Tìm hiểu về Elasticsearch với các ví dụ áp dụng (P1)
Bài đăng này đã không được cập nhật trong 5 năm
Bài toán tìm kiếm là vấn đề rất quan trọng cần phải giải quyết trong quá trình phát triển phần mềm của các lập trình viên. Hiện nay, có rất nhiều cách và công cụ để giúp việc giải quyết bài toán tìm kiếm trở nên nhanh với hiệu suất cao hơn. Bài viết sẽ tìm hiểu một công cụ rất phổ biến giúp giải quyết bài toán tìm kiếm với đầu vào dữ liệu lớn đó là Elasticsearch. Mục tiêu của Elasticsearch ở đây là tìm kiếm, phân tích dữ liệu bằng thời gian thật
I. Khái niệm
Elasticsearch (ES) là một document oriented database. Nhiệm vụ của nó chính là store và retrieve document. ES được xây dựng để hoạt động như một server cloud theo cơ chế của RESTful, phát triển bằng ngôn ngữ java. Trong ES, tất cả các document được hiển thị trong JSON format. Chúng ta sẽ tìm hiểu về khái niệm document trong ES ở các mục sau. Nếu đã từng sử dụng MongoDB, ta đã dễ dàng quen với JSON storage service. Nhưng trong ES, sự kết hợp của storage và querying/aggregation service đã làm cho ES thực sự đặc biệt và khác xa 1 công cụ chỉ lưu trữ văn bản.
Một ví dụ đơn giản của ES trong thực tế như khi ta tìm kiếm trên tiki, khi gõ một từ khóa sẽ cho ra kết quả có từ khóa đã search. Tất nhiên, có nhiều cách để làm việc này như kiểu sử dụng % trong MySQL nhưng với ES thì việc tìm kiếm như kiểu này sẽ cho hiệu suất cao hơn.
Các trường hợp trong thực tế nên áp dụng ES như :
- Tìm kiếm text thông thường – Searching for pure text (textual search)
- Tìm kiếm text và dữ liệu có cấu trúc – Searching text and structured data (product search by name + properties)
- Tổng hợp dữ liệu – Data aggregation
- Tìm kiếm theo tọa độ – Geo Search
- Lưu trữ dữ liệu theo dạng JSON – JSON document storage
II. Các khái niệm quan trọng
Chúng ta hãy cùng tìm hiểu sâu hơn về các khái niệm chính trong ES bao gồm:
- Cluster: Một tập hợp Nodes (servers) chứa tất cả các dữ liệu.
- Node: Một server duy nhất chứa một số dữ liệu và tham gia vào cluster’s indexing and querying.
- Index: Mỗi ES Index là 1 tập hợp các documents.
- Shards: Tập con các documents của 1 Index. Một Index có thể được chia thành nhiều shard.
- Type: Một định nghĩa về schema of a Document bên trong một Index (Index có thể có nhiều type).
- Document: Một JSON object với một số dữ liệu. Đây là basic information unit trong ES.
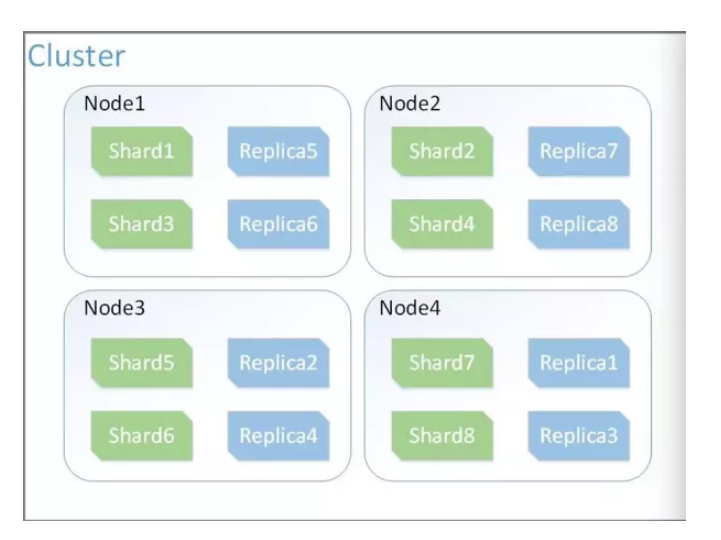
1. Cluster
Cluster là một tập hợp các node - nơi lưu trữ toàn bộ dữ liệu, thực hiện đánh index và search giữa các node. 1 cluster được xác định bằng 1 'unique name'. Nếu như các cluster có tên trùng nhau sẽ dẫn tới hiện tượng các node join nhầm cluster. Do vậy nên tên của cluster phải là 'unique'
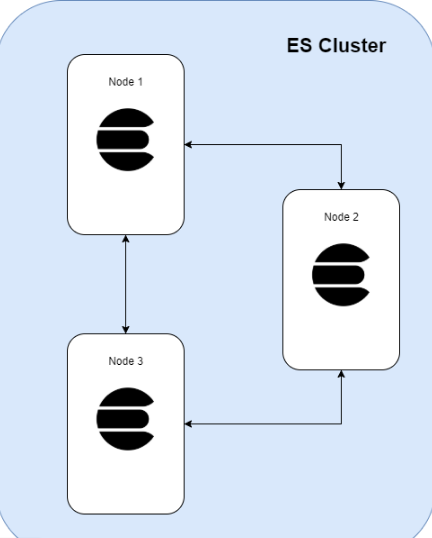
2. Node
Mỗi node là 1 server bên trong Cluster, là nơi lưu trữ dữ liệu, tham gia thực hiện việc đánh index của cluster, và thực hiện search. Cũng như cluster, mỗi node được xác định bởi 1 unique name của cluster đó. Unique Name này mặc định là 1 chuỗi random UUID và được gán giá trị ngay khi node được start
3 . Index
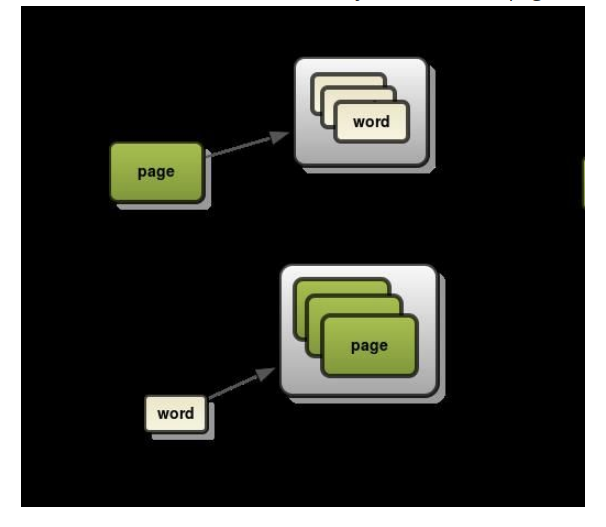
Index là 1 nơi chứa các document (hiểu nôm na nó giống như Record trong Sql) liên quan tới nhau.Trong index không chỉ lưu trữ các document mà còn là nơi lưu cách đánh index cho document đó. Bên trong index chúng ta có thể thiết lập các document sẽ được index, analyze như thế nào (thông qua MAPPING & ANALYSIS, sẽ được giới thiệu ở phần 2 của Series này), và cách nó được inverted index khi search ra sao. ES tìm kiếm bởi inverted index nó khác so với forward index mà ta đã biết. Một ví dụ đơn giản về 2 loại index này trong thực tế như sau:
Khi đánh phụ lục cho quyến sách sẽ có 2 phần phụ lục: phần trước và phần sau. Thông thường phần phụ lục trước sẽ lưu content giống như dưới đây
Chapter 1:...........................1
Mục 1.........................................................3
Mục 2..........................................6
...
Phần phụ lục ở phía sau sẽ như sau:
A: Coding(page139-140), Q&A(page125-167)
B: Testing(page197), Maintain(page123)
Việc làm phụ lục bản chất giống như việc đánh index vậy. Cách làm phụ lục như phần trước gọi là forward index còn phần sau là inverted index
- Forward Index: Đánh index theo nội dung, page: page -> words
- Inverted Index: Đánh index theo keyword: words -> pages
Như vậy, với việc dùng inverted index với các keywords. Thay vì đọc từng page để tìm kiếm, ES sẽ tìm kiếm keyword trong index nên kết quả trả về sẽ rất nhanh.
![]()
4. Shard và replicas
Một index chứa quá nhiều dữ liệu mà hardware không đáp ứng được hoặc việc tìm kiếm trên một index có quá nhiều dữ liệu sẽ làm giảm hiệu năng
Solution: ES cung cấp cơ chế cho phép chia index thành nhiều phần nhỏ các phần này được gọi là shards. khi tạo một index có thể configure số lượng shards mà chúng ta muốn lưu trữ index này. Mỗi shards, bản thân nó là một index đầy đủ chức năng và độc lập do đó chúng có thể được host bởi bất kỳ node (server) nào. Với shard nó cho phép:
- Horizontally scale
- Tính toán phân tán và song song đồng thời trên các shards => tăng hiệu năng
ES cũng cho phép bạn tạo một hay nhiều bản copy của một shards, gọi là replica shards ngắn gọn là replicas . Với replicas:
- Nếu một shard bị lỗi, thì bản copy của nó sẽ được dùng để thay thế
- Cho phép scale hệ thống vì việc tìm kiếm có thể tiến hành song song trên các replicas
5. Document
Document đơn giản là 1 đơn vị cơ bản nhất để có thể đánh index. Và bạn cũng có thể coi nó tương tự Rows (hay Record) trong Sql. Trong Elasticsearch Document được lưu dưới dạng JSON. Document cần được gán cho 1 type bên trong index.
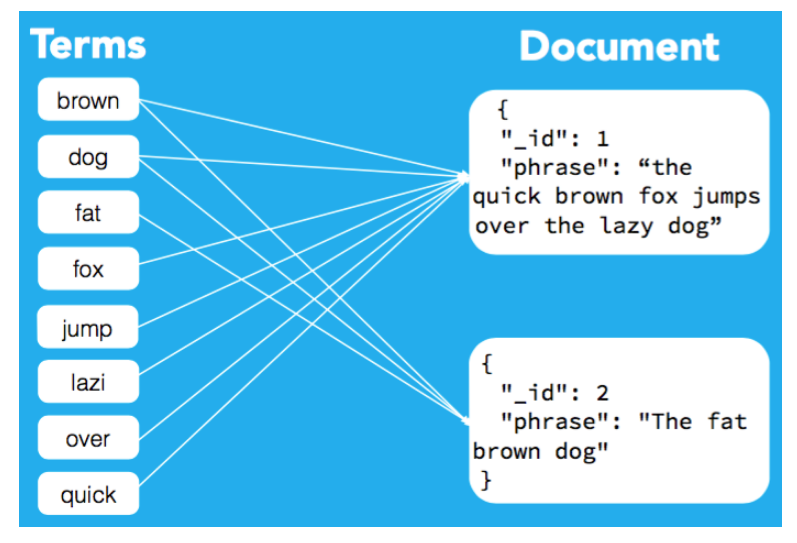
III. Cách ES lưu trữ dữ liệu
Với ES, Document là đơn vị tìm kiếm và đánh index. Một index có thể bao gồm một hay nhiều Document, và một Document có thể chứa một hay nhiều Fields. Trong thuật ngữ về Database, thì một Document có thể hiểu như một table row và một Field tương ứng với một table column. ES có đặc điểm schema-free, có nghĩa là ta không cần phải chỉ rõ ra cấu trúc của schema trước khi đánh index cho các documents. Một schema sẽ bao gồm các thông tin sau:
- Các fields
- Các ràng buộc: unique/primary key
- Các required fields
- Đánh index và search mỗi field như thế nào Mapping là quá trình định nghĩa làm thế nào một document và các fields của nó được lưu trữ và đánh index. Mỗi index có duy nhất 1 kiểu mapping, và mapping type này sẽ quyết định cách các document sẽ được index. Mapping type gồm Meta-fields và Properties
- Meta-fields: cho phép chúng ta customize các behavior của các document
- Fields/Properties: danh sách các properties tương ứng với các document
Mỗi property bao gồm 1 data-type type, là kiểu dữ liệu của prop đó. type có thể là text, keyword, date, double, boolean ...
IV. Ưu và nhược điểm của ElasticSearch
Ưu điểm
- Tìm kiếm dữ liệu rất nhanh chóng, mạnh mẽ dựa trên Apache Lucene. Tìm kiếm trong elasticsearch gần như là realtime hay còn gọi là near-realtime searching
- Có khả năng phân tích dữ liệu (Analysis data)
- Lưu trữ dữ liệu full-text
- Đánh index cho dữ liệu (near-realtime search/indexing, inverted index)
- Hỗ trợ tìm kiếm mờ (fuzzy), tức là từ khóa tìm kiếm có thể bị sai lỗi chính tả hay không đúng cú pháp thì vẫn có khả năng elasticsearch trả về kết quả tốt.
- Hỗ trợ nhiều Elasticsearch client phổ biến như Java, PhP, Javascript, Ruby, .NET, Python
Nhược điểm
- Elasticsearch được thiết kế cho mục đích search, do vậy với những nhiệm vụ khác ngoài search như CRUD thì elastic kém thế hơn so với những database khác như Mongodb, Mysql …. Do vậy người ta ít khi dùng elasticsearch làm database chính, mà thường kết hợp nó với 1 database khác.
- Trong elasticsearch không có khái niệm database transaction , tức là nó sẽ không đảm bảo được toàn vẹn dữ liệu trong các hoạt động Write, Update, Delete.
- Elasticsearch không cung cấp bất kỳ tính năng nào cho việc xác thực và phân quyền (authentication or authorization)
Như vậy, bài viết đã tìm hiểu cơ bản về elasticsearch và các khái niệm quan trọng cần nắm rõ. Ở phần tiếp theo chúng ta sẽ đi sâu hơn với các ví dụ để hiểu rõ hơn. Hẹn gặp lại!
Reference
- Elasticsearch In Action (Matthew Lee Hinman and Radu Gheorghe)
- https://www.elastic.co/guide/index.html
- https://logz.io/blog/10-elasticsearch-concepts/
All rights reserved
