Tìm hiểu chung về Elasticsearch
Bài đăng này đã không được cập nhật trong 6 năm

Elasticsearch là gì?
Elasticsearch là một công cụ tìm kiếm với nhiều REST API đơn giản có khả năng phân tích và lưu trữ tất cả các dữ liệu có dạng như textextual, digital, geospatial, structured và unstructured một cách nhanh chóng (near real-time).
Elasticsearch ra mắt năm 2010, được phát triển bởi Shay Banon bằng ngôn ngữ Java, là mã nguồn mở theo giấy phép Apache 2.0 và phân tán thời gian thực, có khả năng mở rộng cao và hoạt động dựa trên nền tảng Apache Lucene.
Elasticsearch có thể mở rộng lên tới hàng petabyte dữ liệu dạng có cấu trúc và không cấu trúc. Nó cũng có thể được sử dụng thay thế cho các DB lưu trữ dữ liệu document như MongoDB hay RavenDB. Sử dụng tính không chuẩn hóa để cải thiện hiệu suất tìm kiếm.
Elasticsearch là một trong những công cụ tìm kiếm doanh nghiệp rất phổ biến và hiện đang được sử dụng bởi nhiều tổ chức lớn như Wikipedia, The Guardian, StackOverflow, GitHub, …

Khi nào nên sử dụng Elasticsearch?
Chúng ta nên sử dụng Elasticsearch trong những trường hợp sau:
- Searching for pure text (textual search): tìm kiếm text thông thường.
- Searching text and structured data (product search by name + properties): tìm kiếm text và dữ liệu có cấu trúc.
- Data aggregation, security analytics, analysis of business data: tổng hợp dữ liệu, phân tích bảo mật, phân tích dữ liệu kinh doanh, lưu trữ số lượng dữ liệu lớn.
- Logging and log analytics: ghi lại quá trình hoạt động và phân tích nó.
- Application performance monitoring: giám sát hiệu năng ứng dụng.
- Infrastructure indicators and container monitoring.
- Geo Search: tìm kiếm theo tọa độ, phân tích và trực quan hóa dữ liệu không gian địa lý.
- JSON document storage: lưu trữ dữ liệu dạng JSON.
Những khái niệm cơ bản trong Elasticsearch
1. Node
Là một instance (server) đơn lẻ duy nhất đang chạy của Elasticsearch. Nơi lưu trữ dữ liệu , tham gia thực hiện đánh index của cluster và thực hiện tìm kiếm.
Mỗi node được định danh bằng một unique name, được đặt mặc định ngẫu nhiên bởi Universally Unique IDentifier (UUID) tiến hành khi thiết lập hoặc tự định danh. Tên của node rất quan trọng trong việc xác định node này thuộc cluster nào trong Elasticsearch.
2. Cluster
Là tập hợp của một hoặc nhiều nodes hoạt động cùng nhau, có khả năng tìm kiếm và lập chỉ mục trên tất cả các nodes cho toàn bộ dữ liệu. Chức năng chính của Cluster là quyết định xem shards nào được phân bổ cho node nào và khi nào thì di chuyển các node để cân bằng lại Cluster.
Mỗi cluster được định danh bằng một unique name, sử dụng chung cho tất cả các nodes, do vậy việc định danh các cluster trùng tên sẽ gây nên lỗi cho các nodes.
Mỗi cluster có một node chính (master) được lựa chọn tự động và có thể thay thế khi gặp sự cố.
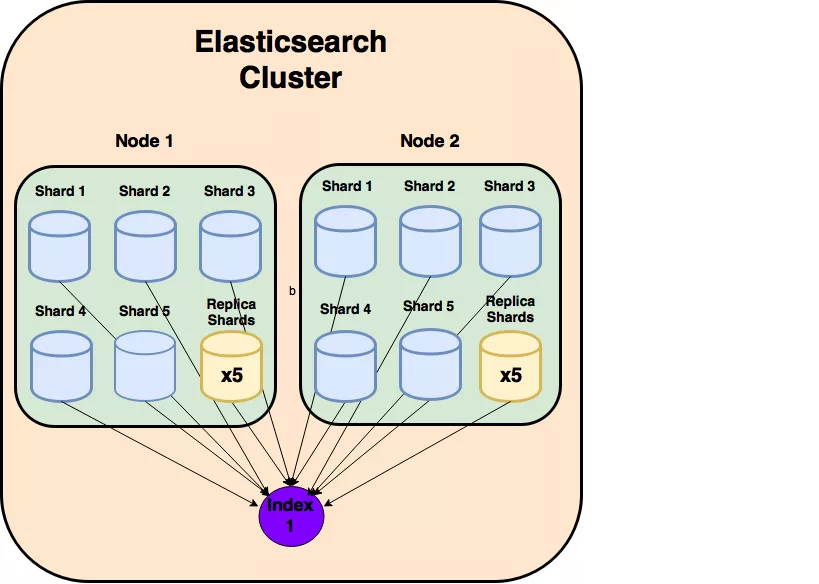
3. Document
Nó là đơn vị dữ liệu cơ bản trong Elasticsearch - đối tượng JSON với một số dữ liệu cụ thể. Mỗi document thuộc một type và nằm trong một chỉ mục. Mỗi document được liên kết với một định danh duy nhất được gọi là UID.
Elasticsearch sử dụng inverted index để đánh chỉ mục cho các document. Inverted index là một cách đánh chỉ mục dựa trên đơn vị là từ nhằm mục đích tạo mối liên kết giữa các từ và các document chứa từ đó.
4. Type
Được sử dụng làm danh mục của chỉ mục, cho phép lưu trữ các loại dữ liệu khác nhau trong cùng một chỉ mục.
5. Index
Nó là một tập hợp các loại document khác nhau và các thuộc tính của chúng, giúp lưu trữ một lượng lớn dữ liệu có thể vượt qua giới hạn phần cứng của node làm chậm quá trình phản hồi các request từ những node đơn. Do vậy, Index sử dụng khái niệm shards (phân đoạn) để chia nhỏ thành nhiều phần giúp cải thiện hiệu suất.
Khi tạo index, có thể xác định số lượng shard mà bạn muốn.
Index cũng được định danh bằng tên, tên này được sử dụng khi thực hiện các hoạt động lập chỉ mục, tìm kiếm, cập nhật hoặc xóa các document trong index.
6. Shard
Các index được chia theo chiều ngang thành các shard, mỗi shard chứa tất cả các thuộc tính của document nhưng chứa ít đối tượng JSON hơn index. Sự phân tách ngang làm cho shard là một node độc lập, có thể được lưu trữ trong bất kỳ node nào. Do vậy, một node có thể có nhiều Shard, vì thế Shard sẽ là đối tượng nhỏ nhất, hoạt động ở mức thấp nhất, đóng vai trò lưu trữ dữ liệu.
Shard rất quan trọng vì:
- Cho phép phân mảnh theo chiều ngang mở rộng khối lượng bản ghi
- Cho phép phân tán và hoạt động song song trên các phân đoạn, nhờ đó tăng hiệu suất làm việc.
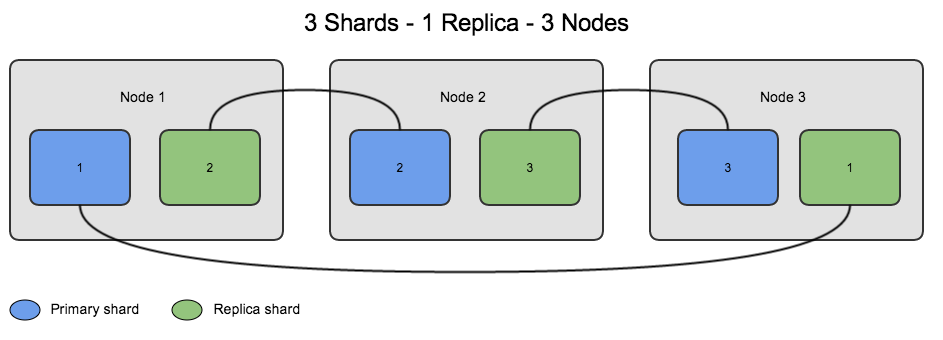
Có 2 loại shard được sử dụng là Primary Shard và Replica Shard.
Primary Shard
- Primary Shard là phần nằm ngang gốc của một index và sau đó các primary shard này được sao chép thành các Replicas Shard.
- Primary Shard là sẽ lưu trữ dữ liệu và đánh index . Sau khi đánh xong dữ liệu sẽ được vận chuyển tới các Replica Shard.
- Mặc định của Elasticsearch là mỗi index sẽ có 5 Primary Shard và mỗi Primary Shard thì sẽ đi kèm 1 Replica Shard.
Replica Shard
- Nơi lưu trữ dữ liệu sao chép của Primary Shard, khả năng sẵn sàng cao, thay thế Primary Shard khi có lỗi. Đó cũng là lý do vì so Replica Shard không được phân bố trên cùng một node với Primary Shard mà chỉ được sao chép từ nó.
- Đảm bảo tính toàn vẹn của dữ liệu khi Primary Shard xảy ra vấn đề như bị ẩn hay biến mất.
- Tăng cường tốc độ tìm kiếm bởi có thể setup lượng Replica Shard nhiều hơn mặc định của
Elasticsearchhoặc thực hiện thao tác tìm kiếm song song trong các bản sao này.
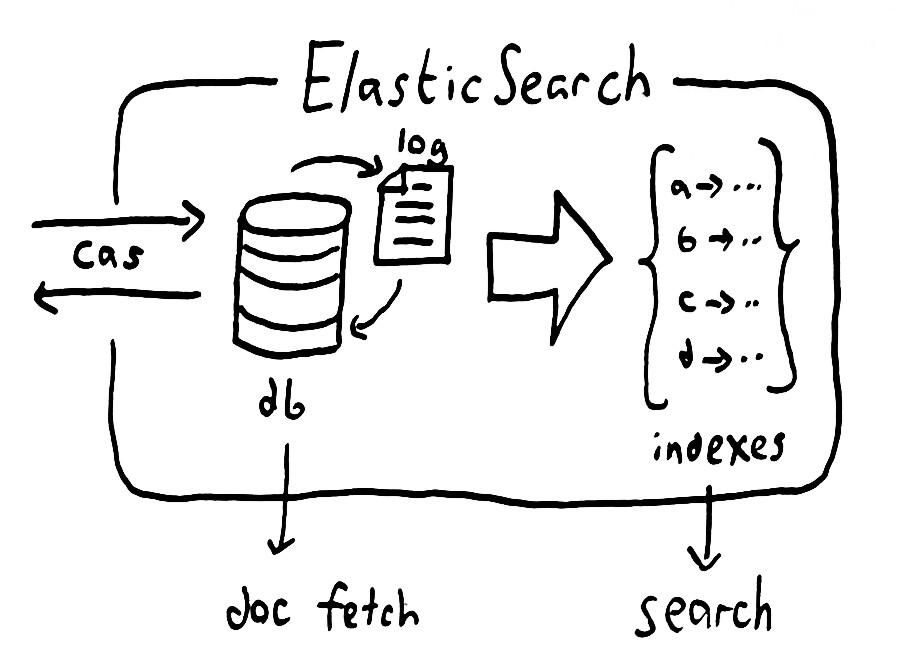
Cách hoạt động của Elasticsearch
Elasticsearch được xây dựng để hoạt động như một server riêng biệt theo cơ chế của RESTful phục vụ việc tìm kiếm dữ liệu.
Đầu tiên, dữ liệu thô (raw data) vào Elasticsearch từ nhiều nguồn như log, system indicators và webapp sẽ được phân tích, xử lý, bình thường hóa (normalizes) và làm phong phú thêm (enriches) trong quá trình nhập liệu (Data ingestion) trước khi được lập chỉ mục (index) và đẩy lên Server Elasticsearch ở bước thứ 2 (cách lập chỉ mục mình sẽ có một bài viết chi tiết hơn, không nhắc đến trong này).
Cuối cùng, sau khi dữ liệu được lập chỉ mục, người dùng có thể tạo các truy vấn phức tạp từ dữ liệu này và sử dụng các tập hợp (aggregations) để truy xuất các bản tóm tắt phức tạp của dữ liệu hay nói ngắn gọn là lấy data trả về từ server Elasticsearch.
Ưu và nhược điểm của Elasticsearch
1. Ưu điểm
- Elasticsearch cho phép tìm kiếm dữ liệu một cách nhanh chóng với hiệu năng cao gần như là real-time (near-realtime searching) bởi Elasticsearch được thiết kế dựa trên Apache Lucene có khả năng vượt trội trong mảng full-text research.
- Hỗ trợ tìm kiếm mờ (fuzzy search), tức là từ khóa tìm kiếm có thể bị sai lỗi chính tả hoặc không đúng cú pháp nhưng Elasticsearch vẫn có thể trả về kết quả đúng.
- Elasticsearch hỗ trợ hầu hết mọi loại dữ liệu, trừ những kiểu dữ liệu không hỗ trợ hiển thị dưới dạng văn bản (text).
- Độ trễ giữa thời gian lập chỉ mục document và tìm kiếm nó là rất ngắn (khoảng 1s), do đó, Elasticsearch rất phù hợp cho các trường hợp cần sử dụng khẩn cấp như phân tích bảo mật hoặc giám sát cơ sở hạ tầng (security analyzes và infrastructure monitoring).
- Lưu trữ dữ liệu full-text và quản lý vòng đời chỉ mục, cho phép người dùng truy xuất và phân tích, tổng hợp lượng dữ liệu rất lớn với tốc độ cao, hiệu quả hơn.
- Elasticsearch là hệ thống phân tán tự nhiên, dễ dàng mở rộng và tích hợp mạnh mẽ. Các document được lưu trữ trong Elasticsearch được phân tán trong các container khác nhau được gọi là các phân vùng (partitions), được duplicated để tích hợp với các bản sao dữ liệu trùng lặp trong trường hợp xảy ra lỗi phần cứng. Bản chất phân tán của Elasticsearch cho phép nó mở rộng hàng trăm (hàng nghìn) máy chủ và quản lý hàng petabyte dữ liệu.
- Dễ dàng phục hồi dữ liệu bằng các bản sao lưu đầy đủ được tạo bởi các khái niệm gateway trong Elasticsearch.
- Elasticsearch hoạt động như một server cloud, response format JSON và được viết bởi Java nên nó có thể hoạt động được trên nhiều nền tảng khác nhau, đồng thời tương tác, hỗ trợ nhiều ngôn ngữ lập trình như Java, JavaScript, Node.js, Go, .NET (C#), PHP, Perl, Python, Ruby. Do đó cũng là một điểm yếu khi độ bảo mật không cao.
2. Nhược điểm
- Elasticsearch không cung cấp bất kỳ tính năng nào cho việc xác thực và phân quyền (authentication or authorization) khiến ElasticSearch kém bảo mật hơn so với các hệ quản trị cơ sở dữ liệu hiện nay.
- Elasticsearch được thiết kế cho mục đích tìm kiếm nên thường không dùng làm DB chính. Elasticsearch không mạnh trong các thao tác CRUD, nên thường sẽ dùng song song cùng một DB chính như SQL, MySQL, MongoDB, ...
- Một lý do khác không nên sử dụng Elasticsearch làm DB chính là Elasticsearch không hỗ trợ transaction (database transaction), nó sẽ không đảm bảo được toàn vẹn dữ liệu trong các hoạt động
insert,update,deletedễ dẫn tới mất mát dữ liệu. - Không phù hợp với những hệ thống thường xuyên cập nhật dữ liệu do sẽ rất tốn kém trong việc lập chỉ mục dữ liệu.
- Elasticsearch không hỗ trợ xử lý request và response bằng nhiều định dạng (chỉ dùng JSON) so với một search engine khác cũng xây dựng dựa trên Lucene như Apache Solr (hỗ trợ JSON, CSV, XML).
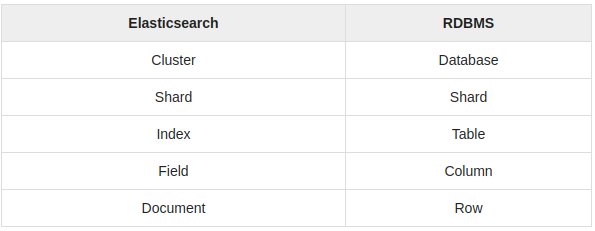
Elasticsearch vs RDBMS
Kết luận
Bài viết này tổng hợp khái quát về một số vấn đề cơ bản trong Elasticsearch, mình hy vọng có thể giúp đỡ được mọi người hiểu rõ hơn về Elasticsearch. Rất cảm ơn các bạn đã theo dõi bài viết. Good luck 
All rights reserved
