Tản mạn về Copy-on-write
Bài đăng này đã không được cập nhật trong 9 năm
Có thể nhiều người chưa biết, nhưng những gì chúng ta sử dụng hàng ngày đều ít nhiều có hình bóng của Copy-on-write (Gọi tắt là COW cho dễ). Nó là một kỹ thuật cực phổ biến trong lập trình nhưng lại khá nhiều người không biết tới.
Khái niệm
Về khái niệm chi tiết, bạn có thể tham khảo quá wiki Copy-on-write. Về cơ bản, có thể tạm hiểu như thế này, có rất nhiều tác vụ được sinh ra, và khởi điểm chúng đều có resource trỏ tới cùng một nơi, sau này khi có tác vụ nào đó dở hơi muốn đổi dữ liệu resource, thì nó sẽ copy resource ra một bản mới, và tự tung tự tác sửa đổi trên bản mới này, bản cũ vẫn giữ nguyên để phục vụ cho các tác vụ khác. Lợi ích cực lớn mang lại là ta có thể dùng nhiều tác vụ nhưng tài nguyên bỏ ra cho chúng là cực kỳ tiết kiệm.
Chi tiết
Để làm rõ hơn, ta có ví dụ đơn giản như sau. Ta có 1 process A, có resource là SA. Từ A ta tạo ra một loạt process con A1, A2, A3 ..., như trên Linux, khi các process con sẽ có resource như thằng cha. Nếu không sử dụng COW, với mỗi process con ta sẽ phải tạo thêm resource cho riêng nó, thực sự như vậy không hề ổn chút nào, tài nguyên bao nhiêu cho đủ. Với COW, tất cả thằng con sinh ra đều có resource trỏ thẳng vào resource thằng cha, sau này process nào cần sửa chữa dữ liệu, nó sẽ copy thằng resource của cha ra một bản mới, và sửa chữa trên đó.
Xem xét tình huống
Cụ thể hơn về flow, ta xem xét cây nhị phân dưới đây.
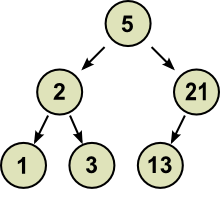
Bây giờ ta cần thêm một node chứa giá trị 34 nữa vào làm con của node 21. Thông thường ta sẽ nhét thằng nó vào như thế này

Giờ cây nhị phân của ta đã thay đổi, cây nhị phân ban đầu đã ra đi theo gió. Vậy nên tại một thời điểm, ta chỉ có một phiên bản duy nhất của cây nhị phân đang xem xét, nghe có vẻ không ổn lắm.
Với cấu trúc sử dụng COW, một khi bạn đã tạo thì nó sẽ không bao giờ bị thay đổi cấu trúc ban đầu, có chăng chỉ là sửa đổi trên những bản sao của nó. Vậy giờ, khi cần thêm node 34 vào node 21, ta phải làm gì ? Copy nguyên bản cây nhị phân ban đầu ra rồi sửa, như thế sẽ vẫn tốn nhiều tài nguyên. Dù có thêm node 34 vào, thì cấu trúc của bản mới cũng không có quá nhiều khác biệt so với bản gốc, ta hoàn toàn có thể trỏ lung tung tới những node không thay đổi. Cụ thể ta sẽ có
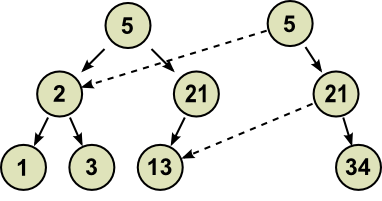
Đó, ta sẽ có thêm một phiên bản của cây nhị phân ban đầu theo cấu trúc ta mới sửa, cực kỳ tiết kiệm tài nguyên và giữ lại được bản gốc ban đầu.
Ứng dụng
Ứng dụng của COW là rất lớn, điển hình như cơ chế sinh process con ở Linux mà ta ví dụ ở trên. Thao tác Undo trên các ứng dụng ta sử dụng hàng ngày cũng áp dụng COW, ngoài ra còn những thứ áp dụng COW như software transactional memory , automatic memory management...
Kết luận
Bài viết trên mình có nêu khái niệm đại khái về COW, ví dụ thực thế để nắm rõ cách thức hoạt động, cũng như chỉ ra vài ứng dụng thực tế của chúng. Do kiến thức còn hạn hẹp nên bài viết tất không tránh khỏi sai sót, mong bạn đọc tích cực đóng góp ý kiến để mình củng cố kiến thức cũng như hoàn thiện bài viết.
All rights reserved
