The 5 questions data science answers
Bài đăng này đã không được cập nhật trong 4 năm
Hi, chào mọi người. Trong bài viết này, chúng ta sẽ nói về "5 câu hỏi về data science" Data Science sử dụng những con số và tên ( còn biết như các chủng loại và nhãn dán) để tiên đoán câu trả lời của các câu hỏi. Có thể sẽ làm bạn ngạc nhiên, nhưng chúng chỉ có 5 câu hỏi về data sciense- nghiên cứu dữ liệu "Is this A or B" "Is this weird" "How much - or - How many?" "What should I do next?" Mỗi câu hỏi này được trả lời bởi những loại phương thức tính toán riêng biệt được gọi là thuật toán. Nó hữu ích để suy nghĩ về thuật toán như là công thức chế biến và dữ liệu của bạn như là nguyên liệu nấu ăn. Thuật toán sẽ chỉ ra cách để kết hợp và trộn các dữ liệu để đưa ra câu trả lời. Máy tính như là một máy sinh tố. Nó sẽ làm hết cả những công việc khó khăn trong thuật toán cho bạn và tốc độ rất nhanh.
1 Is this A or B? uses classification algorithms
 Câu hỏi đầu tiên "Chọn A hay B"
Loại thuật toán này được gọi là "hai lớp lựa chọn". Nó sẽ hữu ích cho mọi câu hỏi chỉ có hai đáp án.
Ví dụ:
Chiếc lốp xe sẽ bị bể-banh trong 1.000 dặm tiếp theo. Đúng hay sai?
Điều nào sẽ mang lại khách hàng nhiều hơn: phiếu mua hàng 5 đôla hay giảm giá 25%?
Câu hỏi này có thể diễn tả lại cho trường hợp có nhiều hơn hai sự lựa chọn: Is this A or B or C or D, etc? Nó được gọi là phân loại nhiều lớp và sẽ hữu ích khi bạn có đến hàng ngàn câu trả lời để lựa chọn. Phân loại nhiều lớp sẽ chọn một đáp án nhiều khả năng nhất.
Câu hỏi đầu tiên "Chọn A hay B"
Loại thuật toán này được gọi là "hai lớp lựa chọn". Nó sẽ hữu ích cho mọi câu hỏi chỉ có hai đáp án.
Ví dụ:
Chiếc lốp xe sẽ bị bể-banh trong 1.000 dặm tiếp theo. Đúng hay sai?
Điều nào sẽ mang lại khách hàng nhiều hơn: phiếu mua hàng 5 đôla hay giảm giá 25%?
Câu hỏi này có thể diễn tả lại cho trường hợp có nhiều hơn hai sự lựa chọn: Is this A or B or C or D, etc? Nó được gọi là phân loại nhiều lớp và sẽ hữu ích khi bạn có đến hàng ngàn câu trả lời để lựa chọn. Phân loại nhiều lớp sẽ chọn một đáp án nhiều khả năng nhất.
2: Is this weird? Nó có phải là điều bất thường- Sử dụng thuật toán tìm kiếm điều khác thường
Câu hỏi phân tích dữ liệu tiếp theo là: "Đấy có phải là điều bất thường không?" Câu hỏi này được trả lời bởi các thuật toán gọi là "nhận diện sự bất thường"
 Nếu bạn có thẻ tín dụng, bạn đã được hỗ trợ từ sự nhận điện bất thường. Công ty cung cấp thẻ tín dụng của bạn phân tích việc mua hàng của bạn, và họ có thể cảnh báo cho bạn về việc gian lận có thể xảy ra. Các khoảng phí "bất thường" có thể được ghi nhận dựa vào nơi mà bạn không thường xuyên mua hàng hoặc là một sản phẩm đắt tiền được mua.
Câu hỏi này đã trở nên rất phổ biến trong nhiều trường hợp. Ví dụ:
Nếu bạn có một chiếc xe hơi trang bị đồng hồ đo áp suất, bạn có lẽ muốn biết: máy đo áp suất có đang hoạt động bình thường không?
Nếu bạn đang theo dõi qua internet, bạn có muốn biết: đấy có phải là một tin nhắn bình thường- điển hình của internet hay không?
Việc phát hiện ra dấu hiệu bất thường, sự kiện, hành vi không bình thường, điều đó cho chúng ta manh mối để tìm ra vấn đề.
Nếu bạn có thẻ tín dụng, bạn đã được hỗ trợ từ sự nhận điện bất thường. Công ty cung cấp thẻ tín dụng của bạn phân tích việc mua hàng của bạn, và họ có thể cảnh báo cho bạn về việc gian lận có thể xảy ra. Các khoảng phí "bất thường" có thể được ghi nhận dựa vào nơi mà bạn không thường xuyên mua hàng hoặc là một sản phẩm đắt tiền được mua.
Câu hỏi này đã trở nên rất phổ biến trong nhiều trường hợp. Ví dụ:
Nếu bạn có một chiếc xe hơi trang bị đồng hồ đo áp suất, bạn có lẽ muốn biết: máy đo áp suất có đang hoạt động bình thường không?
Nếu bạn đang theo dõi qua internet, bạn có muốn biết: đấy có phải là một tin nhắn bình thường- điển hình của internet hay không?
Việc phát hiện ra dấu hiệu bất thường, sự kiện, hành vi không bình thường, điều đó cho chúng ta manh mối để tìm ra vấn đề.
3 How much? or How many? Sử dụng thuật toán đệ quy.
Machine learning can also predict the answer to How much? or How many? The algorithm family that answers this question is called regression.
Machine learning còn có thể dự đoán được câu trả lời cho câu hỏi "bao nhiêu". Thuật toán để đưa ra đáp án cho câu trả lời này gọi là đệ quy.
 Regression algorithms make numerical predictions, such as:+
What will the temperature be next Tuesday?
What will my fourth quarter sales be?
They help answer any question that asks for a number.
Các thuật toán đệ quy đưa ra con số dự đoán, chẳng hạn như:
Nhiệt độ vào ngày thứ tư đến là bao nhiêu?
Doanh thu vào quý 4 của tôi là bao nhiêu?
Regression algorithms make numerical predictions, such as:+
What will the temperature be next Tuesday?
What will my fourth quarter sales be?
They help answer any question that asks for a number.
Các thuật toán đệ quy đưa ra con số dự đoán, chẳng hạn như:
Nhiệt độ vào ngày thứ tư đến là bao nhiêu?
Doanh thu vào quý 4 của tôi là bao nhiêu?
4: How is this organized?- sử dụng thuật toán phân cụm
Now the last two questions are a bit more advanced.
Sometimes you want to understand the structure of a data set - How is this organized? For this question, you don’t have examples that you already know outcomes for.
There are a lot of ways to tease out the structure of data. One approach is clustering. It separates data into natural "clumps," for easier interpretation. With clustering, there is no one right answer.
Bây giờ hai câu hỏi cuối cùng sẽ nâng cao hơn một chút.
Nhiều lần bạn muốn hiểu cấu trúc của tập dữ liệu - Nó tổ chức như thế nào? Về câu hỏi này, bạn không có ví dụ mà bạn đã biết rõ về kết quả cho nó.
Chúng có nhiều cách để tiếp cận cấu trúc dữ liệu, một trong số đó là thuật toán tập hợp. Nó phân tích dữ liệu thành các tập hợp tự nhiên để giải thích dễ dàng hơn. Với thuật toán tập hợp không có câu trả lời đúng.
 Common examples of clustering questions are:
Which viewers like the same types of movies?
Which printer models fail the same way?
By understanding how data is organized, you can better understand - and predict - behaviors and events.
Các ví cơ bản về câu hỏi tập hợp (phân nhóm) là:
Những người xem nào cùng thích xem một thể loại phim giống nhau?
Những dòng máy in nào có lỗi giống nhau?
Bằng việc hiểu "how data is organized?" dữ liệu được tổ chức như thế nào, bạn có thể hiểu, dự đoán được các hành vi và sự kiện xảy ra.
Common examples of clustering questions are:
Which viewers like the same types of movies?
Which printer models fail the same way?
By understanding how data is organized, you can better understand - and predict - behaviors and events.
Các ví cơ bản về câu hỏi tập hợp (phân nhóm) là:
Những người xem nào cùng thích xem một thể loại phim giống nhau?
Những dòng máy in nào có lỗi giống nhau?
Bằng việc hiểu "how data is organized?" dữ liệu được tổ chức như thế nào, bạn có thể hiểu, dự đoán được các hành vi và sự kiện xảy ra.
5 What should I do now? sử dụng các thuật toán học tăng trưởng
Câu hỏi cuối cùng - What should I do now? - sử dụng các thuật toán được gọi là "học dần"- reinforcement learning
Reinforcement learning được lấy nguồn từ việc não của loài chuột và loài người hồi đáp ( hành động) để nhận phần thưởng hoặc trừng phạt.
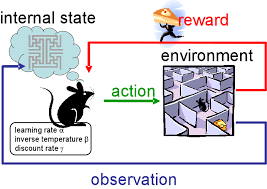 Thuật toán "học tăng trưởng" sẽ học từ kết quả và đưa ra quyết định cho hành động kế tiếp. Thông thường thuật toán "học tăng trưởng" là cực kì phù hợp cho các hệ thống tự động để có thể tự đưa ra quyết định và thực thi các hành động nhỏ mà không cần sự điều kiển của con người.
Thuật toán "học tăng trưởng" sẽ học từ kết quả và đưa ra quyết định cho hành động kế tiếp. Thông thường thuật toán "học tăng trưởng" là cực kì phù hợp cho các hệ thống tự động để có thể tự đưa ra quyết định và thực thi các hành động nhỏ mà không cần sự điều kiển của con người.
 Những câu hỏi luôn trả lời bằng hành động nên được thực thi - thường được thực hiện bởi các máy móc - robot, Ví dụ:
Nếu tôi là hệ thống điều chỉnh nhệt độ trong căn nhà, tôi sẽ điều chỉnh nhiệt độ hay cứ để im như vậy?
Nếu tôi là chiếc xe tự lái, vào lúc đèn vàng sẽ phanh hay tăng tốc?
Thuật toán "học tăng trưởng" sẽ học, thu thập dữ liệu khi nó "chạy"- thực thi, học từ các lần thử và lỗi.
Những câu hỏi luôn trả lời bằng hành động nên được thực thi - thường được thực hiện bởi các máy móc - robot, Ví dụ:
Nếu tôi là hệ thống điều chỉnh nhệt độ trong căn nhà, tôi sẽ điều chỉnh nhiệt độ hay cứ để im như vậy?
Nếu tôi là chiếc xe tự lái, vào lúc đèn vàng sẽ phanh hay tăng tốc?
Thuật toán "học tăng trưởng" sẽ học, thu thập dữ liệu khi nó "chạy"- thực thi, học từ các lần thử và lỗi.
All rights reserved
