Tích hợp Chunking vào Pipeline Huấn luyện AI: Hướng dẫn chi tiết dành cho Developer
Trong các hệ thống AI vận hành trên lượng dữ liệu lớn, khả năng xử lý tuần tự và duy trì ngữ cảnh là yếu tố then chốt quyết định chất lượng mô hình. Một trong những kỹ thuật quan trọng giúp pipeline vận hành ổn định và chính xác là chunking – chia nhỏ dữ liệu thô thành các phần tối ưu cho quá trình embedding và huấn luyện.
Bài viết dưới đây trình bày cách tích hợp chunking vào một pipeline huấn luyện AI hiện đại theo hướng tự động hóa, phù hợp cho developer xây dựng RAG system, LLM fine-tuning hoặc AI Agent.
Vì sao cần Chunking trong quy trình huấn luyện AI
Chunking là kỹ thuật tách dữ liệu văn bản lớn thành các đoạn nhỏ hơn theo kích thước cố định (thường tính bằng token). Phương pháp này giải quyết các vấn đề thường gặp trong huấn luyện mô hình:
- Giới hạn context window: Mô hình không thể đọc tài liệu quá dài (ví dụ context 8k/16k token).
- Tối ưu chi phí: Xử lý nhiều đoạn nhỏ giúp tiết kiệm tài nguyên GPU/CPU và giảm số token cho quá trình embedding.
- Ổn định ngữ nghĩa: Các chunk nhỏ giúp mô hình tập trung vào vùng nội dung có liên kết ngữ cảnh chặt chẽ hơn.
- Hỗ trợ RAG hiệu quả: Mỗi chunk có thể embedding độc lập và lưu vào vector database, dễ truy vấn ngữ nghĩa chính xác.
Ví dụ thực tế: Một tài liệu 100.000 ký tự sẽ được chia thành các đoạn 500–800 token. Mỗi đoạn giữ lại phần overlap để duy trì ngữ cảnh liên tục. Điều này giúp mô hình không bỏ sót thông tin quan trọng trong quá trình huấn luyện hoặc truy hồi.
Chunking nằm ở đâu trong pipeline AI?
Thông thường, pipeline xử lý dữ liệu huấn luyện bao gồm:
Thu thập dữ liệu → Làm sạch → Tiền xử lý → Chunking → Embedding → Lưu trữ → Huấn luyện
Chunking đóng vai trò như lớp trung gian giúp:
- Chuẩn hóa văn bản trước khi tạo vector.
- Tránh lãng phí khi embedding dữ liệu quá dài.
- Bảo đảm dữ liệu có cấu trúc nhất quán dù nguồn đầu vào đa dạng: PDF, DOCX, HTML, API,...
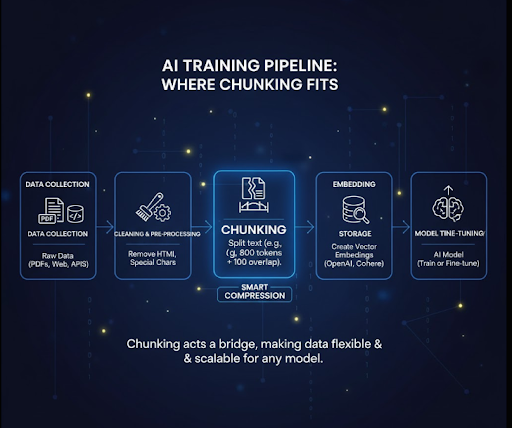
Luồng xử lý tiêu biểu
- Nạp dữ liệu thô từ nhiều nguồn.
- Loại bỏ HTML, ký tự lỗi, khoảng trắng dư thừa.
- Tách văn bản thành chunk theo biến số cấu hình.
- Sinh embedding bằng OpenAI, Cohere hoặc SentenceTransformers.
- Lưu vector vào Chroma, Pinecone, FAISS,...
- Chuyển dữ liệu sang giai đoạn huấn luyện/fine-tuning hoặc tích hợp vào RAG.
Demo: Tích hợp Chunking tự động bằng Python
Ví dụ dưới đây mô phỏng pipeline chunking sử dụng RecursiveCharacterTextSplitter từ LangChain – thư viện phổ biến để xây dựng RAG/LLM pipeline.
from langchain.text_splitter import RecursiveCharacterTextSplitter
def clean_text(text):
text = text.replace("\n", " ").replace("\t", " ")
return " ".join(text.split())
def chunk_documents(docs, chunk_size=500, chunk_overlap=100):
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
chunks = []
for doc in docs:
cleaned_doc = clean_text(doc)
chunks.extend(splitter.split_text(cleaned_doc))
return chunks
# Pipeline mẫu
def ai_training_pipeline(raw_docs):
print("Khởi tạo pipeline huấn luyện AI...")
# 1. Làm sạch dữ liệu
print("Tiền xử lý...")
cleaned_data = [clean_text(doc) for doc in raw_docs]
# 2. Chunking
print("Thực hiện chunking...")
chunked_data = chunk_documents(cleaned_data)
# 3. Embedding
print("Sinh embedding...")
embeddings = create_embeddings(chunked_data)
# 4. Huấn luyện mô hình
print("Huấn luyện model...")
train_model(embeddings)
print("Pipeline hoàn tất.")
Ưu điểm khi tích hợp vào production
- Dễ chạy qua workflow engine như n8n, Airflow, Prefect.
- Có thể lưu chunk vào Chroma/Pinecone để tái sử dụng nhiều lần.
- Tối ưu hóa cho hệ thống AI Agent hoặc RAG enterprise.
Lựa chọn tham số Chunking tối ưu
Hai tham số cốt lõi:
| Tham số | Ý nghĩa | Khuyến nghị |
|---|---|---|
| chunk_size | Kích thước tối đa mỗi đoạn (token) | 300–800 token |
| chunk_overlap | Phần chồng lặp để giữ ngữ cảnh | 10–20% chunk_size |
| embedding_window | Giới hạn token cho model embedding | 512/1024/2048 tùy model |
Tối ưu chunking giúp:
- Giảm token count trong embedding.
- Tăng chất lượng semantic search.
- Cải thiện độ chính xác khi fine-tuning.
Đánh giá hiệu quả sau khi thêm Chunking
Bạn có thể đo lường qua các chỉ số:
- Thời gian xử lý dữ liệu theo mỗi batch.
- Độ chính xác mô hình: F1/Accuracy khi fine-tuning.
- Hiệu quả Retrieval trong RAG (hit-rate, MRR, recall).
- Chi phí huấn luyện: số token, thời gian GPU.
Nhiều đội kỹ sư ghi nhận chunking giúp:
- Giảm 20–30% chi phí huấn luyện.
- Tăng rõ rệt chất lượng truy hồi dữ liệu.
- Cải thiện độ ổn định khi pipeline chạy ở quy mô lớn.
Tự động hóa chunking trong production
Tùy theo kiến trúc hệ thống, bạn có thể:
- Tạo DAG chunking chạy định kỳ với Airflow.
- Xử lý real-time khi có tài liệu mới qua n8n webhook.
- Lưu trữ tập trung tại vector DB cho toàn bộ AI Agent.
- Kết hợp Bizfly Cloud Storage/CDN khi cần tối ưu phân phối và bảo toàn dữ liệu.
Kết luận
Chunking là một bước nhỏ nhưng có tác động lớn đến toàn bộ workflow huấn luyện AI. Việc áp dụng chunking đúng cách giúp:
- Dữ liệu chuẩn hóa tốt hơn
- Embedding chính xác hơn
- Pipeline linh hoạt, mở rộng nhanh
- Chi phí hệ thống giảm đáng kể
Nếu bạn đang xây dựng pipeline AI cho doanh nghiệp hoặc một hệ thống RAG quy mô lớn, chunking là thành phần nên được triển khai từ giai đoạn đầu để đảm bảo khả năng mở rộng bền vững.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-tich-hop-chunking-vao-pipeline-huan-luyen-ai.html
All rights reserved
