Tìm hiểu về Elasticsearch Aggregations
Bài đăng này đã không được cập nhật trong 6 năm
Elasticsearch Aggregarions giúp thực hiện tính toán và thống kê sử dụng một search query đơn giản. Ta có thể truy xuất dữ liệu mà mình muốn sử dụng phương thức GET trong Dev Tools của Kibana UI, CURL hay APIs trong code. Trong bài viết này sẽ sử dụng Dev Tools của Kibana UI để thực hiện truy vấn.
Dưới đây là 2 ví dụ ta có thể sử dụng aggregations:
- Bạn đang thực hiện kinh doanh quần áo online và muốn biết trung bình cộng giá của tất cả sản phẩm trong danh mục hàng hóa.
- Bạn muốn kiểm tra xem có bao nhiêu sản phẩm có giá trong khoảng 100$ và giá trong khoảng từ 100$ đến 200$.
Để bắt đầu sử dụng aggregations, bạn cần cài đặt elasticsearch và có một vài data/schema trong Elasticsearch index. Trong bài viết này, ta sẽ sử dụng dữ liệu mẫu eCommerce orders và Web logs cung cấp bởi kibana.
Bạn có thể lấy dữ liệu bằng cách vào homepage của Kibana và click vào "Load a data set and a Kibana dashboard"
Cú pháp Aggregation
"aggs”: {
“name_of_aggregation”: {
“type_of_aggregation”: {
“field”: “document_field_name”
}
aggs—Từ khóa này cho biết bạn muốn thực hiện truy vấn aggregation.
name_of_aggregation—Đây là tên của aggregation mà bạn định nghĩa.
type_of_aggregation—Loại aggregation được sử dụng.
field—từ khóa field.
document_field_name—field mà ta muốn thực hiện aggregation.
Ví dụ:
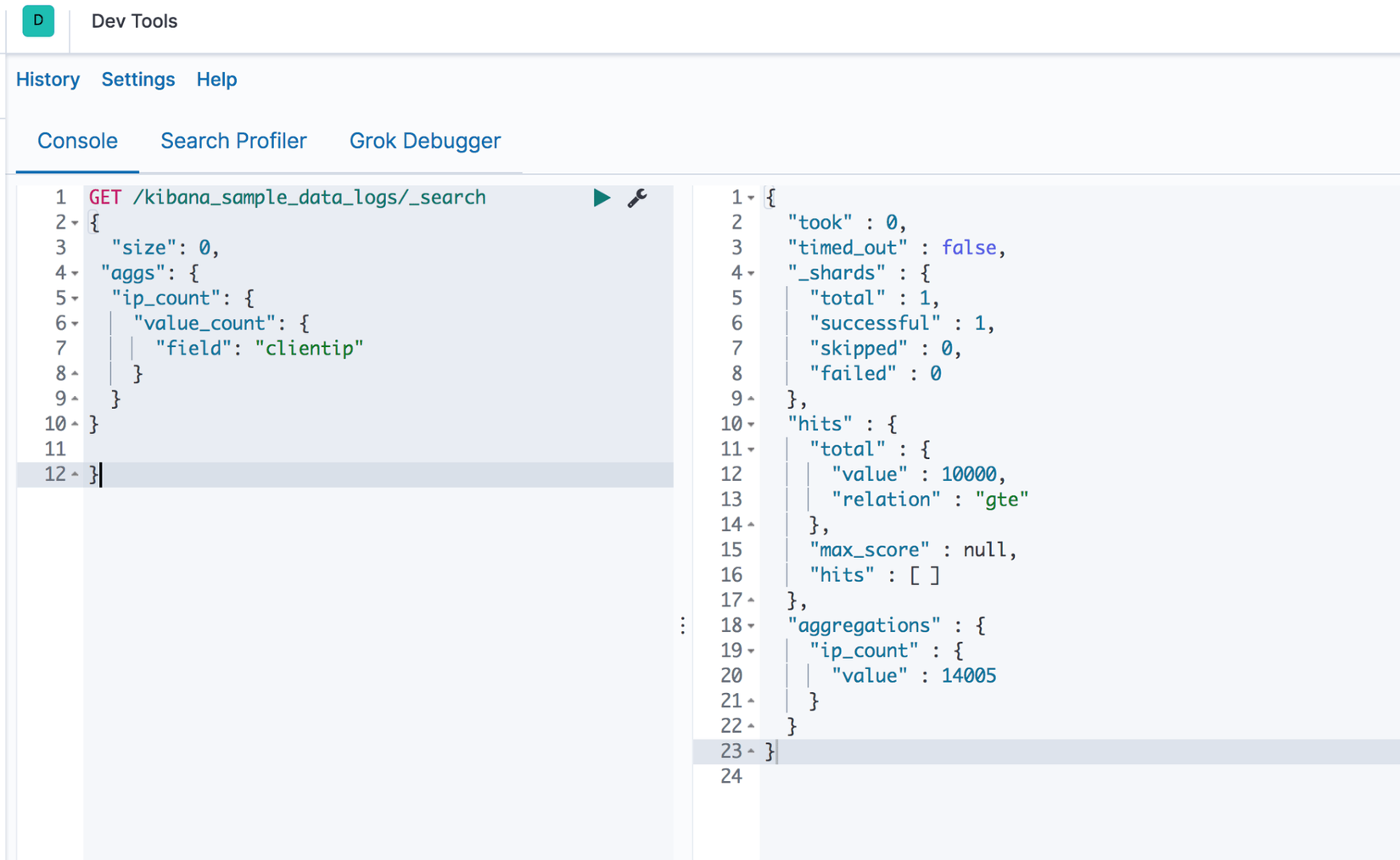
GET /kibana_sample_data_logs/_search
{ "size": 0,
"aggs": {
"ip_count": {
"value_count": {
"field": "clientip"
}
}
}
}
Truy vấn trên sẽ trả về tổng số "clientip" trong index "kibana_sample_data_logs":
Các loại Aggregation chính
Aggregations có thể được chia thành 4 nhóm: bucket aggregations, metric aggregations, matrix aggregations, và pipeline aggregations.
- Metric aggregations—Loại aggregation này tính toán số liệu từ các giá trị thu được từ các document đang được tổng hợp.
- Bucket aggregations—Bucket aggregations không tính toán các số liệu từ các field như Metric aggregations mà tạo ra các bucket của các document. Mỗi bucket tương ứng với một tiêu chí mà dựa vào đó để xác định xem 1 document có thuộc bucket đó trong bối cảnh hiện tại không.
- Pipeline aggregations—Loại aggregation này lấy input từ output của các aggregation khác.
- Matrix aggregations—Những aggregation này làm việc trên nhiều hơn một field và cung cấp kết quả thống kê dựa trên các document thu được từ các trường được sử dụng.
Một số Aggregation quan trọng
5 aggregation quan trọng trong Elasticsearch là:
- Cardinality aggregation
- Stats aggregation
- Filter aggregation
- Terms aggregation
- Nested aggregation
Cardinality aggregation
Aggregation này là một single-value aggregation thuộc loại Metric aggregations, sử dụng để tính toán số lượng các giá trị khác nhau của một field cụ thể.
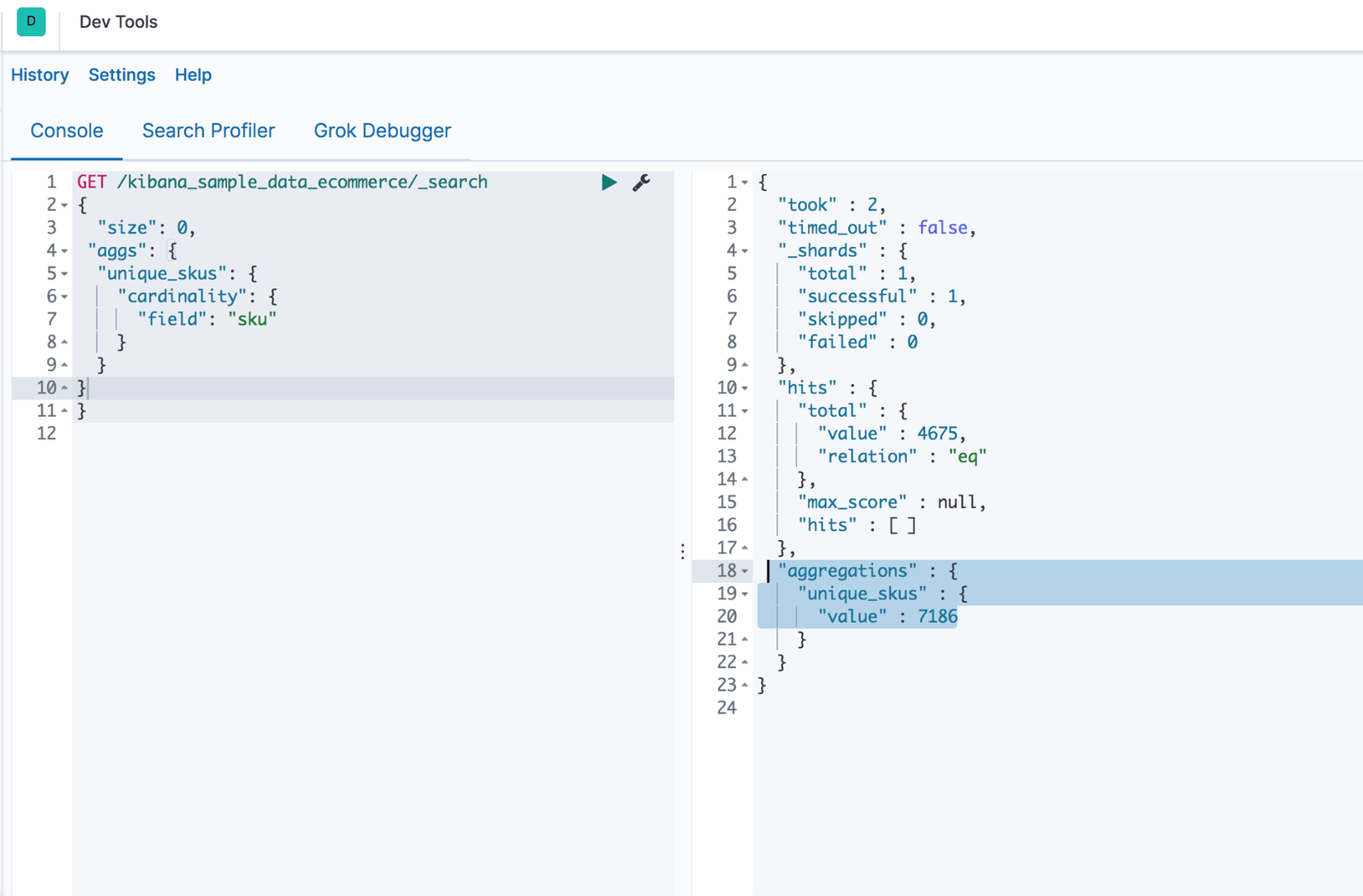
Để tìm xem có bao nhiêu sku trong dữ liệu e-commerce, ta thực hiện truy vấn
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"unique_skus": {
"cardinality": {
"field": "sku"
}
}
}
}
Kết quả thu được là:
Stats Aggregation
Đây là 1 multi-value Metric aggregations, tính toán số liệu thống kê từ các giá trị số từ các document tổng hợp được.
Số liệu thống kê trả về bao gồm min, max, sum, count và avg.
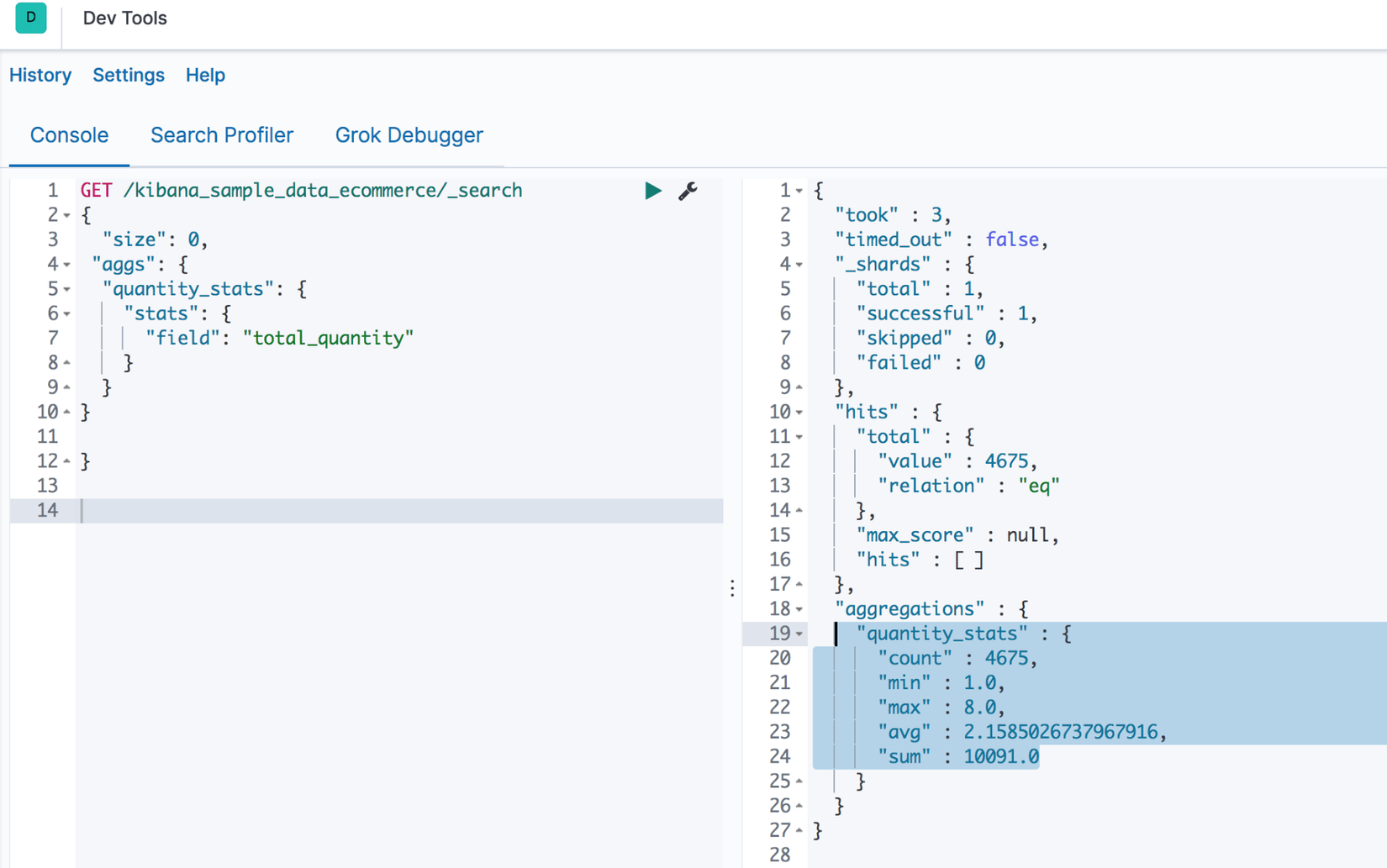
Thử kiểm tra số liệu thống kê field total_quantity trong dữ liệu mẫu:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"quantity_stats": {
"stats": {
"field": "total_quantity"
}
}
}
}
Kết quả:
Filter Aggregation
Aggregarion này thuộc Bucket aggregations, định nghĩa một bucket duy nhất chứa các document thỏa màn điều kiện filter, và có thể thực hiện tính toán số liệu trong bucket này.
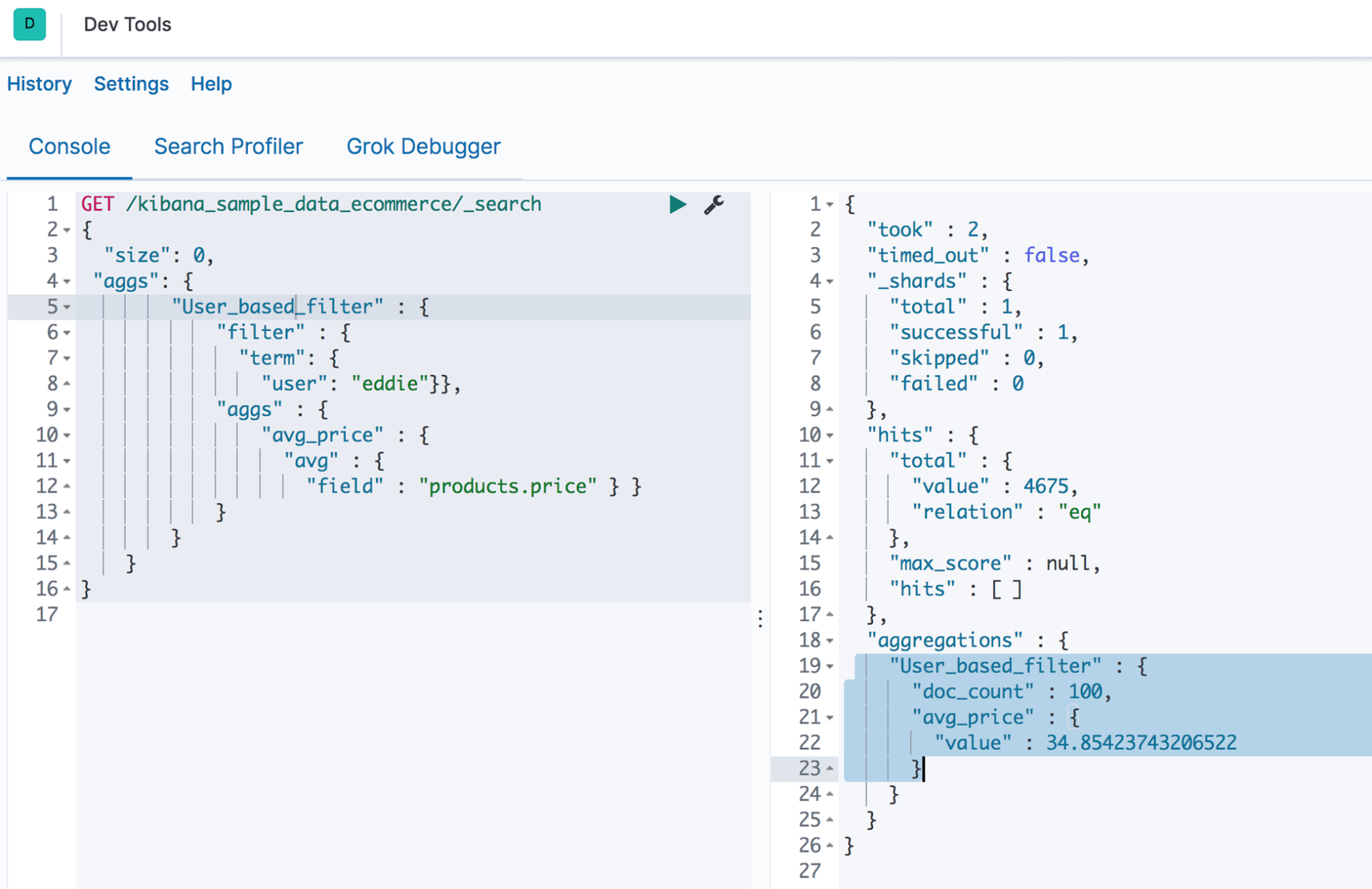
Ví dụ: ta filter các document có username "eddie" và tính trung bình cộng giá của các sản phẩm người đó đã mua.
GET /kibana_sample_data_ecommerce/_search
{ "size": 0,
"aggs": {
"User_based_filter" : {
"filter" : {
"term": {
"user": "eddie"}},
"aggs" : {
"avg_price" : {
"avg" : {
"field" : "products.price" } }
}}}}
Kết quả:
Terms Aggregation
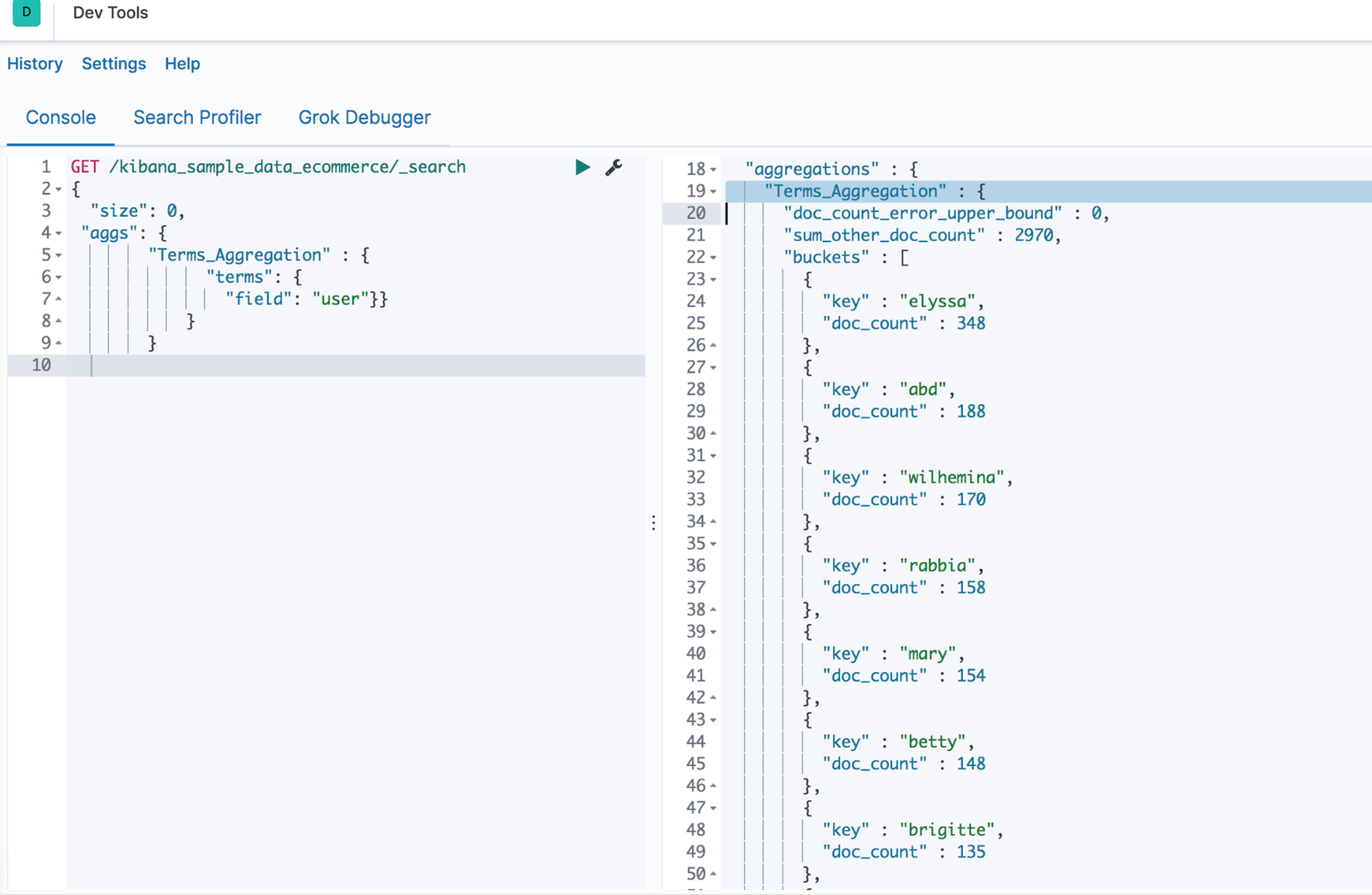
1 loại Bucket aggregations, tạo ra các bucket từ các giá trị của field, số lượng bucket là động, mỗi giá trị khác nhau của field được chỉ định sẽ tạo ra 1 bucket.
Trong ví dụ dưới đây, ta sẽ thực hiện terms aggregation trên field "user". Ở kết quả, ta sẽ có các bucket cho mỗi user, mỗi bucket sẽ chứa số lượng document.
Câu truy vấn của ta là:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"Terms_Aggregation" : {
"terms": {
"field": "user"}}
}
}
Kết quả:
Nested Aggregation
Đây là một trong những loại quan trọng nhất trong Bucket Aggregations. Một Nested Aggregation cho phép tổng hợp một field với nested documents—một field mà có nhiều sub-fields.
Một field phải có type là "nested" trong index mapping nếu bạn muốn sử dụng Nested Aggregation trên field đó.
Dữ liệu ecommerce mẫu không có field nào có type là "nested" nên ta sẽ tạo một index mới với field "Employee" có type là "nested":
PUT nested_aggregation
{
"mappings": {
"properties": {
"Employee": {
"type": "nested",
"properties" : {
"first" : { "type" : "text" },
"last" : { "type" : "text" },
"salary" : { "type" : "double" }
}}}
}}
Thêm một số dữ liệu vào index ta vừa tạo:
PUT nested_aggregation/_doc/1
{
"group" : "Logz",
"Employee" : [
{
"first" : "Ana",
"last" : "Roy",
"salary" : "70000"
},
{
"first" : "Jospeh",
"last" : "Lein",
"salary" : "64000"
},
{
"first" : "Chris",
"last" : "Gayle",
"salary" : "82000"
},
{
"first" : "Brendon",
"last" : "Maculum",
"salary" : "58000"
},
{
"first" : "Vinod",
"last" : "Kambli",
"salary" : "63000"
},
{
"first" : "DJ",
"last" : "Bravo",
"salary" : "71000"
},
{
"first" : "Jaques",
"last" : "Kallis",
"salary" : "75000"
}]}
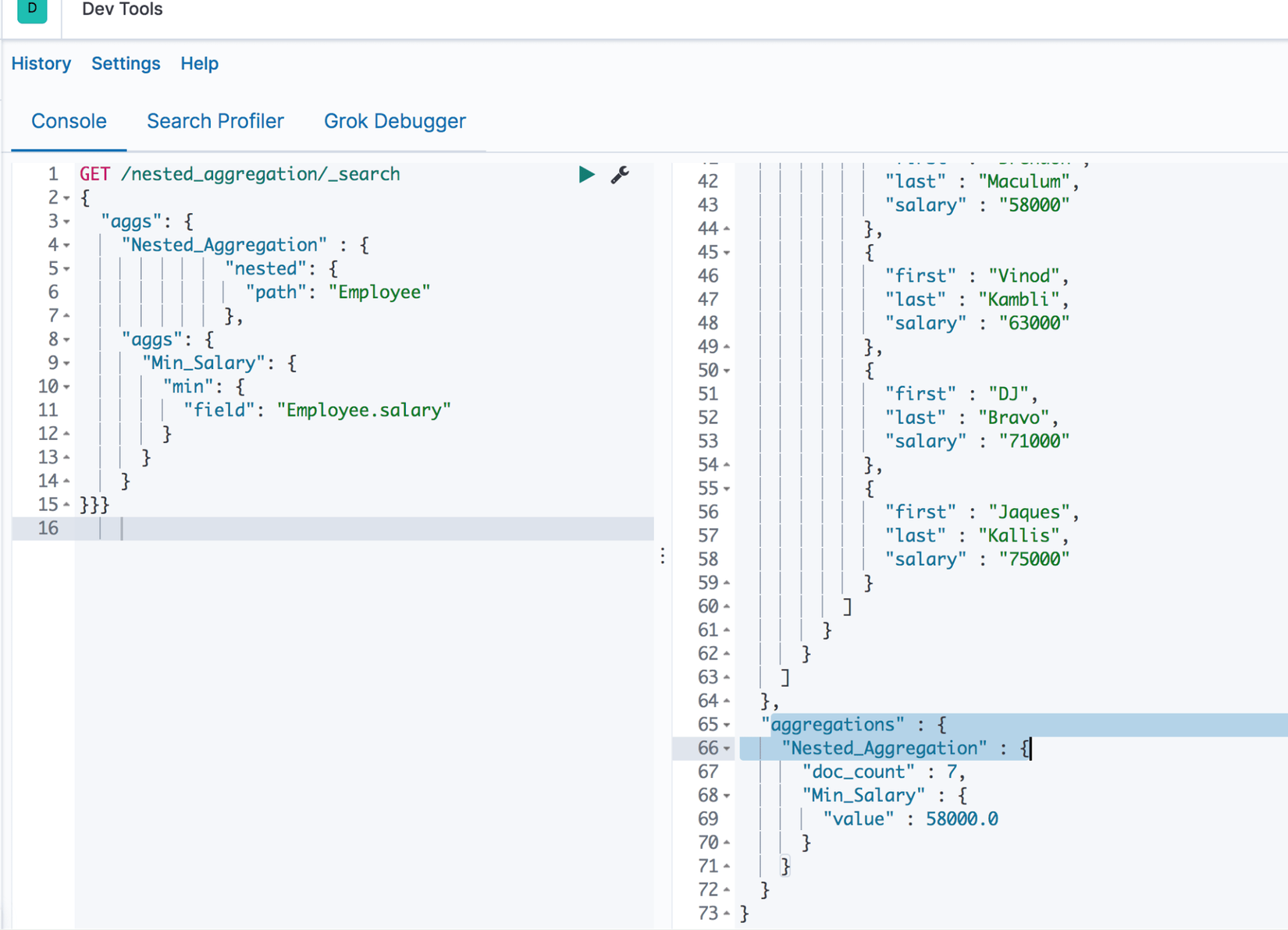
Giờ ta đã có dữ liệu mẫu để có thể thực hiện Nested Aggregation. Quan sát ví dụ dưới đây để xem nó hoạt động thế nào:
GET /nested_aggregation/_search
{
"aggs": {
"Nested_Aggregation" : {
"nested": {
"path": "Employee"
},
"aggs": {
"Min_Salary": {
"min": {
"field": "Employee.salary"
}
}
}
}}}
Kết quả:
Tóm tắt
Bài viết đã chi tiết một số kỹ thuật trong việc tận dụng aggregations. Còn 1 số aggregation cũng có thể hữu dụng với bạn:
- Date histogram aggregation—sử dụng với các giá trị dates.
- Scripted aggregation—sử dụng với scripts.
- Top hits aggregation—sử dụng với các document phù hợp nhất.
- Range aggregation—sử dụng với tập các giá trị khoảng.
Ngoài ra còn rất nhiều aggregation khác nhưng ít thông dụng hơn nên không đề cập ở bài viết này. Nếu bạn muốn tìm hiểu thêm thì có thể đọc ở đây
Tham khảo
https://logz.io/blog/elasticsearch-aggregations/
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
All rights reserved
