Tìm hiểu chung về LLVM
This post hasn't been updated for 5 years
Không hề khó khăn khi nhận thấy rằng các ngôn ngữ lập trình được tạo ra cũng như cải tiến với tốc độ ngày một cao. Rust của Mozilla, Swift của Apple hay Kotlin của Jetbrain và nhiều ngôn ngữ khác cung cấp cho các nhà phát triển một loạt các lựa chọn mới về tốc độ, độ an toàn, sự tiện lợi, tính di động và sức mạnh. Nhờ LLVM - một framework để xây dựng nên trình biên dịch của một ngôn ngữ lập trình - giờ đây các nhà phát triển có thể tạo các ngôn ngữ của riêng họ mà không cần đi sâu vào chi tiết. Bộ công cụ này cung cấp các công cụ để tự động hóa nhiều phần không cần thiết nhất của nhiệm vụ tạo ngôn ngữ giúp cho việc tạo một ngôn ngữ mới cũng như cái tiến chúng trở nên dễ dàng hơn bao giờ hết.
LLVM
Theo như phần giới thiệu ở trang web chính thức chúng ta có:
LLVM is a collection of the modular and reusable compiler and toolchain technologies. “LLVM” is not an acronym; it is the full name of the project. Tạm dịch là: LLVM là một tập hợp các công nghệ toolchain và trình biên dịch mô-đun có thể tái sử dụng. “LLVM” không phải là từ viết tắt; nó là tên đầy đủ của dự án.
Xuất phát từ khái niệm Low Level Virtual Machine - Máy ảo cấp thấp, LLVM thường được xem là một khung để tạo nên các trình biên dịch được thiết kế để hỗ trợ phân tích và chuyển đổi chương trình suốt đời, suốt đời cho các chương trình tùy ý, bằng cách cung cấp thông tin cấp cao để chuyển đổi trình biên dịch tại thời điểm compile-time, link-time, run-time và idle time giữa các lần chạy. Nó cung cấp những công cụ mạnh mẽ để xây dựng phần front-end (parser, lexer) cũng như phần backend (phần chuyển phần code trung gian LLVM sang mã máy), cho các ngôn ngữ lập trình mới. LLVM đã được sử dụng để xây dựng nên nhiều bộ chuyển đổi (compiler) của nhiều ngôn ngữ lập trình cấp cao phổ biến hiện nay, ví dụ như C, C++, Python, Java, Ruby, cũng như Objective-C và Swift.
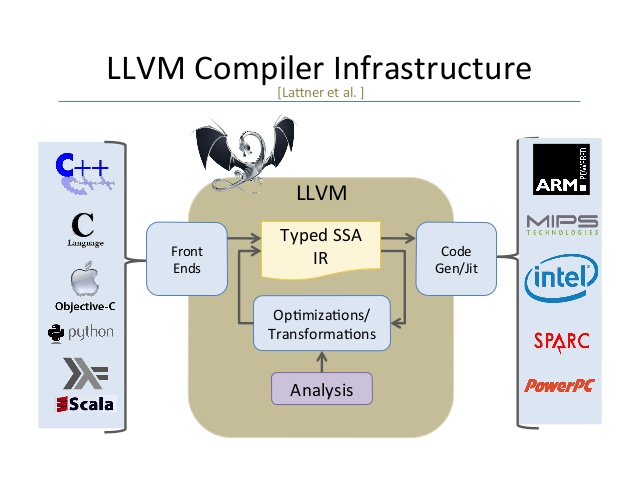
Như được thể hiện trong hình trên, một hệ sinh thái chương trình dịch LLVM gồm 3 phần:
- Front-end: phần này nhận đầu vào là các ngôn ngữ và chịu trách nhiệm thực hiện 3 bước gồm lexical analysis (phân tích từ tố) - đọc từng ký tự thành các token, syntax analysis (phân tích cú pháp) - parser chuyển các token ở bước trước thành AST (abstract syntas tree) và semantic analysis (phân tích ngữ nghĩa) - kiểm tra các thông tin khác ví dụ như type checking sau đó tạo mã trung gian
- Back-end: phần này sẽ chịu trách nhiệm tạo ra mã máy từ mã trung gian cho từng kiến trúc CPU cụ thể.
- Middle-end: được biết đến với cái tên "LLVM Optimizer", nó sử dụng một ngôn ngữ lập trình cấp thấp gọi là intermediate representation (IR) làm mã trung gian, thứ có thể tồn tại một số dạng dạng khác nhau tùy vào lập trình viên.IR được sử dụng nhằm mục đích chuyển đổi giữa kết quả của phần front-end sang back-end để có thể tạo mã đích hay chính xác hơn mã trung gian IR chính là output của front-end và input của backend.
Nhờ thiết kế độc lập của 3 thành phần dạng module, LLVM giúp các nhà phát triển rất dễ hỗ trợ thêm ngôn ngữ front-end mới, cũng như hỗ trợ cho các kiến trúc CPU mới ở phía back-end, ngay cả những kiến trúc không tồn tại ở thời điểm ứng dụng ra đời. Cùng với nhiều công cụ mạnh mẽ khác, dự án LLVM mang đến sức mạnh, tốc độ, an toàn cùng với tiên lợi cho hầu hết các ngôn ngữ hiện đại ngày nay.
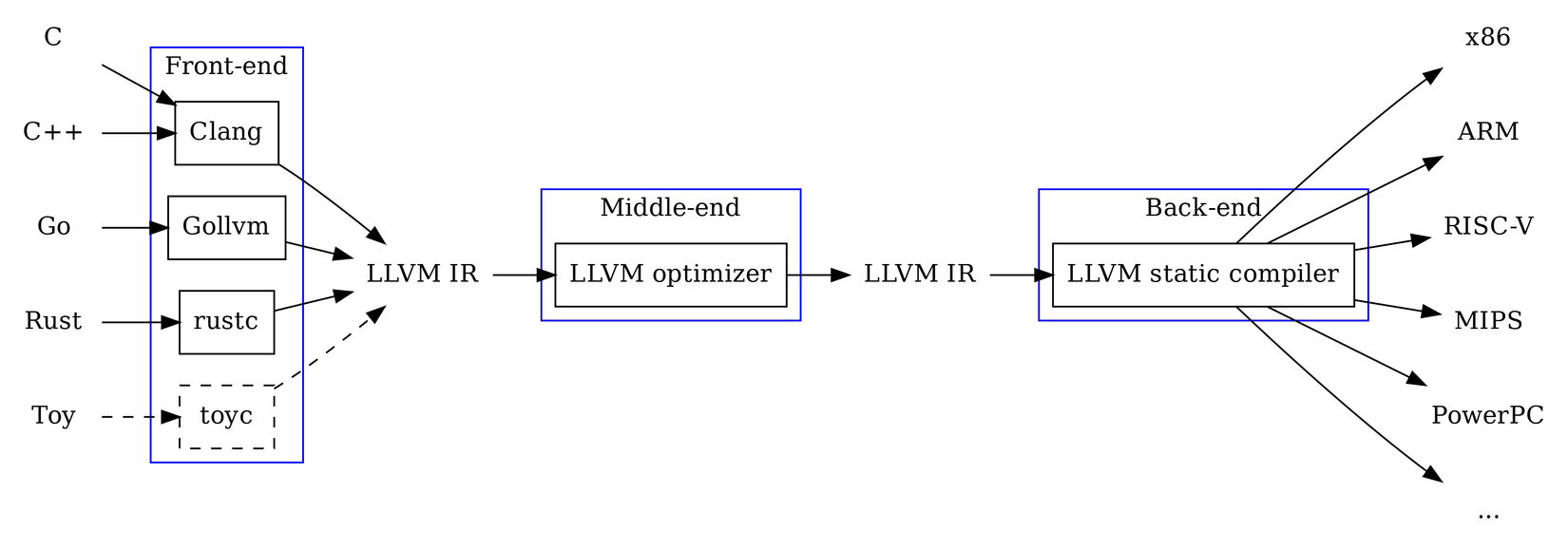
LLVM IR
Như giới thiệu ở trên LLVM IR hay mã đại diện trung gian của LLVM là một loại mã đại diện trung gian cấp thấp được sử dụng bởi khung biên dịch LLVM. Ta có thể coi LLVM IR là một ngôn ngữ hợp ngữ độc lập với nền tảng với vô số thanh ghi cục bộ chức năng. Khi phát triển các trình biên dịch, có những lợi ích to lớn khi biên dịch ngôn ngữ nguồn sang một đại diện trung gian (IR) thay vì biên dịch trực tiếp đến một kiến trúc đích (ví dụ: x86) có thể kể đến như như có thể thực hiện các phương pháp tối ưu trực tiếp ở mức IR chẳng hạn như loại bỏ mã chết, lan truyền liên tục, ... từ đó cải thiện đáng kể hiệu năng cũng như tiết kiệm tài nguyên cho khi thực thi các đoạn mã trên.
Quá trình biên dịch của Rust
Để có thể hình dung rõ hơn về LLVM IR, phần sau chủ yếu được dịch từ bài viết 從 LLVM IR 來看編譯器最佳化都在做些什麼 cho hình dung được cách LLVM IR được sử dụng và tối ưu như thế nào. Do Rust là ngôn ngữ cấp cao nên việc biên dịch trực tiếp vào Assembly cấp thấp nhất là điều không dễ dàng, do đó, tác giả mô tả quá trình biên dịch Rust sẽ được chia thành hai giai đoạn như sau:
Biên dịch mã nguồn thành LLVM IR

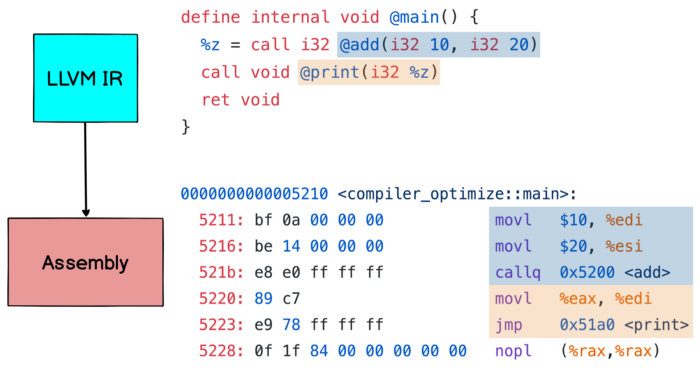
Bằng cách sử dụng câu lệnh cargo build --release trình biên dịch thực thi bước đầu tiên trong quá trình biên dịch và tạo ra mã IR và thực hiện quá trình tối ưu bằng cách loại bỏ việc gán giá trị cho x và y do việc gán giá trị cho hai biến này không cần thiết. Thay vào đó câu lệnh let z = add(10, 20) được thay thế và trình biên dịch sẽ sinh mã thành %z = call i32 @add(i32 10, i32 20)
Quan sát phần mã IR trên, chúng ta có thể thấy rằng :
- LLVM IR được nhập tĩnh (nghĩa là các giá trị số nguyên 32 bit được ký hiệu bằng kiểu i32).
- Mỗi biến được gán chính xác một lần, được đặt tên bằng ký tự%.
Ngoài ra, từ ví dụ được cung cấp ở bài viết LLVM IR and Go, chúng ta có thấy thấy rằng:
- Các biến cục bộ được xác định phạm vi cho từng hàm (tức là
%1trong hàm@mainkhác với%1trong hàm@f). - Thanh ghi chưa được đặt tên (tạm thời) được chỉ định ID cục bộ (ví dụ:
%1,%2) từ bộ đếm tăng dần trong mỗi hàm. - Mỗi hàm có thể sử dụng vô số thanh ghi (tức là nó không giới hạn ở 32 thanh ghi mục đích chung).
- Các biến toàn cục (ví dụ:
@f) và biến cục bộ (ví dụ:%a,%1) được phân biệt bằng tiền tố của chúng (tương ứng là@và%). - Dòng chú thích được bắt đầu bằng ký tự
;như khá phổ biến đối với các ngôn ngữ hợp ngữ.

Thêm nữa có thể thấy rằng mã IR được sinh từ 2 ngôn ngữ C và Rust đều tương tự nhau. Điều đó chứng tỏ rằng LLVM IR là ngôn ngữ không phụ thuộc vào nền tảng.
Tạo Assembly từ LLVM IR
Với LLVM IR được tạo trong giai đoạn đầu tiên, trình biên dịch sau đó sẽ chuyển IR thành một hợp ngữ cấp thấp hơn trong đó một lệnh chỉ có thể có một hành động và địa chỉ của biến và hàm cũng phải được ghi rõ ràng.
Tổng kết
Thông thường rất ít khi mã nguồn cần biên dịch lại ngắn gọn như vậy và quá trình biên dịch thường phức tạp hơn rất nhiều. Ví dụ trên chỉ cung cấp cho chúng ta cái nhìn cơ bản về các bộ compiler dựa trên LLVM và LLVM IR hoạt động như thế nào. Trong các bài viết tiếp theo (nếu như được viết) mình sẽ trình bày các ví dụ về cách mã LLVM IR được tối ưu bằng các phương pháp chẳng hạn như constant folding, inlining functions, loop unrolling, ... cũng như sẽ làm một bộ compiler đơn giản dựa trên tutorial của LLVM. Bài viết đến đây là hết cảm ơn các bạn đã dành thời gian đọc.
Tài liệu tham khảo
All Rights Reserved
