash = Array.from(key).reduce(
(hashAccumulator, keySymbol) => (hashAccumulator + keySymbol.charCodeAt(0)),
0,
);
// Reduce hash number so it would fit hash table size.
return hash % this.buckets.length;
}
/**
* @param {string} key
* @param {*} value
*/
set(key, value) {
const keyHash = this.hash(key);
this.keys[key] = keyHash;
const bucketLinkedList = this.buckets[keyHash];
const node = bucketLinkedList.find({ callback: nodeValue => nodeValue.key === key });
if (!node) {
// Insert new node.
bucketLinkedList.append({ key, value });
} else {
// Update value of existing node.
node.value.value = value;
}
}
/**
* @param {string} key
* @return {*}
*/
delete(key) {
const keyHash = this.hash(key);
delete this.keys[key];
const bucketLinkedList = this.buckets[keyHash];
const node = bucketLinkedList.find({ callback: nodeValue => nodeValue.key === key });
if (node) {
return bucketLinkedList.delete(node.value);
}
return null;
}
/**
* @param {string} key
* @return {*}
*/
get(key) {
const bucketLinkedList = this.buckets[this.hash(key)];
const node = bucketLinkedList.find({ callback: nodeValue => nodeValue.key === key });
return node ? node.value.value : undefined;
}
/**
* @param {string} key
* @return {boolean}
*/
has(key) {
return Object.hasOwnProperty.call(this.keys, key);
}
/**
* @return {string[]}
*/
getKeys() {
return Object.keys(this.keys);
}
}
Hy vọng các bạn hiểu hơn về hash map , hash table, thứ mà dân DEV chúng ta hầu như xài cả ngày (hoho)
All rights reserved
