Tìm hiểu về Elascticsearch
Bài đăng này đã không được cập nhật trong 7 năm
1. Elascticsearch là gì?
- Theo trang chủ của elastic.co thì elasticsearch được định nghĩa là một công cụ phân tích và tìm kiếm phân tán, có khả năng giải quyết một số lượng lớn các trường hợp sử dụng. Là trung tâm của Elastic Stack (Ngăn xếp Đàn hồi), là một search engine. Elasticsearch được xây dựng để hoạt động như một server cloud theo cơ chế của RESTful, phát triển bằng ngôn ngữ java
- Mục tiêu của elasticsearch ở đây là tìm kiếm, phân tích dữ liệu bằng thời gian thật
- Các nguồn dữ liệu mà elasticsearch có thể phân tích gồm: MsSQL, MySQL, PostgreSQL, … mà cũng có thể là các bản text, gmail, pdf, ... miễn sao nó là dữ liệu văn bản
2. Ưu điểm và Nhược điểm:
- Ưu điểm:
- Tốc độ: dùng elasticsearch trả về giá trị rất nhanh, vì chỉ cần tìm kiếm 1 term là trả về các giá trị liên quan tới term đó
- Xây dựng trên Lucene: Vì được xây dựng trên Lucene nên Elasticesearch cung cấp khả năng tìm kiếm toàn văn bản (full-text) mạnh mẽ nhất.
- Hướng văn bản: Nó lưu trữ các thực thể phức tạp dưới dạng JSON và đánh index tất cả các field theo cách mặc định, do vậy đạt hiệu suất cao hơn.
- Giản đồ tự do: Nó lưu trữ số lượng lớn dữ liệu dưới dạng JSON theo cách phân tán. Nó cũng cố gắng phát hiện cấu trúc của dữ liệu và đánh index của dữ liệu hiện tại, làm cho dữ liệu trở nên thân thiện với việc tìm kiếm.
- Nhược điểm:
- Elasticsearch được thiết kế cho mục đích search, do vậy với những nhiệm vụ khác ngoài search như CRUD (Create Read Update Destroy) thì elasticsearch kém thế hơn so với những database khác như Mongodb, Mysql …. Do vậy người ta ít khi dùng elasticsearch làm database chính, mà thường kết hợp nó với 1 database khác.
- Trong elasticsearch không có khái niệm database transaction , tức là nó sẽ không đảm bảo được toàn vẹn dữ liệu trong các hoạt động Insert, Update, Delete.Tức khi chúng ta thực hiện thay đổi nhiều bản ghi nếu xảy ra lỗi thì sẽ làm cho logic của mình bị sai hay dẫn tới mất mát dữ liệu. Đây cũng là 1 phần khiến elasticsearch không nên là database chính.
- Không thích hợp với những hệ thống thường xuyên cập nhật dữ liệu. Sẽ rất tốn kém cho việc đánh index dữ liệu.
3. Một số khái niệm cơ bản:
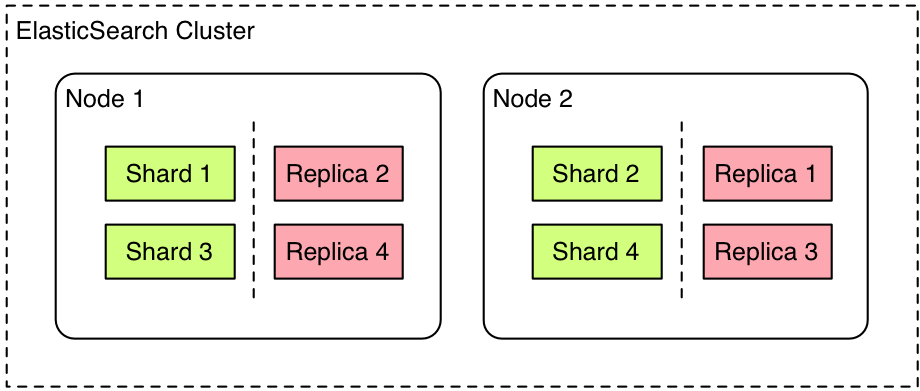
- Cluster: Cluster là một tập hợp các node - nơi lưu trữ toàn bộ dữ liệu, thực hiện đánh index và search giữa các node. 1 cluster được xác định bằng 1 'unique name'. Nếu như các cluster có tên trùng nhau sẽ dẫn tới hiện tượng các node join nhầm cluster. Do vậy nên tên của cluster phải là 'unique'. Chẳng hạn: các cluster trên các môi trường dev, staging và production có thể được đặt tên là 'logging-dev', ‘logging-stage', và 'logging-prod' thay vì để tên giống nhau 'logging'. Việc đặt tên như vậy sẽ giúp tránh được việc NODE thuộc môi trường product join "nhầm" CLUSTER trên môi trường dev.
- Node: Mỗi node là 1 server bên trong Cluster, là nơi lưu trữ dữ liệu, tham gia thực hiện việc đánh index của cluster, và thực hiện search. Cũng như cluster, mỗi node được xác định bởi 1 unique name của cluster đó. Unique Name này mặc định là 1 chuỗi random UUID ( Universally Unique IDentifier, hiểu nôm na là một trình tạo ID duy nhất trên toàn cầu) và được gán giá trị ngay khi node được start up.
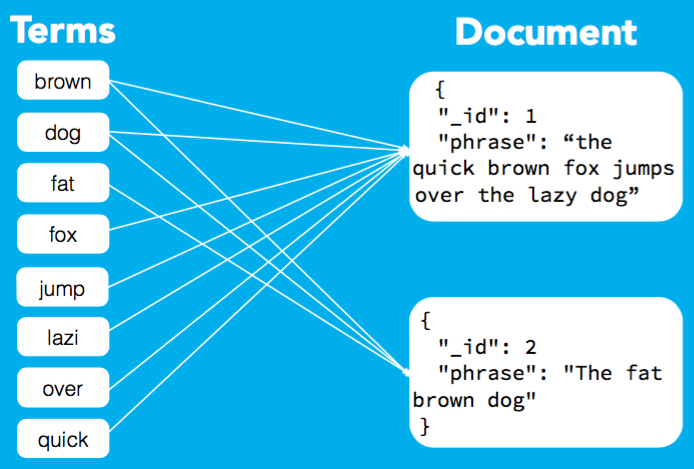
- Inverted Index: INDEX là 1 nơi chứa các DOCUMENT liên quan tới nhau. Hiểu nôm na INDEX là nơi sẽ giúp lưu trữ và thao tác với dữ liệu khi cần (Searching). Thay vì index theo từng đơn vị row(document) giống như mysql thì nó sẽ biến thành index theo đơn vị term. Cụ thể hơn, Inverted index là một cấu trúc dữ liệu, nhằm mục đích map giữa term và các document chứa term đó.

- Document: Document đơn giản là 1 đơn vị cơ bản nhất để có thể đánh index. Và cũng có thể coi nó tương tự Rows (hay Record) trong Sql. Trong Elasticsearch, Document được lưu dưới dạng JSON.
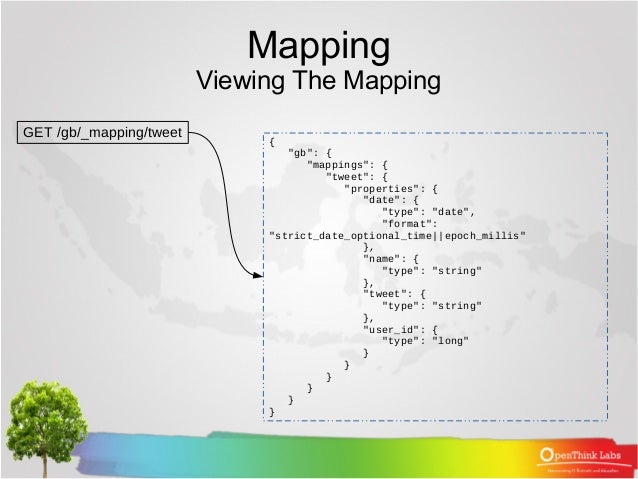
- Mapping: MAPPING là quá trình xử lý cách mà các DOCUMENT sẽ được index và lưu trữ như thế nào. MAPPING giúp chúng ta cùng lúc khởi tạo 1 field & định nghĩa các field đó được index.
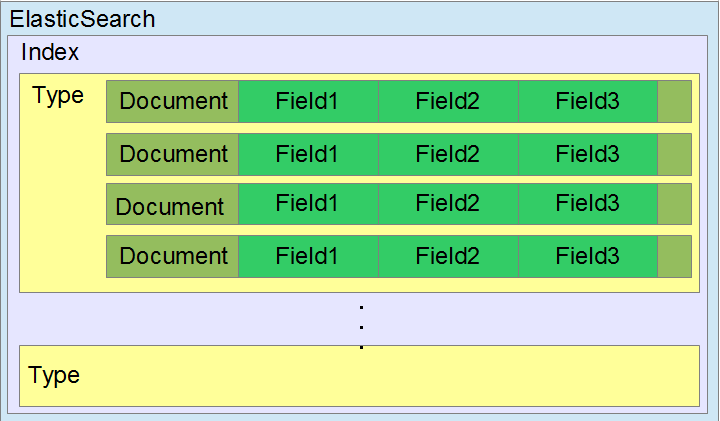
- Field: Một field giống như 1 cặp key-value. Value có thể là 1 giá trị đơn giản (string, integer, date), hay có thể là 1 cấu trúc lồng nhau như array hay object. Một field cũng tương tự như 1 cột của bảng trong db.

- Type: Một type gần giống như 1 bảng (table) trong database. Mỗi type có 1 danh sách các trường được chỉ định cho documents của type đó.
4. Cách thức hoạt động:
-
ví dụ 1: Ta có 3 document là D1, D2, D3
- D1 = "hom nay troi mua"
- D2 = "hom nay troi nang"
- D3 = "mot ngay dep troi" Theo đó ta sẽ có inverted index của 3 document trên là
- "hom" = {D1, D2}
- "nay" = {D1, D2}
- "troi" = {D1, D2, D3}
- "mua" = {D1}
- "nang" = {D2}
- "mot" = {D3}
- "ngay" = {D3}
- "dep" = {D3}
Nhìn vào kết quả của inverted index trên ta có thể thấy việc search full text sẽ diễn ra rất dễ dàng và nhanh chóng. nó chỉ là việc tính toán của các term. Ví dụ khi muốn query từ “hom nay” (tùy theo việc là query theo kiểu and hay or thì phép tính toán sẽ khác đi. ở đây sẽ lấy ví dụ là query theo kiểu and.) thì phép toán là: {D1, D2} ∩ {D1, D2} = {D1, D2} Kết quả thu được chính là document 1 và 2 (D1 and D2).
-
ví dụ 2: Ta có 2 câu sau:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
Để tạo ra một inverted index, trước hết chúng ta sẽ phân chia nội dung của từng tài liệu thành các từ riêng biệt (được gọi là terms), tạo một danh sách được sắp xếp của tất cả terms duy nhất, sau đó liệt kê tài liệu nào mà mỗi thuật ngữ xuất hiện. Kết quả như sau:
| Term | Doc 1 | Doc 2 |
|---|---|---|
| Quick | x | |
| The | x | |
| brown | x | x |
| dog | x | |
| dogs | x | |
| fox | x | |
| foxes | x | |
| in | x | |
| jumped | x | |
| lazy | x | x |
| leaf | x | |
| over | x | x |
| quick | x | |
| summer | x | |
| the | x |
Bây giờ, nếu muốn tìm kiếm màu quick brown, ta chỉ cần tìm trong các tài liệu trong đó mỗi thuật ngữ có xuất xuất hiện hay không. Kết quả như sau:
| Term | Doc 1 | Doc 2 |
|---|---|---|
| quick | x | |
| brown | x | x |
| Total | 2 | 1 |
Vậy kết quả show ra sẽ là câu văn thứ 1
5. Kết:
Elascticsearch là một công cụ hỗ trợ việc tìm kiếm cực kì mạnh mẽ và nhanh chóng, nhưng không phải dự án nào áp dụng Elascticsearch là hiệu quả, trái lại nó còn phát sinh ra nhiều lỗi không mong muốn. Vì vậy, hãy xem xét thật kỹ về yêu cầu của dự án trước khi áp dụng Elascticsearch vào.
All rights reserved
