Thống kê với Aggregation Query trong Elasticsearch (Phần 1 - Công cụ truy vấn và tổng quát về aggregation query)
Bài đăng này đã không được cập nhật trong 8 năm
Elasticsearch được biết đến như là một distributed search engine phổ biến nhất hiện giờ bởi tính mạnh mẽ, nhanh (near real-time) và được hỗ trợ bởi nhiều ngôn ngữ lập trình khác nhau (hầu hết các ngôn ngữ lập trình phổ biến hiện nay đều có open-source client hỗ trợ elasticsearch). Một trong những tính năng mạnh mẽ của elasticsearch đó là aggregation query giúp cho người phát triển có thể tạo ra những thống kê, kết luận về dữ liệu dựa trên những yêu cầu từ phía người dùng hay khách hàng. Chúng ta hãy cùng tìm hiểu cách viết aggregation query để có được một cái nhìn tổng quát và những thống kê có ý nghĩa về dữ liệu, nhưng trước hết hãy cùng làm quen với một công cụ giúp cải thiện thời gian viết query của chúng ta.
1. Công cụ
Để giao tiếp với REST API của Elasticsearch, ta có thể sử dụng curl command hay sử dụng trình duyệt để viết URI query tới elasticsearch, hoặc sử dụng chính các gem elasticsearch client (như searchkick, elasticsearch, ...) nhưng việc viết query sẽ phức tạp đồng thời kết quả trả về sẽ rất khó để có thể đưa ra hiển thị và quan sát. Cụ thể là đối với curl command query sẽ khó viết hơn trên terminal (viết nhiều dòng thì dễ ấn nhầm enter, nếu gõ one line chắc chắn sẽ có trường hợp thiếu ngoặc,...), hơn nữa kết quả trả về sẽ khá là "đau mắt" (one line) nếu bạn quên truyền thêm param ?pretty vào sau search request (ví dụ như hình minh họa chẳng hạn)

Việc sử dụng client lại phức tạp hơn ở chỗ bạn sẽ phải viết cả một đoạn code để kết nối rồi mới query được, hơn nữa việc query lại được xử lý qua thêm một lớp thông dịch của ruby sẽ khiến thời gian query trở nên không tối ưu khi bạn muốn thử chạy bất kì một query nào. Một giải pháp khác là sử dụng các extension RESTful của chrome như Postman, Restful API client, ... Nhưng để sử dụng được chúng thì việc cài đặt header cho request mỗi lần query cũng làm chúng ta mất một chút thời gian nho nhỏ.
Vậy để tối ưu thời gian viết query mỗi khi bạn muốn thử chạy một vài truy vấn nào đó để sử dụng trong ứng dụng của mình mà không muốn tốn thời gian như các cách nói trên, elastisearch đã có hỗ trợ Console UI, trong Kibana (một plugin nổi tiếng của elasticsearch giúp cho việc phân tích và visualization dữ liệu). Trước kia Console UI chỉ là một extension có tên là Sense của chrome và firefox và có thể cài đặt dễ dàng, nhưng sau này vì một số lý do về an toàn thông tin mà nó được loại bỏ và sau đó được tích hợp thành một plugin trong Kibana. Vì vậy, muốn sử dụng được Console UI, ta phải cài đặt Kibana phiên bản tương thích với phiên bản elasticsearch mà chúng ta đang sử dụng.
1.1. Các bước cài đặt
Bước 1: Cài đặt và khởi động Elasticsearch
Bước 2: Cài đặt Kibana
Bước 3: Cấu hình Kibana truy xuất dữ liệu từ Elasticsearch
- Tại file cấu hình
kibana.ymlcấu hìnhelasticsearch.urlelasticsearch.usernamevàelasticsearch.passwordđể Kibana có thể truy vấn đến dữ liệu, và để xác thực nếu Elasticsearch yêu cầu - Chắc chắn rằng thiết lập
console.enabledlàtrueđể có thể sử dụng Console UI (mặc định làtrue)
1.2. Giao diện Console UI
-
Mặc định Console UI nằm ở http://localhost:5601/app/kibana#/dev_tools/console?_g=()
-
Giao diện của Console UI gồm 2 phần, phần
editor(pane bên trái) để viết query, và phầnresponse(pane bên phải) là phần hiển thị kết quả trả về từ Elasticsearch.
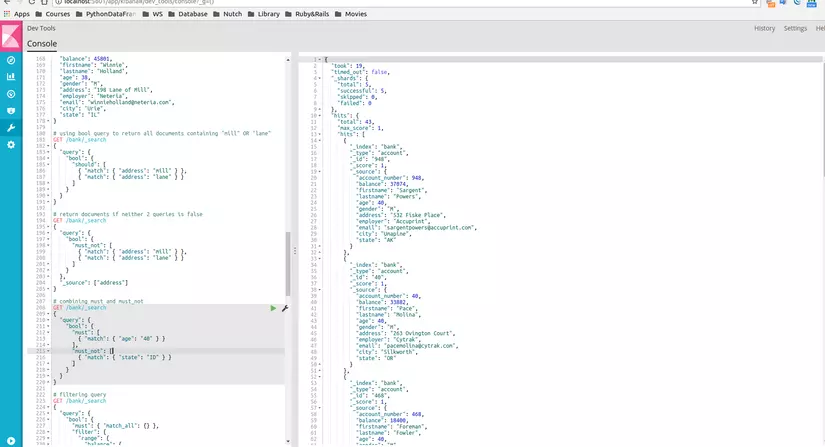
- Có thể viết nhiều query lên nhiều index, hay nhiều document type khác nhau trên editor pane, các query cũng được lưu lại trong tab
Historyđể tiện chỉnh sửa cho lần truy vấn tiếp theo. - Ngoài ra editor pane hỗ trợ chức năng autocomplete, có thể gợi ý cho bạn tên các indices, document type, thậm chí cả các field trong document type, và các thiết lập cho query giúp cho việc viết query trở nên cực kỳ nhanh chóng.
(Nếu bạn là master về Elasticsearch có thể việc hiển thị gợi ý lại là cản trở, có thể tắt nó trong phần Settings của Console UI)
- Console UI còn hỗ trợ thực hiện multi request đến Elasticsearch một lúc, bằng việc bôi đen các truy vấn cần chạy và submit chúng (điều này giúp chúng ta tiện query như trong MySQL workbench vậy)
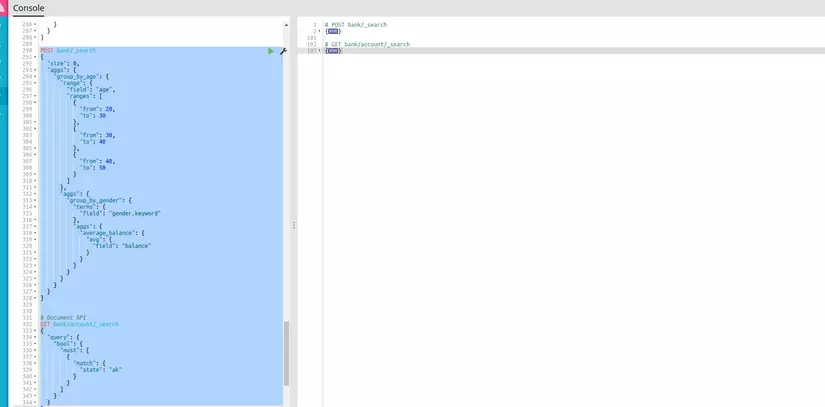
Kết quả trả về của từng query được đánh dấu bởi những dòng chú thích tại response pane.
Ngoài ra, Console UI còn một vài chức năng khác như: copy request thành curl request, hay tự động indent request sau khi viết (thích hợp cho việc auto format lại _bulk request về oneline sau khi đã viết dạng multi line)

2. Tổng quan về Aggregation query
Chuẩn bị: sử dụng sample dataset sau cho những ví dụ trong phần này
Load sample data set bằng request sau:
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/account/_bulk?pretty&refresh" --data-binary "@accounts.json"
Ta đều biết là elasticsearch cung cấp một query DSL interface giúp cho việc search trở nên dễ dàng và nhanh chóng, query cũng rất đơn giản và dễ nhớ. Với search query, chúng ta có thể tìm ra một tập con các documents thỏa mãn điều kiện nào đó ta muốn tìm kiếm. Với aggregation query, chúng ta có được một cái nhìn tổng quát về dữ liệu mà chúng ta đang có, thay vì nhìn vào từng document cụ thể thỏa mãn điều kiện nào đó, chúng ta muốn phân tích theo từng tiêu chí (phục vụ mục đích báo cáo hoặc hiển thị dashboards):
- Có bao nhiêu tài khoản ngân hàng đăng ký ở từng quận tại thành phố Tokyo
- Trong từng quận ta muốn thống kê tài khoản có số dư lớn nhất, nhỏ nhất; trung bình, median của số dư; thống kê top khách hàng mở nhiều tài khoản nhất tại ngân hàng
- ...
Aggregation query của elasticsearch cũng giống như những gì chúng ta làm với group by query trong MySQL nhưng những gì mà MySQL đem lại là không đủ với những thống kê phức tạp.
Aggregation trong Elasticsearch về cơ bản chia làm hai concept chính: Buckets và Metrics (còn 2 loại đó là Matrix và Pipeline sẽ được đề cập đến ở các series nâng cao hơn)
- Buckets: một họ của aggregations query xây dựng lên các buckets, mỗi buckets tương đương với một key và một tiêu chí nào đó. Khi chạy aggregation query, tất cả các tiêu chí của từng buckets được kiểm tra trên toàn bộ các documents, khi document thỏa mãn một điều kiện của một bucket, nó được cân nhắc là thuộc bucket đó. Kết quả của aggregation dạng này là một list các buckets, mỗi bucket chứa tập các documents thuộc về bucket đó. Ví dụ: Thống kê số lượng tài khoản ngân hàng của từng bang trong thành phố với query (chi tiết về cách viết aggregation query sẽ được nói ở phần sau, ở phần này ta chỉ nhìn qua một số chức năng tổng quan của từng loại aggregation query mà thôi)
POST bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
kết quả trả về:
{
"took": 1,
"timed_out": false,
"_shards": {
...
},
"hits": {
...
},
"aggregations": {
"group_by_state": {
"doc_count_error_upper_bound": 20,
"sum_other_doc_count": 770,
"buckets": [
{
"key": "ID",
"doc_count": 27
},
{
"key": "TX",
"doc_count": 27
},
{
"key": "AL",
"doc_count": 25
},
{
"key": "MD",
"doc_count": 25
},
{
"key": "TN",
"doc_count": 23
},
{
"key": "MA",
"doc_count": 21
},
{
"key": "NC",
"doc_count": 21
},
{
"key": "ND",
"doc_count": 21
},
{
"key": "ME",
"doc_count": 20
},
{
"key": "MO",
"doc_count": 20
}
]
}
}
}
- Metrics: aggregation query tính toán các thông số (min, max, count, sum, median,...) của một tập các document thỏa mãn điều kiện search nào đó hoặc trong một bucket nào đó của một aggregation query khác
Ví dụ: Với thống kê bucket trên, ta có thể tính tổng số dư của tất cả các tài khoản thuộc từng bang với query
POST bank/account/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"sum_": {
"sum": {
"field": "balance"
}
}
}
}
}
}
kết quả trả về:
{
...,
"aggregations": {
"group_by_state": {
"doc_count_error_upper_bound": 20,
"sum_other_doc_count": 770,
"buckets": [
{
"key": "ID",
"doc_count": 27,
"sum_balance": {
"value": 657957
}
},
{
"key": "TX",
"doc_count": 27,
"sum_balance": {
"value": 741499
}
},
{
"key": "AL",
"doc_count": 25,
"sum_balance": {
"value": 643489
}
},
{
"key": "MD",
"doc_count": 25,
"sum_balance": {
"value": 624088
}
},
{
"key": "TN",
"doc_count": 23,
"sum_balance": {
"value": 685326
}
},
{
"key": "MA",
"doc_count": 21,
"sum_balance": {
"value": 624256
}
},
{
"key": "NC",
"doc_count": 21,
"sum_balance": {
"value": 562494
}
},
{
"key": "ND",
"doc_count": 21,
"sum_balance": {
"value": 552370
}
},
{
"key": "ME",
"doc_count": 20,
"sum_balance": {
"value": 391501
}
},
{
"key": "MO",
"doc_count": 20,
"sum_balance": {
"value": 483036
}
}
]
}
}
}
Vậy qua hai ví dụ trên ta có thể thấy được tổng quát cấu trúc của một aggregation query là như sau:
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
Trong đó:
aggregation_name: Tên tùy ý của aggregation query do ta tự định nghĩaaggregation_type: loại aggregation queryaggregation_body: định nghĩa tên trường, order, size,...- Ngoài ra có thể định nghĩa sub_aggregation như ví dụ cuối cùng
Như vậy, ta đã tìm hiểu về được 2 loại hình aggregations query trong elasticsearch, cấu trúc của một aggregation query, đồng thời biết được một plugin trợ giúp rất nhiều cho việc viết query. Ở những phần tiếp theo chúng ta sẽ tiếp tục đi sâu vào tìm hiểu từng loại aggregation query để biết được sức mạnh thống kê của Elasticsearch.
Tham khảo
All rights reserved
