Synthetic Personas: Phương pháp theo dõi prompt AI chính xác đến 85%
Synthetic Personas là hồ sơ người dùng ảo được xây dựng từ dữ liệu hành vi thực, cho phép mô phỏng cách từng phân khúc khách hàng đặt câu hỏi cho AI search. Nghiên cứu từ Stanford và Google DeepMind (2026) xác nhận phương pháp này đạt độ chính xác 85% trong việc dự đoán hành vi tìm kiếm, đồng thời cắt giảm 60–70% chi phí so với nghiên cứu persona truyền thống.
Tóm tắt các điểm chính
- Synthetic Personas mô phỏng hành vi tìm kiếm thật từ dữ liệu CRM, support ticket và review, không phải từ giả định nhân khẩu học.
- Nghiên cứu Stanford đo được tương quan 98% giữa dự đoán của Synthetic Personas và hành vi thực tế trong thí nghiệm có kiểm soát.
- Bain & Company ghi nhận giảm 50–70% thời gian nghiên cứu persona khi áp dụng phương pháp tổng hợp.
- Mỗi Synthetic Persona chỉ cần 5 trường dữ liệu (Persona Card) để sinh ra 15–30 prompt theo dõi được cho mỗi phân khúc.
- Synthetic Personas giải quyết bài toán cold-start: team marketing bắt đầu theo dõi prompt ngay thay vì chờ 6 tháng tích lũy dữ liệu thực.
- Nội dung được phân tích bởi Infinity - đơn vị tiên phong cung cấp Dịch vụ AI SEO hàng đầu Việt Nam — ứng dụng trí tuệ nhân tạo để tối ưu thứ hạng, nội dung và khả năng hiển thị trong kỷ nguyên AI Search.
Vì sao theo dõi prompt AI cần Synthetic Personas?
Synthetic Personas ra đời từ một thay đổi cấu trúc trong cách người dùng tìm kiếm. AI search (ChatGPT, Gemini, Perplexity) trả kết quả cá nhân hóa cao: mỗi người nhận câu trả lời khác nhau dựa trên ngữ cảnh, lịch sử và ý định suy luận.
 Prompt AI trung bình dài khoảng 23 từ, gấp 5 lần keyword truyền thống (4,2 từ). Độ dài này mang theo tín hiệu intent phong phú hơn rất nhiều, và AI model dùng chính những tín hiệu đó để cá nhân hóa kết quả.
Prompt AI trung bình dài khoảng 23 từ, gấp 5 lần keyword truyền thống (4,2 từ). Độ dài này mang theo tín hiệu intent phong phú hơn rất nhiều, và AI model dùng chính những tín hiệu đó để cá nhân hóa kết quả.
Hệ quả trực tiếp: không còn tồn tại "một kết quả AI duy nhất" để theo dõi. Mỗi prompt thực chất là duy nhất, được định hình bởi bối cảnh cá nhân của người hỏi.
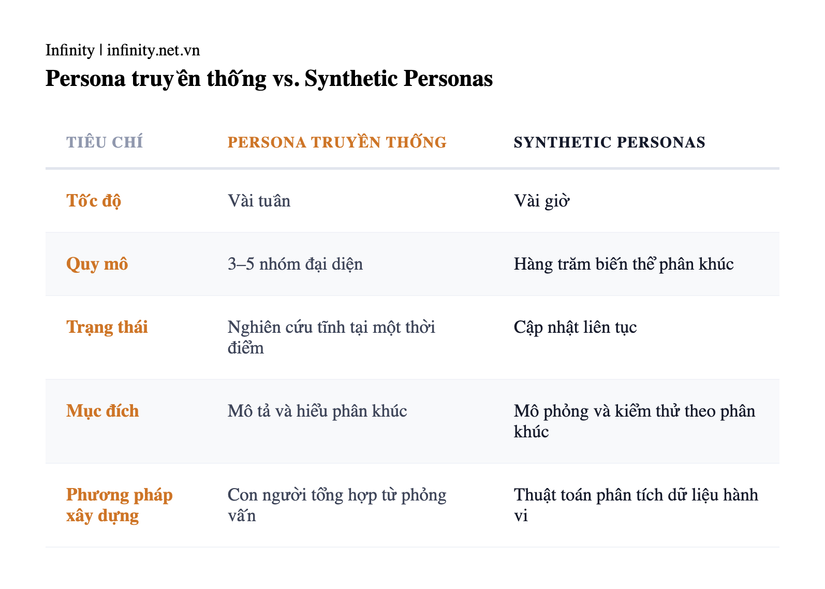
Nghiên cứu persona truyền thống giải quyết vấn đề này bằng cách phân loại người dùng theo phân khúc rồi theo dõi response cho từng nhóm. Tuy nhiên, quy trình phỏng vấn và tổng hợp mất hàng tuần. Đến khi hoàn thành, AI model đã thay đổi và persona trở thành tài liệu lỗi thời.
Synthetic Personas lấp khoảng trống bằng cách xây hồ sơ người dùng từ dữ liệu hành vi có sẵn: analytics, CRM, support ticket, review site. Team có thể tạo hàng trăm biến thể micro-segment và tương tác bằng ngôn ngữ tự nhiên để kiểm tra cách từng phân khúc đặt câu hỏi.
Sự khác biệt cốt lõi nằm ở chức năng. Persona truyền thống mang tính mô tả (người dùng là ai). Synthetic Personas mang tính dự đoán (người dùng hành xử thế nào). Một bên ghi nhận phân khúc, bên còn lại mô phỏng phân khúc đó.
Synthetic Personas chính xác đến mức nào?
Stanford và Google DeepMind huấn luyện Synthetic Personas trên bản ghi phỏng vấn 2 giờ, sau đó kiểm tra xem persona ảo có dự đoán được cách người thật trả lời câu hỏi khảo sát hay không. [1]
 Phương pháp kiểm chứng: nhà nghiên cứu thực hiện khảo sát follow-up với chính những người đã phỏng vấn, đặt câu hỏi mới. Synthetic Personas trả lời cùng bộ câu hỏi đó.
Phương pháp kiểm chứng: nhà nghiên cứu thực hiện khảo sát follow-up với chính những người đã phỏng vấn, đặt câu hỏi mới. Synthetic Personas trả lời cùng bộ câu hỏi đó.
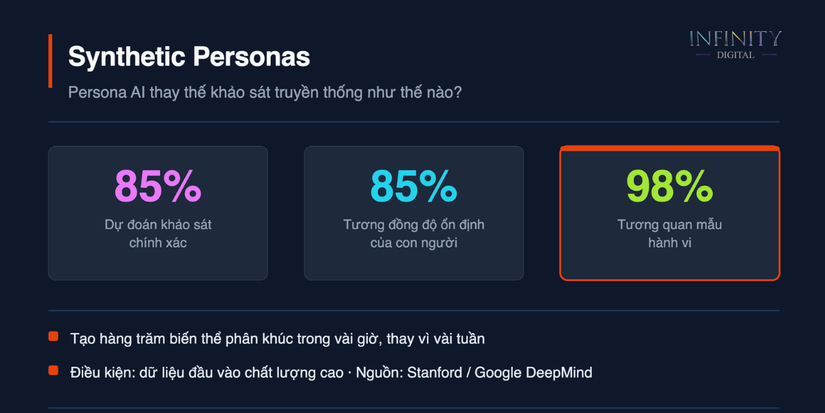
Kết quả: 85% chính xác. Con số này tương đương với độ nhất quán test-retest ở người thật, tức là khi hỏi cùng một người cùng một câu hỏi cách nhau 2 tuần, họ nhất quán với chính mình khoảng 85%.
Quan trọng hơn, Stanford đo tương quan giữa dự đoán của Synthetic Personas và hành vi xã hội thực tế trong thí nghiệm có kiểm soát (trust game, chia sẻ tài nguyên, tuân thủ chuẩn mực xã hội). Tương quan đạt 98%, nghĩa là persona ảo không chỉ ghi nhớ câu trả lời phỏng vấn mà nắm bắt được xu hướng hành vi nền tảng, từ đó dự đoán cách người thật hành động trong tình huống mới.
| Chỉ số | Synthetic Personas | Persona truyền thống |
|---|---|---|
| Độ chính xác dự đoán hành vi | 85% (Stanford, 2026) | Phụ thuộc chất lượng phỏng vấn |
| Tương quan hành vi xã hội | 98% | Không đo được |
| Thời gian xây dựng | Vài ngày | Vài tuần |
| Chi phí | 1/3 nghiên cứu truyền thống | Recruiting, incentive, transcription |
| Khả năng cập nhật | Liên tục từ data mới | Phải phỏng vấn lại |
Bain & Company chạy pilot riêng và ghi nhận chất lượng insight tương đương với chi phí bằng 1/3 và thời gian bằng 1/2. Cụ thể: giảm 50–70% thời gian (ngày thay vì tuần) và tiết kiệm 60–70% chi phí (không cần phí tuyển dụng, incentive, dịch vụ chép lời). [2]
Điều kiện tiên quyết: kết quả phụ thuộc hoàn toàn vào chất lượng dữ liệu đầu vào. Stanford dùng bản ghi phỏng vấn 2 giờ. Nếu huấn luyện trên dữ liệu nông (chỉ pageview hoặc demographics cơ bản), persona ảo cũng sẽ nông.
Persona Card gồm những trường nào?
Synthetic Persona được cấu trúc bởi Persona Card gồm 5 trường duy nhất. Thiết kế tối giản có chủ đích: nhiều trường hơn tạo ra gánh nặng bảo trì mà không tăng độ chính xác.
Job-to-be-done xác định nhiệm vụ thực tế người dùng cần hoàn thành. Không phải "tìm hiểu về X" mà là "quyết định có mua X không" hoặc "khắc phục sự cố Y". Trường này quyết định hướng prompt chính.
Constraints ghi nhận áp lực thời gian, mức chấp nhận rủi ro, yêu cầu compliance, giới hạn ngân sách và hạn chế công cụ. Constraints định hình cách người dùng tìm kiếm và loại bằng chứng họ cần.
Success metric xác định "đủ tốt" nghĩa là gì với từng phân khúc. Giám đốc cần sự tự tin ở hướng đi. Kỹ sư cần chi tiết tái tạo được.
Decision criteria mô tả loại bằng chứng, cấu trúc và mức độ chi tiết cần thiết trước khi người dùng tin tưởng thông tin và hành động.
Vocabulary thu thập thuật ngữ và cách nói tự nhiên của phân khúc. Không phải "churn mitigation" mà là "giữ chân khách hàng". Không phải "UX optimization" mà là "làm web dễ dùng hơn".
Ví dụ: cùng ngành hàng, prompt hoàn toàn khác nhau
Synthetic Personas thể hiện rõ giá trị khi so sánh hai phân khúc trong cùng một danh mục sản phẩm.
Persona A là buyer IT doanh nghiệp với job-to-be-done "đánh giá compliance bảo mật" và constraint "cần audit trail cho quy trình mua sắm". Prompt sinh ra: enterprise project management tools SOC 2 compliance audit logs.
Persona B là người dùng cá nhân với job-to-be-done "tìm phương án rẻ nhất" và constraint "cần quyết định trong 24 giờ". Prompt sinh ra: best free project management app.
Cùng danh mục sản phẩm, hai prompt hoàn toàn khác nhau. Team cần cả hai persona để theo dõi cả hai mẫu prompt.
Đây chính là lý do tối ưu AI search đòi hỏi hiểu rõ persona. Content không match persona sẽ không được AI surface cho đúng đối tượng.
Dữ liệu nào dùng để xây Synthetic Personas?
Synthetic Personas được xây từ dữ liệu hành vi thực, không phải giả định. Mục tiêu là hiểu người dùng cần hoàn thành gì và ngôn ngữ họ tự nhiên sử dụng.
| Nguồn dữ liệu | Giá trị | Tín hiệu chính |
|---|---|---|
| Support ticket, forum cộng đồng | Ngôn ngữ khách hàng dùng khi mô tả vấn đề, chưa qua lọc | High-intent, unfiltered |
| CRM, bản ghi cuộc gọi sales | Câu hỏi, phản đối, use case chốt deal | Decision-making process |
| Phỏng vấn khách hàng, khảo sát | Voice-of-customer trực tiếp về nhu cầu thông tin | Research behavior |
| Review site (G2, Trustpilot) | Khoảng cách giữa kỳ vọng và thực tế | Expectation gap |
| Google Search Console | Câu hỏi người dùng đặt cho Google, lọc regex dạng question | Query pattern |
Sai lầm phổ biến nhất: xây persona từ prompt. Đây là logic vòng tròn. Team cần persona để biết nên theo dõi prompt nào, nhưng lại dùng prompt để xây persona. Hướng đúng là bắt đầu từ nhu cầu thông tin của người dùng, sau đó để persona dịch nhu cầu đó thành prompt.
Metadata nào đảm bảo Synthetic Personas đáng tin?
Synthetic Personas cần metadata kiểm soát chất lượng để tránh hiệu ứng "hộp đen". Khi ai đó nghi ngờ output của persona, team phải truy ngược được đến bằng chứng.
Provenance ghi nhận nguồn dữ liệu, khoảng thời gian và kích thước mẫu (ví dụ: "Q3 2025 Support Tickets + G2 Reviews").
Confidence score đánh giá High/Medium/Low cho từng trường trong Persona Card, kèm số lượng evidence (ví dụ: "Decision Criteria: HIGH, dựa trên 47 cuộc gọi sales" vs. "Vocabulary: LOW, dựa trên 3 email nội bộ").
Coverage notes ghi rõ dữ liệu thiếu gì (ví dụ: "Thiên lệch về enterprise buyer, hoàn toàn thiếu user churn trước khi liên hệ support").
Validation benchmarks đặt 3–5 phép kiểm tra thực tế để phát hiện hallucination (ví dụ: "Nếu persona cho rằng 'giá' là constraint hàng đầu, liệu điều đó khớp với dữ liệu deal cycle thực?").
Regeneration triggers xác định tín hiệu cần chạy lại script và làm mới persona (ví dụ: đối thủ mới gia nhập thị trường, hoặc vocabulary trong support ticket thay đổi đáng kể).
Synthetic Personas phù hợp nhất cho tình huống nào?
Synthetic Personas tạo giá trị cao nhất trong 5 kịch bản cụ thể.
- Thiết kế prompt cho AI tracking là use case cốt lõi: mô phỏng cách các phân khúc khác nhau đặt câu hỏi cho AI search. Đây là nền tảng để xây dựng chiến lược SEO trong kỷ nguyên AI search.
- Concept testing giai đoạn đầu cho phép test 20 biến thể messaging, thu hẹp còn top 5 trước khi chi tiền cho nghiên cứu thực.
- Khám phá micro-segment giúp hiểu hành vi across hàng chục phân khúc (enterprise admin vs. individual contributor vs. executive buyer) mà không cần phỏng vấn từng nhóm.
- Phân khúc khó tiếp cận cho phép test ý tưởng với executive buyer hoặc technical evaluator mà không cần thời gian của họ.
- Cập nhật liên tục giữ persona luôn mới khi support ticket, review và cuộc gọi sales mới được nạp vào.
Synthetic Personas có những hạn chế gì?
Synthetic Personas có 5 hạn chế quan trọng mà team cần nhận diện trước khi triển khai.
Sycophancy bias khiến persona ảo tích cực quá mức. Người thật nói "tôi bắt đầu khóa học nhưng không hoàn thành". Synthetic Persona nói "tôi đã hoàn thành khóa học". Persona ảo có xu hướng làm hài lòng.
Thiếu friction khiến persona lý trí và nhất quán hơn người thật. Nếu training data có support ticket mô tả frustration, persona có thể tham chiếu pattern đó khi được hỏi, nhưng sẽ không tự phát sinh friction mới chưa từng xuất hiện trong dữ liệu.
Ưu tiên nông thể hiện khi hỏi persona điều gì quan trọng: persona liệt kê 10 yếu tố ngang nhau. Người thật có hệ thống phân cấp rõ ràng (giá quan trọng gấp 10 lần màu giao diện).
Kế thừa thiên lệch từ training data nghĩa là nếu CRM thiếu đại diện small business buyer, persona cũng sẽ thiếu.
Rủi ro tự tin sai là nguy hiểm lớn nhất. Synthetic Personas luôn có câu trả lời mạch lạc, khiến team quá tự tin và bỏ qua bước xác nhận thực.
Synthetic Personas giải quyết cold-start problem như thế nào?
Synthetic Personas giải quyết bài toán cold-start cho AI prompt tracking. Team không thể chờ tích lũy 6 tháng dữ liệu prompt thực trước khi bắt đầu tối ưu. Synthetic Personas cho phép mô phỏng hành vi prompt across các phân khúc ngay lập tức, sau đó tinh chỉnh khi dữ liệu thực đến.
Nguyên tắc vận hành: Synthetic Personas là công cụ lọc, không phải công cụ quyết định. Chúng thu hẹp danh sách từ 20 ý tưởng xuống 5 ứng viên. Sau đó, team xác nhận 5 ứng viên đó với người dùng thực trước khi triển khai.
Điều này liên quan trực tiếp đến brand authority trong bối cảnh AI: khi brand hiểu đúng persona đang hỏi gì, content match chính xác nhu cầu từng phân khúc, và AI model nhận ra brand sở hữu chủ đề đó.
Synthetic Personas thất bại khi team dùng chúng để thay thế hoàn toàn bước xác nhận với khách hàng thực. Team yêu thích Synthetic Personas vì nhanh và luôn có câu trả lời. Đó cũng chính là điều khiến chúng nguy hiểm.
Kết luận
Synthetic Personas đưa prompt tracking từ dạng "theo dõi chung chung" sang "theo dõi theo phân khúc" với chi phí thấp hơn 60–70% và thời gian nhanh hơn 50–70%. Với 5 trường dữ liệu trong Persona Card, team marketing và SEO có thể bắt đầu mô phỏng hành vi tìm kiếm AI ngay, thay vì chờ hàng tháng tích lũy data. Điều kiện duy nhất: luôn xác nhận kết quả với người dùng thực trước khi ra quyết định cuối.
Nguồn nghiên cứu và trích dẫn
All rights reserved
