Tìm hiểu về Elasticsearch
Bài đăng này đã không được cập nhật trong 7 năm
Giới thiệu
Chắc hẳn mọi người ai cũng đã từng sử dụng qua công cụ search của Google. Mỗi khi chúng ta gõ một từ khóa vào ô tìm kiếm, lập tức sẽ có một danh sách các gợi ý có liên quan đến từ khóa đó hiện lên màn hình để ta có thể chọn, thao tác nhanh hơn. Ngoài ra, với hàng tỉ websites được public trên thế giới, cùng với nội dung vô cùng lớn của các website đó trên Internet, làm sao mà công cụ tìm kiếm của Google có thể truy xuất cho ra dữ liệu chưa đầy nửa giây như vậy. Chắc hẳn, không thể tìm kiếm thông thường từ nội dung text trên các trang web đó được, mà phải có một cách tổ chức dữ liệu đặc biệt và một thuật toán tìm kiếm đặc biệt.
Để giải quyết được bài toán này, các search engine đã ra đời. Elasticsearch cũng là một search engine được cài đặt dựa trên thuật toán full-text search. Cho phép chúng ta lưu trữ, tím kiếm và phân tích một lượng lớn dữ liệu một cách gần như real-time. ES (Elasticsearch) thường được sử dụng ở phía back-end để xử lí một công việc search phức tạp.
Những khái niệm cơ bản
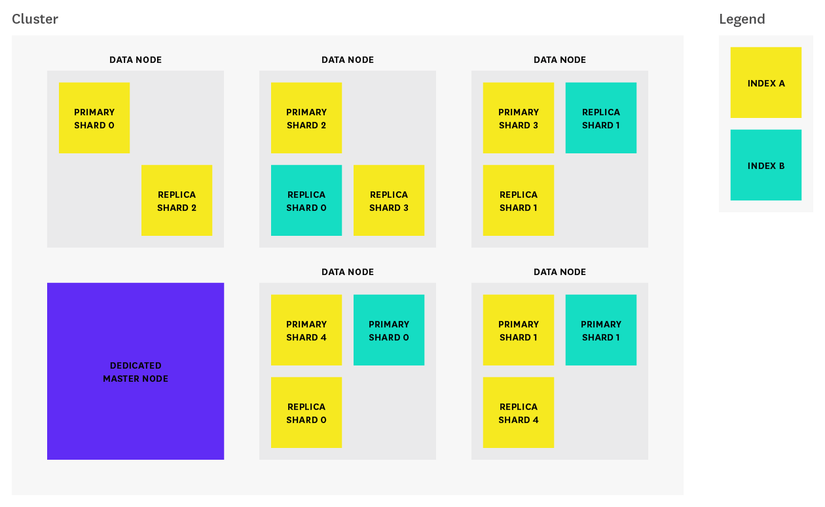
1. Cluster
Cluster theo ý nghĩa của nó là một cụm những server hay còn gọi là node. Có vai trò quản lí, lưu trữ toàn bộ dữ liệu và thống nhất việc indexing, tìm kiếm giữa tất cả các node với nhau. Một cluster phải được định danh bởi một tên duy nhất, mặc định là "elasticsearch". Việc đặt tên này rất quan trọng, bởi vì các node chỉ thuộc về cluster nếu như nó được thiết lập bởi tên này, là một định danh để phân biệt với các cluster khác trên những môi trường khác nhau.
2. Node
Node là một single server thuộc một cluster quản lí. Là nơi lưu trữ các dữ liệu, tham gia vào việc indexing và searching trong cluster. Cũng giống với cluster, node cũng được cung cấp một tên riêng mỗi khi startup. Mặc định tên của node là một UUID được sinh ngẫu nhiên. Bạn có thể thay đổi nó nếu không muốn sử dụng cài đặt mặc định. Trong một single cluster, có thể chứa nhiều node tùy vào bạn muốn. Mặc định của ES khi start trên 1 cluster và 1 node.
3. Index
Được coi là một tập hợp các documents - tập hợp các từ, ký tự mang ý nghĩa tương tự nhau. Tên của index phải là định danh duy nhất, có thể hiểu một index tương đương với một bảng trong cơ sở dữ liệu. Giả sử, chúng ta có index là people thì nó thường sẽ chứa các thông tin liên quan đến người như: tên, tuổi, giới tính,... Trong một cluster, bạn có thể tạo ra nhiều index khác nhau.
4. Type
Là kiểu dữ liệu được lưu trong index, một index có thể được đánh nhiều kiểu type. Vì dụ, với index person có thể có type là student hoặc teacher. Nhưng khái niệm type này đã bị loại bỏ từ ES version 6.0.0
5. Document
Là đơn vị cơ bản của Elasticsearch, là một bản ghi chứa dữ liệu của một index. Tương đương với 1 row trong SQL. Mặc dù document nằm trong index, nhưng thực thế nó được lưu và nằm trong 1 type thuộc index.
6. Shards & Replicas
Một index có khả năng lưu trữ một lượng lớn dữ liệu, nhưng đến khi dung lượng của index vượt quá khả năng lưu trữ trên một node. Giả sử, dung lượng các documents có trong index lên tới 1TB và vượt quá khả năng lưu trữ của ổ cứng thì ta phải nghĩ đến việc chia nhỏ và phân tán các documents đó ra để quản lí. Đây cũng là khái niệm Shard trong ES. Shard có 2 điểm quan trọng:
- Có khả năng phân chia nội dung volume thành những mảnh nhỏ.
- Cho phép thực hiện trên hệ thống phân tán và cơ chế song song, giúp tăng performance/throughout Cơ chế làm việc của shard là phân tán và cách mà các documents được tập hợp lại thành kết quả khi search hoàn toàn trong suốt đối với người dùng.
Trong môi trường network/cloud có khả năng xảy ra những lỗi không mong muốn. Vì vậy, ES có cung cấp cơ chế sao lưu, cơ chế này cho phép một shard có thể tạo ra nhiều bản sao được gọi là replicas. Có 2 điểm nổi bật như sau:
- Cung cấp giải pháp trong trường hợp các shard/node bị lỗi. Replica shard không bao giờ được lưu trữ cùng node với shard mà nó sao chép.
- Việc tìm kiếm có thể thực hiện song song trên các replicas. Tóm lại, index được chia thành nhiều shard. Một shard có thể có nhiều replicas (bản copied) hoặc không có bản nào. Như vậy trong khi lưu trữ sẽ có 2 phân vùng, 1 phân vùng primary dành cho dữ liệu gốc (primary) và 1 vùng để lưu trữ các replicas.
Mặc định, index trong ES được phân chia thành 5 shard và 1 replicas, như vậy trong cluster sẽ có 10 shard bao gồm 5 shard primary và 5 replicas tương ứng.
Tổng kết
Elasticsearch thực sự là một search engine rất mạnh, hỗ trợ giải quyết được những bài toán tìm kiếm phức tạp, những bài toán liên quan đến dữ liệu lớn. Hiệu năng của ES cũng vô cùng tuyệt vời bởi cơ chế phân tán và xử lý dữ liệu song song. Trên đây là bài giới thiệu về mô hình tổng quan của Elasticsearch. Trong những bài viết sau, sẽ tìm hiểu về cách cài đặt, cấu hình và thực hiện các query liên quan đến dữ liệu trong ES. Cảm ơn mọi người đã tham khảo bài viết.
Tham khảo
All rights reserved
