Test thử Benchmark Hiệu năng 7 LLM trên NVIDIA V100
Bài viết này sẽ phân tích chi tiết hiệu năng của 7 mô hình phổ biến trên cấu hình NVIDIA V100 GPU Server thông qua trình quản lý Ollama.

1. Test thử cấu hình Máy chủ GPU NVIDIA V100
NVIDIA V100 hiện là lựa chọn tối ưu về chi ph ícho việc train các mô hình ngôn ngữ lớn (LLM). Dù không phải là dòng chip mới nhất, V100 vẫn duy trì sức hút nhờ hiệu suất ổn định, đặc biệt phù hợp để triển khai các mô hình phổ biến như Llama 2, Mistral hay DeepSeek R1 mà không đòi hỏi ngân sách đầu tư phần cứng quá lớn.

Môi trường thử nghiệm và Đo lường hiệu năng
Để đảm bảo tính khách quan, hệ thống được thiết lập trên nền tảng Ollama inference engine. Đây là công cụ tối ưu hóa tài nguyên GPU hàng đầu hiện nay, giúp trích xuất các dữ liệu benchmark chuẩn xác về:
- Tốc độ xử lý: Số lượng tokens trên giây (tokens/s).
- Mức độ tiêu thụ: Tỷ lệ chiếm dụng CPU, RAM và hiệu suất sử dụng GPU (GPU Utilization).

Sự kết hợp giữa sức mạnh phần cứng của V100 và khả năng tối ưu của Ollama tạo ra một môi trường tiêu chuẩn để đánh giá năng lực xử lý các tác vụ chatbot, trợ lý ảo và NLP thời gian thực.
Dưới đây là kết quả thử nghiệm chi tiết trên các dòng mô hình tiêu biểu:
2. DeepSeek R1 trên V100
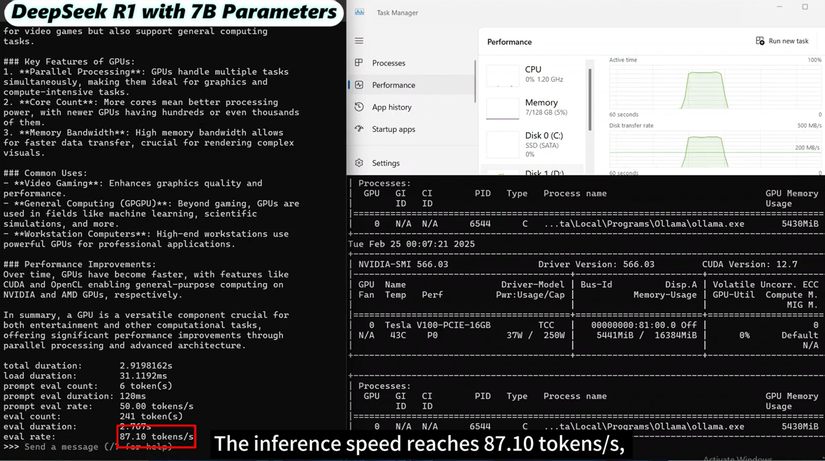
- DeepSeek R1 7B: Đây là phiên bản nhỏ nhất, chỉ chiếm 4.7 GB dung lượng
- Mô hình này chủ yếu khai thác sức mạnh từ GPU với mức sử dụng CPU và bộ nhớ rất nhẹ, đạt tốc độ xử lý ấn tượng 87.10 tokens/s
- DeepSeek R1 8B: Với kích thước 4.9 GB, mức độ sử dụng GPU tăng lên 78
- Tốc độ inference đạt 83.03 tokens/s, giảm nhẹ so với bản 7B nhưng vẫn duy trì được hiệu suất làm việc hiệu quả
- DeepSeek R1 14B: Khi kích thước tăng lên 9 GB, tải trọng tính toán cũng tăng đáng kể khiến mức sử dụng GPU đạt 80%
- Tốc độ inference lúc này giảm xuống còn 48.63 tokens/s
3. Benchmark dòng Llama 2: Sự vượt trội về hiệu suất
Llama 2 từ Meta vẫn chứng tỏ là một "tượng đài" về khả năng tối ưu hóa trên phần cứng NVIDIA.
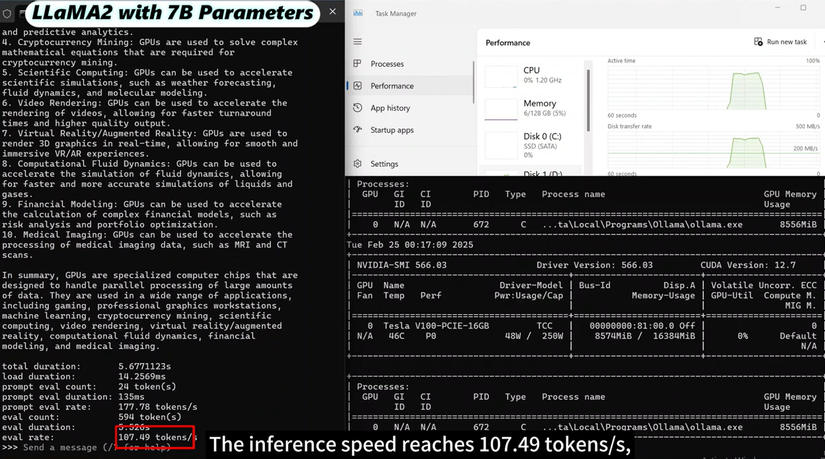
-
Llama 2 7B: Là một mô hình nhẹ với mức sử dụng tài nguyên hệ thống (CPU/RAM) thấp. Tốc độ đạt tới 107.49 tokens/s, cao hơn hẳn so với DeepSeek R1 7B, cho thấy hiệu quả suy luận cực kỳ xuất sắc.
-
Llama 2 13B: Với kích thước 7.4 GB, mô hình đạt tốc độ 67.51 tokens/s. Mặc dù thấp hơn bản 7B nhưng nó vẫn hoạt động hiệu quả hơn các mô hình DeepSeek có kích thước tương đương.
Một vài nhận xét nhanh:
Về tốc độ: Bản 7B nhanh hơn bản 13B khoảng 1.6 lần, khiến nó trở thành lựa chọn lý tưởng cho các ứng dụng cần phản hồi thời gian thực.
Về hiệu quả: Cả hai mô hình đều cho thấy sự tối ưu hóa tốt hơn so với đối thủ DeepSeek ở các mức tham số tương đương trong bài test.
4. Thử nghiệm với Qwen 2.5 và Gemma 2
Đối với các mô hình có cấu trúc phức tạp hơn hoặc số lượng tham số lớn hơn, giới hạn của V100 bắt đầu lộ diện.
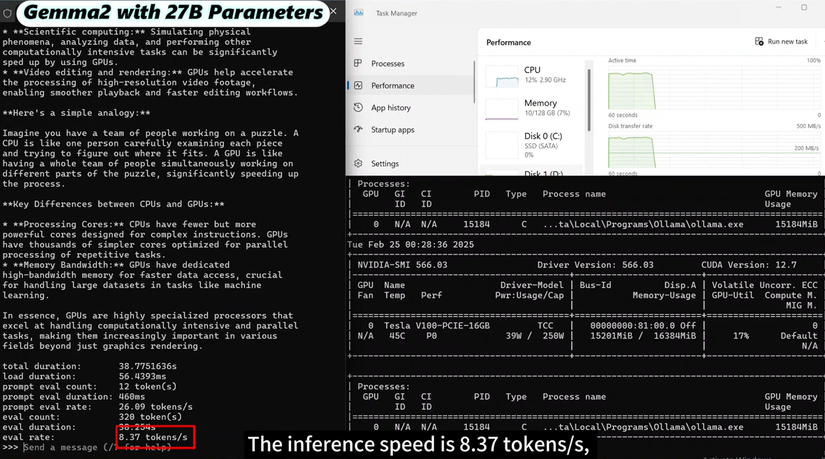
-
Qwen 2.5 14B: Mô hình này có hiệu năng tương đồng với DeepSeek R1 cùng kích cỡ, đạt tốc độ 49.38 tokens/s với 80% GPU utilization.
-
Gemma 2 27B: Đây là "thử thách" lớn nhất trong bài kiểm tra. Tốc độ inference sụt giảm nghiêm trọng chỉ còn 8.37 tokens/s. Đáng chú ý, mức sử dụng GPU chỉ đạt 13% - 24%, trong khi CPU lại bị đẩy lên rất cao, cho thấy GPU V100 chưa được khai thác hiệu quả cho mô hình lớn này.
Phân tích bổ sung: Sự chênh lệch về hiệu quả: Trong khi Qwen 2.5 14B cho thấy khả năng tương thích tốt với phần cứng (GPU utilization đạt 80%), thì Gemma 2 27B lại gặp vấn đề nghiêm trọng về việc phân bổ tài nguyên.
Vấn đề của Gemma 2 27B: Với mức sử dụng GPU thấp nhưng CPU lại rất cao, có thể thấy mô hình này đang bị giới hạn bởi băng thông bộ nhớ hoặc thiếu các kỹ thuật tối ưu hóa cụ thể cho dòng GPU V100 khi chạy ở kích thước tham số lớn.
Đánh giá: V100 vẫn rất "ngon" trong tầm giá
NVIDIA V100 là lựa chọn kinh tế nếu bạn cần giải pháp thuê máy chủ GPU train AI không quá đắt đỏ nhưng vẫn đảm bảo hiệu suất cho các ứng dụng thực tế.
Kết quả benchmark thực tế:
- DeepSeek R1 (7B - 8B): Chạy cực mượt. Bản 7B đạt 87.10 tokens/s. Bản 8B chiếm 78% GPU, tốc độ khoảng 83 tokens/s
- Llama 2 (7B - 13B): Đây là "nhà vô địch" về độ ổn định. Bản 7B vọt lên 107.49 tokens/s. Bản 13B vẫn giữ mức 67.51 tokens/s, nhanh hơn hẳn các đối thủ cùng tầm
- Qwen 2.5 & DeepSeek R1 (14B): Khi tăng kích thước lên 14B, tốc độ giảm còn khoảng 48-49 tokens/s. GPU lúc này đã load đến 80%.
Điểm yếu cần lưu ý: Gemma 2 27B Đừng cố chạy Gemma 2 27B trên V100 nếu bạn cần tốc độ. Trải nghiệm thực tế rất tệ khi chỉ đạt 8.37 tokens/s. GPU chỉ sử dụng khoảng 13-24% trong khi CPU bị đẩy lên quá cao, cho thấy sự nghẽn cổ chai rõ rệt.
Lời khuyên cho bạn
Nên dùng V100 khi: Triển khai Chatbot, trợ lý ảo hoặc các ứng dụng NLP thời gian thực với các model từ 7B đến 24B. Nó cực kỳ tối ưu cho Llama 2 và DeepSeek R1 bản nhỏ.
Nên nâng cấp (RTX 4090 hoặc A100) khi: Bạn bắt buộc phải chạy các mô hình lớn hơn 27B để đảm bảo tốc độ phản hồi không bị trễ.
All rights reserved
