Thử crawling dữ liệu Viblo bằng Mechanize gem
Bài đăng này đã không được cập nhật trong 6 năm
Thuật ngữ crawling đã quá quen thuộc với ae trong ngành chúng ta (nếu các bạn chưa biết crawling là gì thì xem qua ở đây nhé crawling), nge vậy thôi chứ làm việc với thằng này thì có lẽ ít người đã từng, chủ yếu là những ae làm về AI, thường craw data từ những forum cho con bot nó học. Hôm nay mình mạo muội thử crawling các bài viết trên trang Viblo và lưu nó vào file csv bằng ngôn ngữ ruby xem thế nào nhé. Bắt đầu thôi... 
Chuẩn bị
- Ruby version: ruby 1.9.2 or newer
- Qua một hồi tìm hiểu về crawling data bằng ruby thì mình thấy cũng khá là nhiều gem hỗ trợ cho việc này nhưng mình thấy mechanize gem hỗ trợ khá là đầy đủ và dễ dùng, vậy nên mình sẽ áp dụng mechanize gem cho công cuộc crawling data ở bài viết này.
Tìm hiểu về mechanize
1. Mechanize là gì?
- Mechanize là một thư viện hỗ trợ cho việc tự động tương tác với website, mechanize cho phép lưu trữ và gửi cookie, cho phép links và submit form.
2. Tính năng của mechanize
Truy cập url
require 'rubygems'
require 'mechanize'
agent = Mechanize.new
page = agent.get('https://www..asia.com/')
Tương tác với đường dẫn(links) trong page
linksLấy danh sách các đường dẫn có trong page
page.links.each do |link|
puts link.text
end
findtìm kiếm đường dẫn
# tìm kiếm đường dẫn có text là Newest
newest_link = agent.page.links.find { |l| l.text == 'Newest' }
link_withtìm kiếm với điều kiện
# tìm kiếm với option là text = Newest
newest_link = agent.page.link_with(text: 'Newest')
# tìm kiếm với option là href = /newest
newest_link = agent.page.link_with(href: '/newest')
# hoặc có thể kết hợp cả 2 hay nhiều option
newest_link = agent.page.link_with(text: 'Newest', href: '/newest')
Tương tác với form
Ở ví dụ này chúng ta thử search ở trên trang http://google.com/ xem nhé.
require 'rubygems'
require 'mechanize'
agent = Mechanize.new
page = agent.get('http://google.com/')
Để xem cấu trúc của page dưới format dễ nhìn thì chúng ta sử dụng pp
pp page
Bạn quan sát terminal sẽ thấy được một form với tên là 'f', trong form có một số filed và 2 button. Hãy thử tương tác với form bằng một số method sau nhé.
# truy suất form có tên là 'f'
google_form = page.form('f')
Mechanize hỗ trợ một số cách để để bạn có thể tương tác với input filed trong form nhưng cách thông dụng nhất đó là bạn có thể truy cập input field như một thuộc tính của một object. Trong ví dụ trên ta có input filed với name là q và cách tương tác với field này như sau:
google_form.q = 'Thử crawling dữ liệu Viblo bằng Mechanize gem'
Sau đó bạn thử print form ra màn hình console xem thành công chưa nhé
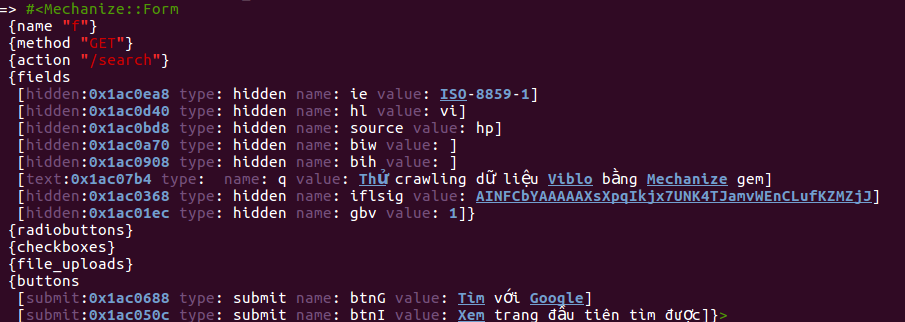
Và bây giờ thử nhấn btn search nhé
search_page = agent.submit(google_form)
pp search_page
Và file code hoàn chỉnh của ví dụ trên:
require 'rubygems'
require 'mechanize'
agent = Mechanize.new
page = agent.get('http://google.com/')
google_form = page.form('f')
# mình thêm force_encoding bởi vì các value search phải convert về encode ISO-8859-1
google_form.q = 'Thử crawling dữ liệu Viblo bằng Mechanize gem'.force_encoding("ISO-8859-1")
search_page = agent.submit(google_form)
pp search_page
Ngoài ra mechanize còn hỗ trợ thêm một số hàm khác giúp bạn tương tác với form nhìu hơn như field_with, file_uploads. Ở bài viết này mình chỉ giới thiệu cho mn làm quen với mechanize nên không đi chi tiết. Để rõ hơn thì mn xem GUIDE_DOC nhé
Thực hành crawling các bài viết trên Viblo
Nội dung bài thực này chỉ đơn giản là crawling tất cả các bài viết có trên trang web Viblo và lưu vào file csv, thông tin crawling gồm có tên tác giả, tiêu đề bài viết và đường dẫn của bài viết.
1. Init project
# tạo folder
mkdir crawling
# di chuyển vào thư mục dự án
cd crawling
# tạo file Gemfile
touch Gemfile
# mở Gemfile và paste đoạn code phía dưới vào
source 'https://rubygems.org'
gem 'rspec', :require => 'spec' # để hỗ trợ viết test sau này
gem 'mechanize' # gem này chúng ta vừa tìm hiểu ở trên
gem 'pry', '~> 0.12.2' # dùng để debug
# quay lại màn hình terminal và chạy lệnh
bundle install
-> như vậy là chúng ta đã hoàn thành bước khởi tạo project, tiếp tục vào phần chính nhé :D
2. Triển khai crawling data
a) Khởi tạo service Crawler
require "mechanize"
require "pry"
require "csv"
class CrawlerService
# HEADER chứa mảng các column name trong file csv
HEADER = %w(Author\ name Title Url)
# sử dụng để tìm kiếm button pagenation
BASE_PAGINATE_URL = "/newest?page="
# URL của trang web mình sẽ crawl data
URL = "https://viblo.asia/newest"
def initialize
@agent = Mechanize.new
@page_number = 1
end
end
b) Viết hàm thực thi việc crawling data
Trước tiên mình xem qua cấu trúc DOM của trang viblo
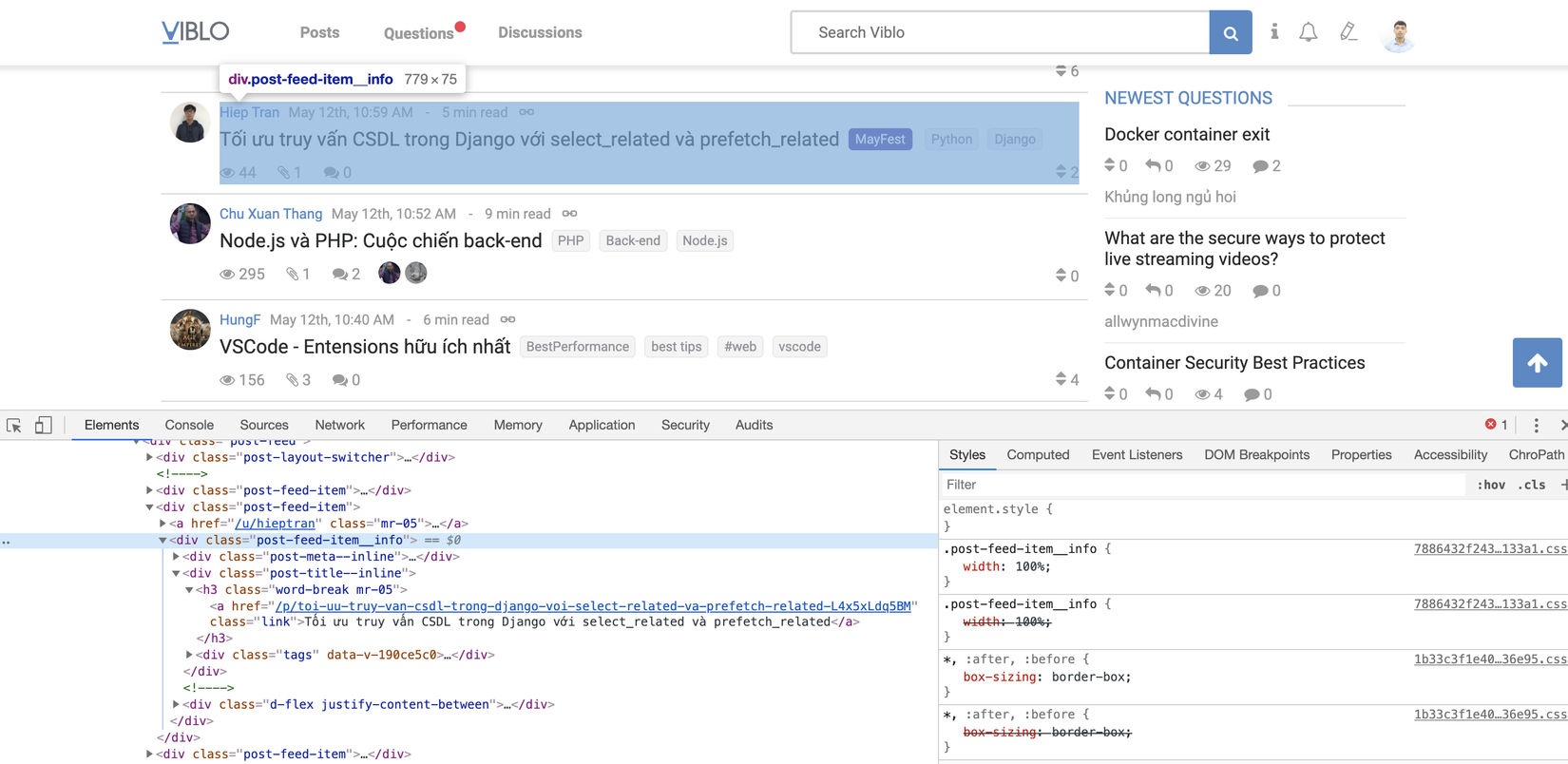
Nhìn ở hình trên thì ta xác định được thông tin của một bài viết nằm trong thẻ div có class post-feed-item__info, vậy nên mình sẽ dùng search method để lấy tất cả các bài viết có trong page.
def perfom
page = @agent.get URL
puts "------------------"
puts "Crawling.........."
# tìm kiếm các bài viết
page.search("div.post-feed-item__info").each do |post|
puts post
end
puts "------------------"
puts "Crawling finished."
end
Khi đã crawl được các bài viết, bây giờ chúng ta đi vào xem chi tiết cấu trúc DOM của từng bài để lấy những thông tin cần thiết nhé. Ở đây mình sẽ lấy author_name, title, url của bài viết.
Có 2 cách để bạn có thể truy suất dữ liệu của element:
- Cách 1 truy suất thông qua thuộc tính children
def perfom
...
page.search("div.post-feed-item__info").each do |post|
author_name = post.children.first.children.first.children[2].children[1].children.text.strip
title = post.children[2].children.first.children.first.children.first.text.strip
url = post.children[2].children.first.children.first.attributes["href"].value.strip
end
...
end
- Cách 1 truy suất thông qua hàm
search
def perfom
...
page.search("div.post-feed-item__info").each do |post|
author_name = post.search("a.mr-05").text.strip
title = post.search("h3.word-break").last.text
url = post.search("a.link").last.attributes["href"].value
puts author_name
puts author_name
end
...
end
Kết quả thu được
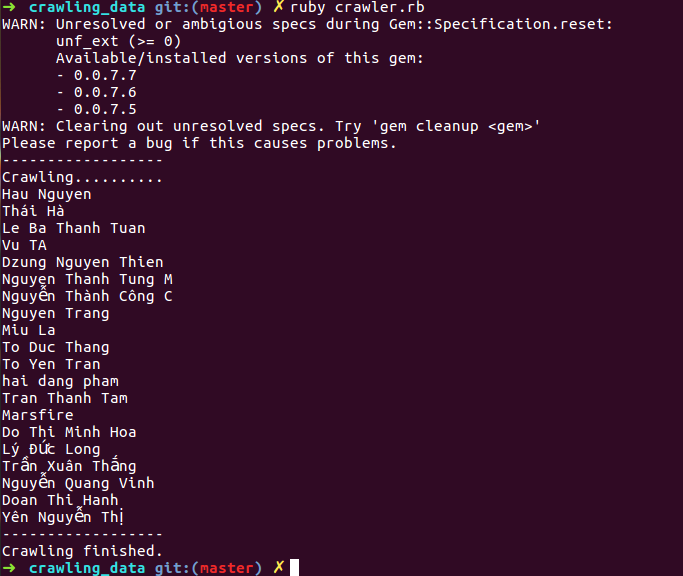
-
Tới đây thì con crawl của mình cũng tạm ổn rồi, tuy nhiên chúng mới chỉ chỉ crawl data ở trang đầu tiên, để crawl được hết các bài viết trên viblo thì chúng ta phải thêm chút mắm muối nữa nhé
-> Ý tưởng là mình sẽ click ở button phân trang ở phía dưới danh sách các bài viết, sau đó tiếp tục crawl và lặp lại cho đến page cuối cùng
def perfom
...
while true
page.search("div.post-feed-item__info").each do |post|
author_name = post.search("a.mr-05").text.strip
title = post.search("h3.word-break").last.text
url = post.search("a.link").last.attributes["href"].value
puts author_name
end
# Tăng số page lên 1
@page_number += 1
# Tìm kiếm xem có còn page tiếp theo không
next_page = page.link_with(href: BASE_PAGINATE_URL + @page_number.to_s)
# trường hợp page không tồn tại hoặc số page > 3 thì mình dừng lại
# bởi vì bài viết trên viblo khá nhiều nên mình chỉ craw 3 page thôi :D
# nếu muốn craw hết thì sửa đoạn dưới thành thế này nhé
# break unless next_page
break if next_page.nil? || @page_number > 3
# click button paginate tiếp theo để sang trang tiếp theo
page = next_page.click
end
...
end
-> Các bạn thử run và xem thành quả nhé, code tham khảo mình push lên ở đây rồi nhé
c) Ghi dữ liệu đọc được vào file CSV
def perfom
page = @agent.get URL
puts "------------------"
puts "Crawling.........."
CSV.open("data.csv", "w", encoding: "UTF-8") do |csv|
csv << HEADER
while true
page.search("div.post-feed-item__info").each do |post|
author_name = post.search("a.mr-05").text.strip
title = post.search("h3.word-break").last.text
url = post.search("a.link").last.attributes["href"].value
csv << [
author_name,
title,
url
]
end
@page_number += 1
next_page = page.link_with(href: BASE_PAGINATE_URL + @page_number.to_s)
break if @page_number > 3
page = next_page.click
end
end
puts "------------------"
puts "Crawling finished."
end
-> Mn mở file data.csv để xem thành quả nhé. Nếu như có dữ liệu thì mn đã thành công rồi đó 

Bài viết hôm nay tạm ngưng ở đây thôi, các bạn có thể phát triển thêm project của mình để phục vụ cho mục đích của riêng mình như tạo thêm con bot cho nó làm việc này, setup cronjob cho nó,....
Source code: HERE
Cảm ơn mn đã đọc bài viết của mình. Có gì trao đổi thì cứ comment bài viết của mình để cùng trao đổi nhé 
Tham khảo
All rights reserved
