The Multimedia Warehouse - Định nghĩa và cấu trúc
Bài đăng này đã không được cập nhật trong 6 năm
The Multimedia Warehouse - Định nghĩa và cấu trúc
Định nghĩa
Kho đa phương tiệnđược định nghĩa dựa trên các khái niệm giống như kho dữ liệu nhưng có chút khác biệt, vì bản chất của các đối tượng kỹ thuật số được lưu trữ trong đó. Hầu hết các kho đa phương tiện sử dụng để chuyển đổi dữ liệu, làm sạch và lập chỉ mục để truy vấn và lập báo cáo hiệu quả hơn. Ngoài ra, chúng có thể biến đổi hình ảnh, tóm tắt, kết hợp và tái cấu trúc lại dữ liệu.
The data warehouse - Kho dữ liệu
Ý tưởng về kho dữ liệu đã xuất hiện từ lâu và các nhà cung cấp phần mềm chuyên dụng đã hoàn toàn để giải quyết được các nhu cầu của nó. Kho dữ liệu phát triển từ một số hướng khác nhau cùng một lúc. Các học giả sau đó đã xây dựng các quy tắc chính thức hơn định nghĩa lại một kho dữ liệu thực sự là gì.
Đối với một số người, kho dữ liệu để giải quyết vấn đề về hiệu năng của các truy vấn ad hoc (em không biết giải nghĩa như nào về ad hoc query ra tiếng việt nên các bạn google nhé) có thể ảnh hưởng tới hiệu suất của cơ sở dữ liệu giao dịch. Ví dụ một người dùng đang chạy một truy vấn không tốt, nó có thể tắt luôn cơ sở dữ liệu của ứng dụng. Nhưng nhu cầu của người dùng cần chạy các truy vấn này, vậy có nghĩa là ta cần chuyển chúng sang một bản sao của cơ sở dữ liệu. Từ đó nảy sinh nhu cầu thực hiện Extract (Trích xuất), Transform (Chuyển đổi) và Load (ETL) đối với bản sao đó. Các tính năng khác nhau đã phát triển từ điều này để cho phép di chuyển dữ liệu hiệu quả từ cơ sở dữ liệu chính sang kho dữ liệu. Điều này đảm bảo rằng kho dữ liệu có thông tin luôn được cập nhật.
Các nhu cầu khác phát sinh, bao gồm việc các nhà quản lý để muốn truy vấn nhiều cơ sở dữ liệu khác nhau. Từ yêu cầu cung cấp thông tin, ta có khái niệm phân tích kinh doanh gọi là xử lý phân tích trực tuyến (online analytical processing - OLAP). Sự ra đời của OLAP cũng mở ra ý tưởng rằng bản thân dữ liệu không nhất thiết phải luôn được cập nhật và là bản sao chính xác nơi nó bắt nguồn. OLAP đã tạo ra dữ liệu tóm tắt tập trung vào các dữ liệu khác nhau (ví dụ: vị trí địa lý, các bộ phận và thời gian), rất hữu ích để thực hiện các truy vấn tổng hợp phức tạp. Khi các truy vấn tóm tắt dựa trên thời gian được thực hiện, không cần phải có thông tin cập nhật hoàn toàn, đặc biệt là khi các truy vấn lịch sử đã được thực hiện. Khái niệm này bị bỏ qua bởi hầu hết các quản trị viên cơ sở dữ liệu và các học giả quan hệ, những người đã được đào tạo và tin rằng một cơ sở dữ liệu thực sự luôn nhất quán. Kho dữ liệu đã bỏ qua khái niệm này và thay đổi một số quy tắc. Đối với OLTP, đúng là dữ liệu phải nhất quán, nhưng đối với kho dữ liệu, có các quy tắc mới và tính nhất quán của dữ liệu không cao. Đối với một kho đa phương tiện, khái niệm tương tự này cũng đúng như vậy. Một kho đa phương tiện hoạt động theo một bộ quy tắc khác.
Data consistency - Tính nhất quán dữ liệu
Tính nhất quán của dữ liệu tóm gọn lại là tính hợp lệ, chính xác, khả năng sử dụng và tính toàn vẹn của dữ liệu liên quan giữa các ứng dụng và trên toàn doanh nghiệp CNTT. Tính nhất quán dữ liệu là một chủ đề quan trọng và là trung tâm của cơ sở dữ liệu quan hệ. Đối với người dùng, tính nhất quán có nghĩa là khi họ xem dữ liệu, dữ liệu phải chính xác và đúng loại. Nó phải không được thay đổi trong ổ đĩa hoặc bị hỏng. Đây là một khái niệm cốt lõi.
Tính nhất quán dữ liệu được nhấn mạnh rất nhiều trong mô hình quan hệ và các khóa chính, khóa ngoại, ràng buộc đã được dùng để thực thi tính nhất quán. Tính nhất quán trong mô hình quan hệ là thời gian thực ở cấp độ giao dịch. Vì mô hình dựa trên toán học, nó không thể bị lỗi. Nó được chứng minh và thử nghiệm.
Có một sự đánh đổi để thực thi mức độ nhất quán này đòi hỏi nhiều tài nguyên tính toán và mạng tốc độ cao. Bản chất thời gian thực của tính nhất quán bắt đầu sụp đổ trong các hệ thống phân tán. Nếu một ứng dụng được phân phối trên nhiều cơ sở dữ liệu tại các trang web khác nhau, có thể khá khó khăn để giữ chúng đồng bộ và nhất quán trong thời gian thực. Oracle ban đầu đã cố gắng giải quyết vấn đề này bằng cách cung cấp bản sao đồng bộ (thời gian thực) và không đồng bộ (trì hoãn). Với việc đưa các bản sao thông qua các bản ghi log để làm lại (một tính năng sao chép phổ biến của hầu hết các cơ sở dữ liệu), sao chép không đồng bộ đã trở thành tiêu chuẩn mới. Khái niệm về độ trễ tồn tại giữa khi dữ liệu được thay đổi và khi thay đổi đó được phản ánh tại các nơi khác, phủ nhận yêu cầu về tính nhất quán theo thời gian thực và đưa ra ý tưởng cuối cùng về tính nhất quán.
Với sức mạnh của các hệ thống máy tính ngày nay, nhưng tính nhất quán của ứng dụng theo thời gian thực vẫn có những hạn chế về khả năng mở rộng. Cố gắng thực thi các khóa ngoại và vô số các ràng buộc khác có thể tốn nhiều tài nguyên, vì kích thước của cơ sở dữ liệu, số lượng người dùng tăng lên. Với sự gia tăng phổ biến của NoQuery, cũng xuất hiện khái niệm về tính nhất quán cuối cùng. Nó không xung đột với khái niệm về tính nhất quán dữ liệu ở cấp độ giao dịch. Nó nói rằng nhu cầu dữ liệu luôn luôn nhất quán trong thời gian thực không phải là một yêu cầu bắt buộc trong mọi trường hợp. Đối với một hệ thống tài chính, rất có thể đây là một yêu cầu bắt buộc để luôn nhất quán, nhưng một ứng dụng mạng xã hội không phải lúc nào cũng đòi hỏi dữ liệu phải nhất quán ngay lập tức. Bằng cách giới thiệu tính nhất quán này, một số vấn đề về khả năng mở rộng và hiệu suất gặp phải trước đây đã được khắc phục - cho phép các ứng dụng, như Facebook và Google, mở rộng tới hàng trăm triệu người dùng.
Một kho dữ liệu có thể sử dụng tính nhất quán cuối cùng để đạt được một số yêu cầu về hiệu suất của nó. Cấu trúc khung nhìn cụ thể hóa có thể được sử dụng trong cơ sở dữ liệu là một ví dụ như vậy. Một kho dữ liệu có các yêu cầu khác nhau và đưa ra một khái niệm mới, mà tính nhất quán dữ liệu truyền thống không giải quyết được đầy đủ.
Logical Data Consistency
Tính nhất quán hiện được chia thành ba phần:
- Point-in-time: Loại này bao gồm đĩa và phần mềm. Nó kiểm tra xem cơ sở dữ liệu ghi dữ liệu vào đĩa chính xác.
- Transactional: Loại này đảm bảo rằng một tập hợp các mục dữ liệu (đơn vị công việc logic) phù hợp. Trong cơ sở dữ liệu, điều này đảm bảo liệu nó có nhất quán khi xảy ra lỗi hay không.
- Application: Loại này đảm bảo dữ liệu trên nhiều giao dịch có nhất quán không.
Mỗi phần mở rộng đều dựa trên các khả năng của phần trước để nâng cao nó.
Điều bị bỏ lỡ là tính chính xác và nhất quán của dữ liệu. Trong tính nhất quán giao dịch, mô hình không quan tâm nếu một trường chứa số nguyên có giá trị 10 hoặc 20, cung cấp tất cả các cột khác tham chiếu đến nó (khóa chính, khóa ngoại).
Tính nhất quán dữ liệu logic tập trung vào chính giá trị dữ liệu và độ chính xác của chúng. Nó xung đột với tính nhất quán cuối cùng. Lấy ví dụ với một trường tên, thường chứa tên và họ, nhưng khi một giá trị được nhập vào, nó có đúng về mặt logic không?
Điều gì sẽ xảy ra nếu thay vì John Smyth, John Smith được gõ. Nó có vẻ không chính xác? Câu trả lời ngay lập tức là không; ngoại trừ việc mô hình nhất quán không thể biết điều này đúng hay sai. Ngay cả khi tên John Smyth được nhập, nó vẫn có thể không chính xác, vì tên đầy đủ của người đó đã không được nhập. Thay vào đó, tên John Paul Smyth đã được nhập? Tại điểm nào khi nhập tên là chính xác? Điều tương tự dùng cho địa chỉ hoặc chi tiết liên lạc. Nếu người đó thay đổi tên hoặc số điện thoại thì sao? Trong trường hợp này, giá trị được nhập có thể nhìn rất đúng nhưng trên thực tế bây giờ nó không chính xác.
Tính nhất quán thực sự ngụ ý là tính chính xác trong dữ liệu, nghĩa là có thể tin tưởng vào dữ liệu và tin tưởng vào kết quả khi được yêu cầu. Nó đã được chứng minh rằng chúng ta không thể tin tưởng vào dữ liệu, vì có một sự mờ nhạt đối với nó. Ví dụ với ngày sinh đã nhập, chúng ta có thể tin tưởng vào năm, tháng và ngày, nhưng không phải là giờ, phút và giây.
Nếu một người nhập địa chỉ email, địa chỉ đó có hợp lệ không? Có phải đó là địa chỉ email thuộc về người đó và nó sẽ chỉ thuộc về người đó? Một số ứng dụng có thể đạt được mức độ thoải mái cao trong việc xác định rằng e-mail phù hợp với người đó, nhưng để duy trì điều này theo thời gian có thể khó khăn. Có một mức độ chính xác và tin tưởng để có được ở đây.
Hầu hết thời gian, các vấn đề mờ này với các mục dữ liệu được xử lý, vì chúng quá khó hiểu và kiểm soát hoặc vượt ra ngoài ranh giới của ứng dụng (dữ liệu mờ là dữ liệu có phạm vi giá trị và logic của nó đề cập đến các thao tác toán học của dữ liệu không rõ). Chúng ta học cách chấp nhận sự không nhất quán logic trong dữ liệu. Bây giờ nó là quá nhiều đến nỗi theo bản năng bị bỏ qua trong rất nhiều trường hợp. Tuy nhiên, hầu hết các mục dữ liệu có một mức độ mờ đối với chúng. Bất kỳ mục dữ liệu nào được xác định là số nguyên chỉ ra rằng độ chính xác cần thiết không giống với số thực. Ngày, dấu thời gian, thậm chí tọa độ không gian có độ chính xác, trong đó chúng ta chấp nhận một mức độ chính xác nhất định, nhưng ngoại trừ việc nó không phải hoàn toàn chính xác.
Hệ thống quan hệ có thể có một mô hình toán học đằng sau nó, đảm bảo tính thống nhất của dữ liệu trong các giao dịch, nhưng nó không thể kiểm soát liệu các giá trị dữ liệu có hoàn toàn chính xác hay không. Về mặt toán học, nó không thể thực thi rằng tên được nhập là hợp lệ 100% hoặc phù hợp với danh tính thực sự của người đó. Đối với một cái tên, rất khó để đảm bảo rằng nó đã được viết đúng chính tả.
Khi chúng ta lấy dữ liệu trong thế giới thực, nó được dịch và xử lý để phù hợp với hệ thống máy tính. Lỗi rõ ràng có thể được sửa chữa (nếu nhập ngày không hợp lệ), nhưng chúng ta sẽ không bao giờ có được độ chính xác đầy đủ và độ chính xác đầy đủ trên tất cả dữ liệu được nhập. Tất cả những gì có thể được thực hiện là để đạt được một mức độ tin cậy với những gì được nhập vào.
Trong một kho đa phương tiện, khái niệm cố gắng đạt được tính nhất quán dữ liệu logic không có, vì rõ ràng là phần lớn các đối tượng kỹ thuật số là dữ liệu mờ. Mục tiêu là đạt được mức độ chính xác dựa trên từng mục dữ liệu và sau đó, hiểu được ý nghĩa của độ chính xác đó.
Trong kho sử dụng OLAP, khi các truy vấn thống kê được chạy trên các mục lớn, các vấn đề nhỏ về độ chính xác của dữ liệu có thể được đưa ra (tính trung bình). Trong các trường hợp khác, dữ liệu không phù hợp với độ lệch chuẩn có thể được loại trừ là bất thường và bị bỏ qua. Những người làm việc nhiều với số liệu thống kê sẽ biết câu ngạn ngữ, "Lies, damned lies, and statistics". Bằng cách thao tác cơ sở dữ liệu, đặc biệt là khi bạn biết độ chính xác của dữ liệu không cao, có thể cho phép một số người dùng điều chỉnh kết quả của các truy vấn để phù hợp hơn với mong đợi hoặc mục tiêu của họ. Các kết quả có thể được làm mờ.
Kho đa phương tiện đưa vấn đề nhất quán dữ liệu logic hơn nữa khi phân loại đối tượng kỹ thuật số. Có phải đó là John Smith trong bức ảnh? Có phải đó là một con chim hót trong bản nhạc? Đó có phải là hình ảnh của một chiếc ghế? Có phải người này trong video? Đây có phải là ảnh kỹ thuật số giống hệt với ảnh này? Tài liệu này có phải là ảnh không? Cơ sở dữ liệu đa phương tiện sử dụng rộng rãi và dữ liệu không bao giờ chính xác. Nó chỉ có một mức độ chính xác là khiêm tốn, có thể thay đổi dựa trên hoàn cảnh hoặc thậm chí cách truy vấn được thực hiện.
Những người đã sử dụng kho dữ liệu truyền thống, đặc biệt là dựa trên các khái niệm quan hệ, có thể gặp nhiều rắc rối khi xử lý sự mờ nhạt của đa phương tiện và thực tế là nó không chính xác. Điều này có thể dẫn đến những nỗ lực gần như hài hước được thực hiện bởi mọi người để phân loại nó: Tệp PDF này là một tài liệu nếu nó chứa nhiều hơn x số từ, nhưng nó là một bức ảnh nếu nó chứa một hình ảnh kỹ thuật số và ít hơn số lượng y từ.
Trong hầu hết các trường hợp, thật không hợp lý khi thử kết hợp thế giới quan hệ với thế giới đa phương tiện. Chúng rất khác nhau. Người ta đã chứng minh rằng lý thuyết xác suất là một tập hợp con của logic mờ, có nghĩa là việc xử lý độ mờ của dữ liệu là âm thanh và là sự mở rộng tự nhiên của quản lý dữ liệu.
Khoa học máy tính là một môi trường thay đổi liên tục. Công nghệ mới và những tiến bộ tạo ra những suy nghĩ mới về việc sử dụng giao diện, hiệu suất và quản lý dữ liệu ít nhất hai năm một lần. Một cơ sở dữ liệu mới được phát hành giới thiệu các tính năng mới và thay thế các khái niệm cũ. Các quản trị viên cơ sở dữ liệu phải học lại các khái niệm và ý tưởng mới ít nhất hai đến ba năm một lần. Trong công nghệ, bạn không thể bảo thủ và mơ ước được ở trong vùng thoải mái của mình. Tuy nhiên, nói về sự mờ nhạt của đa phương tiện, các cách nó tác động đến cơ sở dữ liệu và các cách để làm việc với nó, liên tục bị bỏ qua. Trớ trêu thay, chủ nghĩa bảo thủ đó được tìm thấy trong các nhà cung cấp cơ sở dữ liệu bao gồm cả Oracle.
Dilapidated warehouse
Khi khái niệm kho dữ liệu phát triển, ý tưởng về việc ném bất kỳ dữ liệu nào vào kho lưu trữ trung tâm đã xuất hiện, đặc biệt, nếu nó có nguồn gốc từ các hệ thống cũ, nơi không hiểu nhiều về cấu trúc ban đầu của nó. Chắc chắn sẽ dễ dàng hơn và rẻ hơn khi chỉ cần lấy dữ liệu, sao chép nó vào một kho trung tâm và nói với người dùng "đây rồi, hãy làm gì với nó như bạn muốn". Thật không may. Người ta đã sớm biết rằng một kho dữ liệu chỉ thành công nếu nó được điều khiển bởi chính người dùng. Họ có những câu hỏi và câu hỏi cần được trả lời. Kho dữ liệu có một yêu cầu và chức năng kinh doanh chính. Nếu trọng tâm đó bị mất, kho dữ liệu sẽ trở thành Kho đổ nát. Một số kho dữ liệu đã phải chịu số phận này.
Nhưng ngay cả trong trường hợp này, tất cả vẫn không bị mất, vì từ đó xuất hiện khái niệm khai thác dữ liệu, trong đó các mẫu trong dữ liệu và giữa các mục dữ liệu khác nhau có thể được tính toán tự động. Có một kho dữ liệu, không có yêu cầu kinh doanh cốt lõi không phải là bản án tử hình. Vẫn có thể nhận được thông tin hữu ích từ nó.
Kho dữ liệu có nhiều thách thức để giải quyết. Những điều quan trọng nhất là bảo mật, hiệu suất và ngăn chặn quá tải thông tin.
Security
Khi nhiều người dùng truy cập vào kho dữ liệu, điều quan trọng là phải đảm bảo rằng chỉ những người dùng được ủy quyền mới có thể truy cập dữ liệu mà họ được phép. Đối với kho bảo mật, thông tin có thể được đánh dấu bằng các mức truy cập bảo mật khác nhau. Điều này có thể yêu cầu bảo mật được thực hiện ở cấp hàng dữ liệu riêng lẻ.
Thật không may, hạn chế quyền truy cập vào dữ liệu có thể khiến kho dữ liệu trở nên không sử dụng được. Trong cơ sở dữ liệu điều tra dân số, người dùng thực hiện truy vấn có thể nhận thông tin tóm tắt về các khu vực (ví dụ: vùng ngoại ô) nhưng không được phép truy cập dữ liệu đến từ các hộ gia đình vì yêu cầu riêng tư hợp pháp. Hạn chế quyền truy cập vào các bản ghi này có nghĩa là các truy vấn tóm tắt không thể được thực hiện. Bảo mật cần được cấu hình để giải quyết vấn đề nan giải này.
Một giải pháp để giải quyết vấn đề bảo mật là sử dụng khái niệm data mart. Data mart là lớp truy cập của môi trường kho dữ liệu được sử dụng để lấy dữ liệu ra cho người dùng. Data mart là một tập hợp con của kho dữ liệu, thường được định hướng cho một nhóm hoặc nhóm kinh doanh cụ thể. Truy cập http://en.wikipedia.org/wiki/Data_mart để biết thêm thông tin về data mart.
Việc sử dụng data mart cho phép dữ liệu trong kho được giới hạn chặt chẽ đối với một nhóm người dùng được xác định rõ.
Vì quyền truy cập vào thông tin tóm tắt có thể trở nên quan trọng và mang tính chiến lược đối với doanh nghiệp, đặc biệt là nếu các quyết định kinh doanh dựa trên nó, yêu cầu có thể kiểm toán những gì được yêu cầu và những gì người dùng thực sự xem cũng trở thành một thành phần chính.
Performance
Truy vấn kho dữ liệu có thể rất đói tốn nguyên. Các hệ thống cơ sở dữ liệu đã liên tục phát triển theo thời gian để giải quyết các vấn đề về hiệu suất. Một số giải pháp hiệu suất bao gồm song song hóa, các khung nhìn cụ thể hóa, bộ nhớ đệm thông minh, phân vùng và phần cứng thông minh tốc độ cao (ví dụ, Oracle Exadata). Khi số lượng dữ liệu tăng lên, sự phức tạp của các truy vấn người dùng có thể thực hiện tăng theo. Điều này có nghĩa là các yêu cầu về hiệu suất của kho dữ liệu luôn thay đổi.
Một data mart cũng có thể hữu ích cho hiệu suất, vì nó cho phép kho dữ liệu phân vùng và mỗi data mart có thể được điều chỉnh theo yêu cầu của nhóm người dùng sử dụng nó.
Information overload
Khi ngày càng có nhiều dữ liệu được chuyển vào kho dữ liệu, có thể rất khó để tìm ra loại truy vấn nào có thể chạy và cách tốt nhất để chạy chúng. Để giải quyết đống dữ liệu này, từ điển dữ liệu được tạo ra; cung cấp bản đồ đường đi cho người dùng để cho phép họ truy vấn thông minh đối với dữ liệu. Ngoài ra, các bảng dữ liệu cho phép các mục dữ liệu quan tâm được cung cấp cho người dùng, cũng như ẩn các cấu trúc mà họ không cần phải xem hoặc truy cập.
3
Các loại kho đa phương tiện
Các thông tin sau đây mô tả một số loại kho đa phương tiện. Danh sách này không bao gồm tất cả các biến thể có thể và sẽ thay đổi khi công nghệ thay đổi.
Traditional
Kho đa phương tiện truyền thống dựa trên các khái niệm tương tự của kho dữ liệu. Mục tiêu là có thể cung cấp một kho lưu trữ các đối tượng và dữ liệu kỹ thuật số đến từ các nguồn khác nhau. Dữ liệu và các đối tượng tự trải qua một quá trình ETL. Quá trình này sẽ bao gồm nhu cầu thiết lập mối quan hệ hợp lệ giữa dữ liệu và các đối tượng kỹ thuật số.
Trong kho dữ liệu, dữ liệu có thể được tóm tắt thành một lớp, với nhiều lớp cha. Ví dụ tiêu chuẩn đang tạo ra một cấu trúc tóm tắt dữ liệu lớp của dữ liệu bán hàng, dựa trên các khu vực trong thành phố, tiểu bang, khu vực tiểu bang và quốc gia. Vùng chỉ là một chiều của nhiều dữ liệu trong đó dữ liệu có thể được nhóm lại và tóm tắt. Một khía cạnh khác là thời gian. Ảnh kỹ thuật số có thể được kết hợp với nhau thành một đoạn phim, đoạn trích có thể được trích xuất từ video, các trang chính trong các tài liệu khác nhau có thể được trích xuất, sau đó kết hợp. Oracle Text có thể sử dụng khả năng chính của nó để tự động tóm tắt một tài liệu hoặc trích xuất các chủ đề chính về tài liệu.
Image bank
Trong kho ngân hàng hình ảnh, mục tiêu là cung cấp một kho lưu trữ trung tâm, mà tất cả các đối tượng và ứng dụng kỹ thuật số có thể truy cập. Siêu dữ liệu được lưu trữ trong các ứng dụng bên ngoài kho và các ứng dụng này chỉ tham chiếu các đối tượng kỹ thuật số trong kho. Siêu dữ liệu duy nhất được lưu trữ với các đối tượng kỹ thuật số là thông tin thuộc tính vật lý về đối tượng kỹ thuật số. Đối với một bức ảnh, đây sẽ là siêu dữ liệu EXIF.
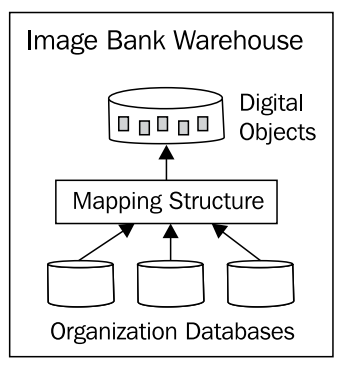
Một mục tiêu quan trọng của kho ngân hàng hình ảnh là lưu trữ đối tượng kỹ thuật số một lần và có một kho lưu trữ có thể được điều chỉnh theo các yêu cầu đặc biệt của đa phương tiện. Trong môi trường này, vẫn hợp lý để tạo kho dữ liệu, với các giá trị trong kho dữ liệu tham chiếu kho ngân hàng hình ảnh. Ưu điểm là kho dữ liệu truyền thống không phải lo lắng về việc quản lý và các trạng thái của việc xử lý đa phương tiện. Họ không phải lo lắng về yêu cầu lưu trữ hoặc cố gắng xử lý và phát hiện các đối tượng kỹ thuật số trùng lặp có thể xảy ra, khi các ứng dụng khác nhau di chuyển một phần dữ liệu của họ vào kho dữ liệu.
Data mart
Trong một Data mart đa phương tiện, mục tiêu là lấy một tập hợp con các đối tượng kỹ thuật số có kiểm soát, có thể bắt nguồn từ một kho đa phương tiện, có thể biến đổi chúng, và sau đó làm cho chúng có sẵn để sử dụng. Một phương pháp phổ biến là làm cho các đối tượng kỹ thuật số này có sẵn công khai, nơi chúng có thể được thao tác, sử dụng và thậm chí là nâng cao. Phương pháp Crowdsourcing có thể được áp dụng cho những hình ảnh này với kết quả được làm sạch và đưa trở lại vào kho đa phương tiện mẹ.
Các khái niệm về một data mart đa phương tiện rất giống với data mart truyền thống, nơi sự tồn tại của nó được tạo ra để giải quyết các vấn đề về bảo mật, hiệu suất hoặc quá tải thông tin.
Public
Trong một kho Public, mục tiêu là lấy các đối tượng kỹ thuật số từ một hoặc nhiều hệ thống nội bộ và đặt chúng vào cơ sở dữ liệu, có thể được truy cập public. Việc sử dụng dịch vụ cộng đồng (được đề cập sau) cho phép công chúng nói chung đính kèm siêu dữ liệu vào hình ảnh. Khi các đối tượng kỹ thuật số được di chuyển đến kho, chúng có thể được chuyển đổi thành các đối tượng có kích thước nhỏ hơn. Sự chuyển đổi này làm mất thông tin trong ảnh nhưng cung cấp chiều rộng, chiều cao và chất lượng phù hợp mang lại giao diện thân thiện và thẩm mỹ hơn.
eSales
Trong kho eSales, mục tiêu chính là cho phép một hình thức bán hàng thương mại điện tử của các đối tượng kỹ thuật số hoặc những gì các đối tượng kỹ thuật số đại diện.
Đối với kho đa phương tiện này, các đối tượng kỹ thuật số được thu thập từ một hoặc nhiều hệ thống nội bộ. Việc sử dụng siêu dữ liệu là chìa khóa để thúc đẩy cách tìm thấy hình ảnh. Điều này có nghĩa là siêu dữ liệu xung quanh hình ảnh phải được chuyển đổi, làm sạch và phù hợp với người tiêu dùng. Siêu dữ liệu không phù hợp, cần được loại bỏ.
Intelligence (security/defence)
Một hình thức kho đa phương tiện rất mạnh được sử dụng để thu thập thông tin thông minh. Các cơ quan chính phủ, tổ chức quốc phòng, cơ quan cảnh sát và các công ty bảo mật có thể sử dụng kho đa phương tiện.
Chính trị trong một tiểu bang hoặc quốc gia có thể khuyến khích phát triển và sử dụng kho đa phương tiện. Các cơ quan cảnh sát ở các tiểu bang khác nhau trong một quốc gia có tiếng là không tin tưởng người kia. Điều này có thể xuất phát từ nhận thức, nhân cách hoặc các thủ tục bảo mật mâu thuẫn. Kết quả là một sự do dự để chia sẻ thông tin trong việc giải quyết một trường hợp. Chính phủ sau đó tạo ra các cơ quan mới với các chỉ thị mới để cố gắng giải quyết tình trạng bế tắc này. Họ thu thập thông tin, biến đổi nó và tạo ra một cơ sở dữ liệu thông minh. Trong một số trường hợp, họ có thể tạo ra một siêu dữ liệu tập trung vào một lĩnh vực tội phạm đặc biệt quan tâm như ma túy, tội phạm tình dục và tội phạm có tổ chức.
Structures - Cấu trúc
Một kho dữ liệu truyền thống thường sẽ không chứa các cấu trúc bên trong nó. Dữ liệu sẽ được lưu trữ trong các bảng và nối lại với nhau và truy vấn theo yêu cầu. Bảng tóm tắt và thứ nguyên cũng được xây dựng để cải thiện hiệu suất và cung cấp chế độ xem của dữ liệu quan hệ.
Với một kho đa phương tiện, trọng tâm là khác nhau. Mỗi hình ảnh kỹ thuật số được xem như một đối tượng với siêu dữ liệu liên quan của nó mô tả đối tượng đó. Các đối tượng vẫn được truy vấn theo kiểu ad hoc, và các bảng tóm tắt và chiều vẫn được xây dựng, nhưng các đối tượng được đưa vào các cấu trúc để giúp quản lý và kiểm soát chúng. Đối với người dùng truy vấn kho, các cấu trúc này có thể bị ẩn hoặc chúng có thể được sử dụng để thêm thông tin hoặc kiểm soát cho các truy vấn được thực hiện.
Dưới đây mô tả một số cấu trúc có thể được triển khai vào một kho đa phương tiện. Việc các cấu trúc này có thực sự được sử dụng hay không phụ thuộc vào loại đối tượng được lưu trữ và mục đích của kho đa phương tiện.
Collections
Một bộ sưu tập là một nhóm các đối tượng kỹ thuật số. Một đối tượng thường thuộc về một bộ sưu tập nhưng có thể ở trong nhiều bộ sưu tập khác. Các thuộc tính có thể được gán cho một bộ sưu tập, bao gồm bảo mật, siêu dữ liệu và cấu trúc phân loại.
Một bảo tàng sẽ có nhiều bộ sưu tập. Mỗi bộ sưu tập có thể tương đương với một phần vật lý trong tòa nhà (các vật thể ở cánh phía đông hoặc tòa bên tay), một khoảng thời gian (nghệ thuật thế kỷ 16) hoặc các vật thể tương tự về loại (gốm, tranh, tấm thảm).
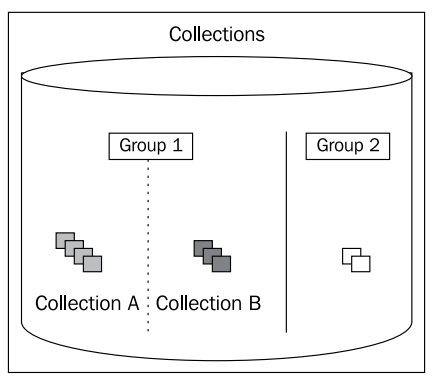
Một bộ phận chính phủ có thể đánh đồng mỗi bộ sưu tập với một bộ.
Một phòng thí nghiệm ảnh có thể đánh đồng mỗi bộ sưu tập với một buổi chụp hình (đám cưới Jones, buổi chụp hình của sinh viên đại học năm 2012, cuộc đua xe mô tô).
Trong hầu hết các trường hợp, một bộ sưu tập có chủ sở hữu là người quản lý bộ đối tượng. Việc nhóm các đối tượng kỹ thuật số lại với nhau cho phép các hành động được thực hiện trên toàn bộ bộ sưu tập. Mỗi đối tượng kỹ thuật số có thể có bộ bảo mật hoặc siêu dữ liệu của nó được cập nhật.
Một bộ sưu tập có thể được gán một tên, cho phép dễ dàng gọi nó.
Groups
Một nhóm là một tập hợp các bộ sưu tập. Các nhóm có thể được lồng và chứa các nhóm khác.
Nếu một tổ chức chính phủ thiết lập mỗi phần để có bộ sưu tập riêng, thì nó có thể nhóm các phần này thành một chi nhánh và mỗi chi nhánh thành một bộ phận.
Một phòng thí nghiệm ảnh có thể nhóm nhiều bộ sưu tập (trong đó mỗi bộ là một bộ ảnh) vào một nhiếp ảnh gia, trong đó nhiếp ảnh gia đó sở hữu tất cả các đối tượng kỹ thuật số.
Một bảo tàng có thể tạo một nhóm cho các đối tượng kỹ thuật số công cộng, trong đó tất cả các nhóm khác, được đánh dấu là riêng tư, đóng góp hình ảnh công khai của họ cho nhóm.
Giống như các bộ sưu tập, có các nhóm giúp phân loại các đối tượng kỹ thuật số dễ dàng hơn và hoạt động trên chúng rất lớn. Thuộc tính bảo mật có thể được áp dụng cho toàn bộ nhóm. Một nhóm có thể được thực hiện ngoại tuyến.

Categories
Trong một bộ sưu tập, các đối tượng kỹ thuật số có thể được lưu trữ trong một cấu trúc phân cấp được gọi là một danh mục. Mục đích của danh mục là cho phép các đối tượng kỹ thuật số này được phân loại và cung cấp một phương pháp thay thế để tìm và xem các đối tượng kỹ thuật số.
Một đối tượng kỹ thuật số có thể thuộc nhiều mục. Một danh mục có thể được lồng nhau. Mặc dù một cấu trúc danh mục thường được phân cấp, nhưng không có yêu cầu nào để tuân thủ điều này.
Không có giới hạn đối với loại danh mục có thể được tạo, hầu như là bằng cách sử dụng siêu dữ liệu hoặc thuộc tính vật lý của đối tượng kỹ thuật số.
Lightbox
Một hộp đèn có thể được mô tả như một khu vực chơi hoặc khu vực giữ hình ảnh. Hộp đèn có thể là riêng tư hoặc chia sẻ với người khác. Có cấu trúc gần giống với một danh mục (và thậm chí có thể được gọi là một loại danh mục ảo), một hộp đèn hơi khác nhau; trong đó, nó được tạo bởi người dùng và hình ảnh được đưa vào bằng tay. Khái niệm này cũng tương tự như một giỏ mua hàng. Một giỏ mua hàng chủ yếu là riêng tư và phiên cụ thể. Một hộp đèn có thể chỉ dành cho một phiên hoặc được giữ vĩnh viễn. Một số đặc điểm độc đáo khác của hộp đèn bao gồm:
- Một nội dung hộp đèn có thể được đặt bằng tay. Tùy thuộc vào giao diện, nội dung hộp đèn có thể được sắp xếp theo ba chiều trở lên (một chiều bổ sung là thời gian).
- Một hộp đèn có thể được chia sẻ với người khác, ngay cả khi những người dùng khác không có quyền truy cập vào hình ảnh. Quyền được thừa kế thông qua hộp đèn. Tất nhiên, đây là một tính năng có thể không phù hợp với một số kho đa phương tiện an toàn.
- Các hành động có thể được thực hiện trên một hộp đèn. Nội dung của nó có thể được in hoặc gửi qua thư điện tử cho một người. Một yêu cầu có thể được đưa vào để chuyển đổi, chuyển đổi hoặc sửa chữa nội dung của hộp đèn. Ngoài ra, chỉnh sửa hàng loạt siêu dữ liệu có thể được thực hiện đối với tất cả các hình ảnh trong hộp đèn.
- Hộp đèn có thể được hợp nhất hoặc thiết lập các hoạt động được thực hiện trên chúng. Tìm giao điểm của hai hộp đèn, nghĩa là tìm những hình ảnh chung cho cả hai. Ngoài ra, lấy một hộp đèn và trừ một hộp đèn khác từ nó, nghĩa là tìm các hình ảnh trong hộp đèn đầu tiên không tồn tại trong hộp thứ hai.
- Nội dung hộp đèn có thể được kiểm tra hoặc đăng nhập. Quá trình thanh toán đặt khóa trên đối tượng kỹ thuật số, cho biết nó đã bị khóa riêng để người dùng sửa đổi. Kiểm tra bản phát hành khóa. Khóa không nên bị nhầm lẫn với khóa cơ sở dữ liệu, là một phần của giao dịch. Khóa kiểm tra độc lập với trạng thái của cơ sở dữ liệu và miễn dịch với việc khởi động lại cơ sở dữ liệu. Kiểm tra các khóa có thể có ngày hết hạn và ghi đè các khóa trên chúng để giúp quản lý chúng dễ dàng hơn.
Relationships
Một mối quan hệ là một liên kết nhiều-nhiều giữa hai đối tượng kỹ thuật số. Các loại mối quan hệ có thể được sử dụng để mô tả các đặc điểm. Thông tin có thể được lưu trữ trong mối quan hệ và có thể thích ứng theo thời gian, dẫn đến trí thông minh mạng.
Thesaurus
Một từ điển đồng nghĩa có thể được mô tả như một tập hợp các thuật ngữ được liên kết với nhau dựa trên sự giống nhau. Các thuật ngữ thuộc về một từ vựng được kiểm soát. Điều này rất quan trọng, vì các thuật ngữ đồng nghĩa mới không thể được thêm vào mà không có sự làm rõ. Một từ điển có thể được phân cấp nhưng không phải như vậy. Một từ điển phù hợp với một tiêu chuẩn được xác định. Có rất nhiều tiêu chuẩn với một tiêu chuẩn phổ biến trong việc sử dụng là từ điển đồng nghĩa.
Taxonomy
Một nguyên tắc phân loại tương tự như một từ điển đồng nghĩa, với sự bổ sung rằng nó chứa các thuật ngữ ưa thích và được sử dụng chủ yếu bởi khoa học. Nó là một phân loại trong khi một từ điển đồng nghĩa là một kho các thuật ngữ liên quan. Các thuật ngữ được chứa trong một hệ thống phân cấp và các thuật ngữ phù hợp với một từ vựng được xác định rõ. Một hệ thống phân cấp phân loại cũng được kiểm soát tốt. Trong phân loại khoa học đời sống, các cấp độ khác nhau trong hệ thống phân cấp được cố định và tương đương với các giá trị như chi, loài và phân loài.
Các ví dụ phân loại bao gồm các nguyên tắc phân loại cho hóa thạch, thực vật, tâm lý học và thậm chí cả kinh doanh. Cấu trúc phân loại có thể khác nhau về ý nghĩa, cách sử dụng và sự nghiêm ngặt của việc tuân thủ các nguyên tắc. Hầu hết các nguyên tắc phân loại chính phù hợp với một tiêu chuẩn quốc tế để đảm bảo rằng cấu trúc vẫn nhất quán và chính xác. Đảm bảo các cấu trúc phân loại là chính xác được coi là rất quan trọng.
Do tính chất cấu trúc tốt của phân loại, các truy vấn ad hoc được thực hiện đối với các đối tượng kỹ thuật số có thể được trả về trong cấu trúc phân loại.
Tài liệu tham khảo: Managing Multimedia and Unstructured Data in the Oracle Database - Marcelle Kratochvil
All rights reserved
