SQL Processing, quá trình 1 câu query được thực thi như thế nào
Bài toán
Giả sử chúng ta có 1 bảng employee và chỉ có 1 cột duy nhất là employee_id, nếu muốn thêm 1 triệu rows vào bảng này, ta sẽ có 1 số cách như sau:
Cách 1
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
for (int i = 1; i <= 1000000; i++) {
String sql = "INSERT INTO employees (employee_id) VALUES (" + i + ")";
stmt.executeUpdate(sql);
}
và với cách trên thì sau khi insert 1 triệu rows, thời gian thực hiện là 80s

Cách 2
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
String sql = "INSERT INTO employees (employee_id) VALUES (?)";
PreparedStatement pstmt = conn.prepareStatement(sql);
for (int i = 1; i <= 1000000; i++) {
pstmt.setInt(1, i);
pstmt.addBatch();
}
pstmt.executeBatch();
Sau khi chạy xong, ta thấy thời gian thực thi giảm 1 cách đáng kể từ 80s còn xuống 4s

Để thực sự hiểu được chuyện gì đã xảy ra, hôm nay ta sẽ đào sâu vào SQL Processing, cách mà mọi câu query được thực thi như thế nào
SQL Processing
Giới Thiệu
Hệ thống Quản lý Cơ sở Dữ liệu Quan hệ (RDBMS) như Oracle, MySQL, PostgreSQL và SQL Server được thiết kế để quản lý và truy xuất hiệu quả một lượng lớn dữ liệu. Tuy nhiên, ít người dùng dừng lại để suy nghĩ về những gì xảy ra phía sau khi họ thực hiện một truy vấn. Trong bài viết blog này, chúng ta sẽ khám phá quy trình từng bước mà RDBMS thực hiện để thực thi mỗi truy vấn—bắt đầu từ khoảnh khắc bạn nhấn "Enter" cho đến khi nhận được kết quả.
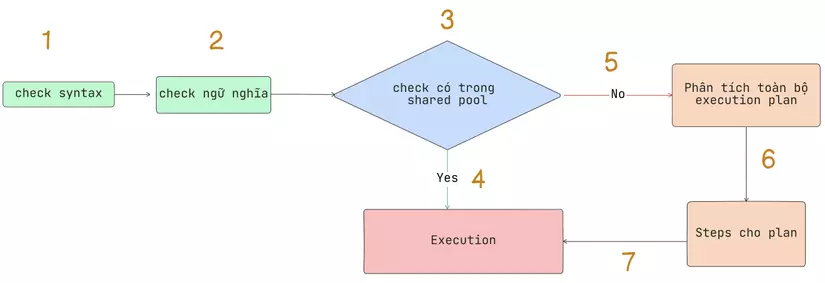
1: Bước đầu tiên là hệ thống sẽ check syntax của câu lệnh
selectt * from employeess
2: Sau khi đã check syntax, bước tiếp đến hệ thống sẽ check xem các bảng, các cột có tồn tại không, user hiện tại có được thao tác với bảng này không,....
3 & 4: Kiểm tra câu lệnh có tồn tại ở trong shared pool hay không, shared pool là 1 nơi để hệ thống có thể cached lại execution plan của các câu query mới được chạy, nếu câu query hiện tại có ở trong shared pool, hệ thống sẽ skip các bước sau và thực thi câu lệnh luôn
5: Ở bước này, các optimizer processor sẽ tính toán ra các cách để có thể thực thi câu query của chúng ta và tìm ra phương án tối ưu nhất. Đây là bước tiêu tốn rất nhiều tài nguyên khi các optimizer phải tính toán liên quan đến rất nhiều thứ nhứ CPU, memory, I/O, statistics của table size, index,...
6: Sau khi tính toán ở bước 5, optimizer sẽ cho ra được 1 phương án tối ưu nhất, gọi là Execution plan của câu query
Quay trở lại với bài toán ở trên, đối với cách 1
for (int i = 1; i <= 1000000; i++) {
String sql = "INSERT INTO employees (employee_id) VALUES (" + i + ")";
stmt.executeUpdate(sql);
}
Với cách code như trên, chúng ta đang vô hình chung thực thi 1 triệu câu query khác nhau, bởi hệ thống chỉ có thể phân biệt được các câu query với nhau ở dạng string
"insert into employees values (1)"
"insert into employees values (2)" ...
và như vậy, ta phải thực hiện bước số 5 đúng 1 triệu lần, khá tệ đúng không 🥲
Đó cũng chính là lý do vì sao ở cách 2, thời gian lại nhanh hơn rất nhiều vì đối với hệ thống, đó chỉ là 1 câu string không thay đổi và nó chỉ cần phân tích chiến lực thực thi 1 lần duy nhất
String sql = "INSERT INTO employees (employee_id) VALUES (?)";
PreparedStatement pstmt = conn.prepareStatement(sql);
for (int i = 1; i <= 1000000; i++) {
pstmt.setInt(1, i);
pstmt.addBatch();
}
Kết bài
Hy vọng qua bài viết này, bạn đã thấy được tầm quan trọng của việc sử dụng variable ở trong các câu query và cũng như quá trình 1 câu query được thực thi như thế nào từ khi ta nhấn nút "Enter" đến lúc kết quả được show ra màn hình 😊
All rights reserved
