sử dụng index trong sql query
Bài đăng này đã không được cập nhật trong 4 năm
Index là một trong những yếu tố quan trọng nhất góp phần vào việc nâng cao hiệu suất của cơ sở dữ liệu. Index trong SQL tăng tốc độ của quá trình truy vấn dữ liệu bằng cách cung cấp phương pháp truy xuất nhanh chóng tới các dòng trong các bảng, tương tự như cách mà mục lục của một cuốn sách giúp bạn nhanh chóng tìm đến một trang bất kỳ mà bạn muốn trong cuốn sách đó.
Index trong SQL Server được tạo ra trên các cột trong bảng hoặc View. Chúng cung cấp một phương pháp giúp bạn nhanh chóng tìm kiếm dữ liệu dựa trên các giá trị trong các cột. Ví dụ, nếu bạn tạo ra một Index trên cột khóa chính và sau đó tìm kiếm một dòng dữ liệu dựa trên một trong các giá trị của cột này, đầu tiên SQL Server sẽ tìm giá trị này trong Index, sau đó nó sử dụng Index để nhanh chóng xác định vị trí của dòng dữ liệu bạn cần tìm. Nếu không có Index, SQL Server sẽ thực hiện động tác quét qua toàn bộ bảng (table scan) để xác định vị trí dòng cần tìm. Giống như khi bạn cần tìm kiếm thông tin trên một quyển sách, nếu bạn định nghĩa được thông tin mình cần tìm dựa trên các phần mục lục sách cung cấp: tên tác giả, keyword v.v.. bạn chỉ cần đến phần mục lục của sách và tìm kiếm trong mục lục thay vì bạn phải tìm hết cả quyển sách.
Index trong SQL Server có thể tạo trên hầu hết các cột trong bảng hoặc View. Tuy nhiên chúng ta không nên tạo index trên các cột có kiểu dữ liệu quá lớn vì để sử dụng index SQL server cần chi phí để quản lý một vùng nhớ mình tạm gọi nó là mục lục ở đây. Độ lớn của mục lục sẽ tỉ lệ thuận với length index key bạn sử dụng.
Index trong SQL Server được tạo thành từ một tập hợp các page (các Index Node) và chúng được tổ chức trong một cấu trúc có tên gọi là B-tree. Tất nhiên ngoài B-tree ra thì SQL còn sử dụng thêm các kiểu index phức tạp khác nữa, nhưng trong bài này mình sẽ chỉ tập trung vào B-tree là cấu trúc thông dụng nhất. Một index chứa các keys được xây dựng từ một hoặc nhiều cột trong table hoặc view.
Đầu tiên chúng ta cần xác định cấu trúc "mục lục" sql server sẽ cung cấp.
1. B-tree là gì?
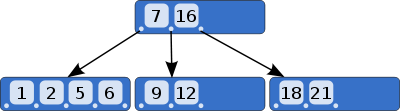
Chi tiết hơn bạn có thể tham khảo tại đây hoặc lên google và tìm kiếm  Chúng ta có thể hiểu index sẽ cung cấp cho chúng ta danh sách các bản ghi của các column được chỉ định theo thứ tự tăng dần. Tức là để tìm ra số 10 thì chúng ta phải tìm kiếm nó ở khoảng giữa số 9 và 12. Nếu giữa 9 và 12 mà không có thì không cần tìm tiếp nữa, vì chắc chắn nó không ở chỗ khác đâu . CÒn nếu không có index thì chúng ta phải tìm toàn bộ thôi. SQL server hoạt động giống như những gì chúng ta làm, thế nên đừng bắt nó thực hiện scan hết toàn bộ dữ liệu nha, vất vả lắm.
Chúng ta có thể hiểu index sẽ cung cấp cho chúng ta danh sách các bản ghi của các column được chỉ định theo thứ tự tăng dần. Tức là để tìm ra số 10 thì chúng ta phải tìm kiếm nó ở khoảng giữa số 9 và 12. Nếu giữa 9 và 12 mà không có thì không cần tìm tiếp nữa, vì chắc chắn nó không ở chỗ khác đâu . CÒn nếu không có index thì chúng ta phải tìm toàn bộ thôi. SQL server hoạt động giống như những gì chúng ta làm, thế nên đừng bắt nó thực hiện scan hết toàn bộ dữ liệu nha, vất vả lắm.
Khi một truy vấn được xây dựng dựa trên các cột được tạo Index, cỗ máy thực thi truy vấn sẽ bắt đầu tại nút gốc và điều hướng qua các nút trung gian cho đến khi cỗ máy truy vấn tìm được đến nút lá. Ví dụ, nếu bạn đang tìm kiếm giá trị 123 trong một cột được tạo index, ví dụ như cột ID chẳng hạn, đầu tiên cỗ máy truy vấn sẽ tìm ở nút gốc (Root Level) để xác định page nào sẽ được tham chiếu tới ở level trung gian (Intemediate Level). Trong ví dụ này, trang đầu tiên chỉ các giá trị từ 1-100, và trang thứ hai là các giá trị 101-200, vì vậy cỗ máy truy vấn sẽ đi đến trang thứ hai ở level trung gian. Cỗ máy truy vấn sau đó sẽ xác định trang tiếp theo mà nó phải tham chiếu tới ở level trung gian kế tiếp. Cuối cùng, cỗ máy truy vấn sẽ tìm đến nút lá cho giá trị 123. Nút lá sẽ chứa toàn bộ dòng dữ liệu hoặc nó chỉ chứa một con trỏ làm tham chiếu dến dòng dữ liệu.
Tiếp theo chúng ta cần define các loại Index
2. Phân loại Index
Về cơ bản index phân thành 2 loại là Clustered Index và Non-Clustered Index
Clustered Index
- Clustered Index lưu trữ và sắp xếp dữ liệu vật lý trong table hoặc view dựa trên các giá trị khóa của chúng. Các cột khóa này được chỉ định trong định nghĩa index. Mỗi table hoặc view chỉ có duy nhất một Clusterd Index vì bản thân các dòng dữ liệu được lưu trữ và sắp xếp theo thứ tự vật lý dựa trên các cột trong loại Index này.
- Khi dữ liệu trong table hoặc view cần được lưu trữ và sắp xếp theo một thứ tự nhất định chính là lúc cần dùng đến Clustered Index. Khi một table có một Clusted Index thì khi đó table được gọi là Clustered Table. Giống như bạn có 1 mục lục, bạn tìm kiếm đến 1 mục và chỉ việc click vào expand thông tin ra là xong, không cần phải đi đâu khác nữa.
Non-Clustered Index
- Non-Clustered có một cấu trúc tách biệt với data row trong table hoặc view. Mỗi một index loại này chứa các giá trị của các cột khóa trong khai báo của index, và mỗi một bản ghi giá trị của key trong index này chứa một con trỏ tới dòng dữ liệu tương ứng của nó trong table.
- Mỗi con trỏ từ một dòng của Non-Clustered index tới một dòng dữ liệu trong table được gọi là “row locator”. Cấu trúc của row locator phụ thuộc vào việc các trang dữ liệu được lưu trong HEAP hay trong một Clustered Table như đã diễn giải ở mục Clustered Index ở trên. Đối với HEAP, row locator là một con trỏ tới dòng dữ liệu, với clustered table, row locator chính là khóa index của clustered index.
Để bổ sung vào 2 kiểu Index cơ sở là Clustered Index và Non Clustered Index, chúng ta có thể mở rộng kiểu Index theo các cách sau đây, tất nhiên các cách dưới đây vẫn thuộc 1 trong 2 kiểu trên.
Composite index
- Là kiểu Index có nhiều hơn 1 cột. Cả hai kiểu index cơ sở là Clustered Index và Non Clustered Index cũng có thể đồng thời là là kiểu Composite index.
Unique Index
- Là kiểu Index dùng để đảm bảo tính duy nhất trong các cột được tạo Index. Nếu Index loại này được tạo dựa trên nhiều cột, thì tính duy nhất của giá trị được tính trên tất cả các cột đó, không chỉ riêng rẽ từng cột. Ví dụ, nếu bạn đã tạo ra một Index trên các cột FirstName và LastName trong một bảng, thì giá trị của 2 cột này kết hợp với nhau phải là duy nhất, nhưng riêng rẽ từng cột thì giá trị vẫn có thể trùng nhau.
- Một Unique Index được tự động tạo ra khi bạn định nghĩa một khóa chính (Primary Key) hoặc một ràng buộc duy nhất (Unique Constraint):
Primary Key
- Khi bạn định nghĩa một ràng buộc khoá chính trên một hoặc nhiều cột của bảng, SQL Server tự động tạo ra một Unique - Clustered Index nếu chưa có một Clustered Index nào tồn tại trên bảng hoặc view.
Unique
- Khi bạn định nghĩa một ràng buộc duy nhất, SQL Server tự động tạo ra một index có các đặc tính là Unique và là Non Clustered Index. Bạn cũng hoàn toàn có thể tạo ra một Unique và là Clustered Index nếu như chưa có một Clustered Index nào được tạo ra trước đó trên bảng.
Covering index
- là một loại chỉ số bao gồm tất cả các cột cần thiết để xử lý một truy vấn cụ thể. Ví dụ, truy vấn của bạn có thể lấy các cột FirstName và LastName từ một bảng, dựa trên một giá trị trong cột ContactID. Từ đó, để tăng tốc độ xử lý câu truy vấn, bạn có thể tạo ra một chỉ số bao gồm tất cả ba cột này.
3. Index Design
Vì Index có thể chiếm nhiều không gian của ổ cứng, do đó không nên triển khai quá nhiều Index nếu như chúng không thực sự cần thiết. Ngoài ra, Index sẽ được tự động cập nhật khi bản thân các dòng dữ liệu được cập nhật, do đó có thể dẫn đến phát sinh thêm chi phí và ảnh hưởng đến hiệu suất của quá trình xử lý dữ liệu. Vì vậy, việc thiết kế Index trong SQL Server cần phải có một số cân nhắc trước khi thực hiện chúng..
Đối với các bảng được cập dữ liệu nhiều và thường xuyên, sử dụng càng ít cột càng tốt trong một Index và không sử dụng Index tràn lan trên các bảng của dữ liệu.
-
Nếu một bảng có khối lượng dữ liệu lớn nhưng tần suất cập nhật dữ liệu thấp, bạn nên sử dụng nhiều Index cần thiết để cải thiện hiệu suất truy vấn, . Tuy nhiên, cần cân nhắc kĩ khi sử dụng Index trên các bảng nhỏ vì cỗ máy truy vấn có thể mất nhiều thời gian và chi phí để tìm kiếm dữ liệu dựa trên các Index hơn là tìm kiếm dữ liệu dựa trên việc thực hiện một thao tác scan table.
-
Đối với Clustered Index, hãy cố gắng giữ cho độ dài của các cột được lập Index càng ngắn càng tốt. Lý tưởng nhất là tạo Clustered Index trên cột có thuộc tính Unique và không cho phép giá trị Null.. Đây là lý do tại sao các khóa chính thường được sử dụng cho Clustered Index của bảng, bên cạnh đó, việc xem xét các truy vấn thường thực hiện trên bảng cũng cần được tính đến khi xác định các cột nên tham gia vào một Clustered Index..
-
Tính duy nhất của các giá trị trong một cột có tác động đến hiệu suất của Index. Nhìn chung, càng nhiều giá trị trùng lặp thì hiệu suất thực thi của Index càng kém. Nói cách khác, tính duy nhất của giá trị trong một cột càng cao thì hiệu suất của Index càng cao. Do đó, nếu xác định các giá trị của một cột nào đó trong một table là duy nhất thì khi đó bạn nên tạo một Unique Index trên cột đó. Giả sử bạn có index là FirstName,
-
Đối với Composite Index, cần phải xem xét thứ tự của các cột trong định nghĩa của Index. Cột nào thường được sử dụng trong các biểu thức so sánh ở mệnh đề WHERE (như WHERE FirstName = 'Charlie') sẽ được liệt kê đầu tiên. Thứ tự của các cột tiếp theo sẽ được liệt kê dựa trên tính duy nhất của các giá trị trong cột, trong đó tính duy nhất của giá trị trong cột càng cao thì càng được liệt kê trước.
-
Bạn cũng có thể tạo Index trên các Computed Column nếu chúng đáp ứng được các yêu cầu nhất định. Ví dụ, biểu thức được sử dụng để tạo ra các giá trị trong cột phải được xác định (có nghĩa là nó luôn luôn trả về kết quả tương tự cho một tập của các giá trị đầu vào).
4. Sử dụng Index trong câu query
Trong một câu lệnh SQL, một điều kiện tìm kiếm ở mệnh đề WHERE được gọi là sargable (viết tắt từ Search Argument-Able) nếu index có thể được sử dụng khi thực hiện câu lệnh (giả sử cột tương ứng có index). Ví dụ, với câu lệnh sau: Trong bảng Customer chúng ta sử dụng index trên CustomerID
SELECT *
FROM dbo.Customer
WHERE CustomerID = 1234
thì điều kiện “CustomerID = 1234″ là sargable, vì nó cho phép index trên cột CustomerID được sử dụng. Vì index giúp tăng hiệu năng của câu lệnh lên rất nhiều, việc viết code để sao cho các điều kiện tìm kiếm trở thành sargable là một mục tiêu rất quan trọng. Một nguyên tắc rất cơ bản trong SQL Server mà bạn có thể áp dụng trong rất nhiều trường hợp, đó là cột cần tìm phải đứng một mình ở một phía của biểu thức tìm kiếm, nói cách khác là không có hàm số hay phép tính toán nào áp dụng trên cột đó. Hãy xem xét hai câu lệnh dưới đây:
USE AdventureWorks
GO
-- câu lệnh 1 (non-sargable)
SELECT * FROM Sales.Individual
WHERE CustomerID+2 = 11002
-- câu lệnh 2 (sargable)
SELECT * FROM Sales.Individual
WHERE CustomerID = 11000
Index đã không được sử dụng vì khi bạn áp dụng một phép tính toán trên cột, hệ thống phải thực hiện tính toán đó trên từng node trên cây index trước khi có thể lấy kết quả để so sánh với giá trị cần tìm. Vì thế nó phải duyệt tuần tự qua từng node thay vì tìm theo kiểu nhị phân (index seek, như với câu lệnh 2). Và đây là các con số thống kê về IO và thời gian thực hiện:
Câu lệnh 1 (non-sargable):
Table 'Individual'. Scan count 1, logical reads 3088, physical reads 35
CPU time = 0 ms, elapsed time = 259 ms.
Câu lệnh 2 (sargable):
Table 'Individual'. Scan count 0, logical reads 3, physical reads 3
CPU time = 0 ms, elapsed time = 19 ms.
Ví dụ, khi cần tìm tất cả các đơn hàng được thực hiện trong ngày 21/08/2009, một cách trực giác có thể bạn nghĩ ngay đến một trong các cách làm sau:
SELECT *
FROM dbo.DonHang
WHERE CONVERT(VARCHAR,OrderDate,103) = '21/08/2009' --cắt bỏ phần thời gian, chỉ giữ lại phần ngày
-- hoặc
SELECT *
FROM dbo.DonHang
WHERE DATEPART(d,OrderDate) =21
AND DATEPART(m,OrderDate)=8
AND DATEPART(YEAR,OrderDate)=2009
Cả hai cách viết trên đều làm mất tác dụng index trên trường OrderDate. Cách viết đúng phải là:
SELECT *
FROM dbo.DonHang
WHERE OrderDate >= '20090821' AND OrderDate < '20090822'
bạn cần tìm tất cả các khách hàng có tên bắt đầu bằng chữ C, như Can, Công, Cường… Các cách viết sau là không sargable:
SELECT *
FROM dbo.Customer
WHERE SUBSTRING(Ten,1,1) = 'C'
--hoặc
SELECT *
FROM dbo.Customer
WHERE LEFT(Ten,1) = 'C'
cách viết sử dụng index:
SELECT *
FROM dbo.Customer
WHERE Ten >= 'C' AND Ten< ‘D’
--hoặc
SELECT *
FROM dbo.Customer
WHERE Ten like 'C%'
Trong quá trình viết bài mình có lấy nội dung từ các trang sau: http://www.sqlviet.com/blog/de-dung-duoc-index-trong-dieu-kien-tim-kiem-cua-cau-lenh http://www.bigdata.com.vn/2013/04/clustered-index-va-non-clustered-index.html
All rights reserved
