[SQL Interview Questions] Một vài câu hỏi phỏng vấn về SQL có thể bạn nên biết!
Bài đăng này đã không được cập nhật trong 3 năm
Trong các cuộc phỏng vấn về lĩnh vực dữ liệu, các câu hỏi về technical chắc chắn là không thể thiếu, và một người làm về dữ liệu ít nhất cần nắm chắc về SQL. Hôm nay, mình muốn chia sẻ cho mọi người một vài câu hỏi mà ta có thể bắt gặp trong những buổi phỏng vấn đó. Đây cũng như là tổng hợp một chút kiến thức về SQL, đôi khi ta có thể quên thì cùng đọc lại để nhớ nhé.

1. JOIN là gì? Liệt kê các loại JOIN.
JOIN là một kiến thức quan trọng trong SQL, nó sẽ dùng nhiều với mục đích lấy thông tin từ nhiều bẳng kết hợp lại với nhau để tạo nên một báo cáo số lượng và ta phải nên hiểu rõ nó.
Khái niệm: JOIN trong cơ sở dữ liệu là phép kết hợp các hàng từ hai hoặc nhiều bảng dựa trên một cột có liên quan giữa chúng (Cột điều kiện JOIN) . Nó cho phép truy vấn dữ liệu từ nhiều bảng trong một câu lệnh bằng cách thiết lập mối quan hệ giữa chúng. Dưới đây là các loại join khác nhau:
-
INNER JOIN: Trả về chỉ các hàng khớp nhau giữa hai bảng dựa trên điều kiện join đã chỉ định. Nó loại bỏ các hàng không có sự khớp trong bảng khác.
-
LEFT JOIN: Trả về tất cả các hàng từ bảng trái và các hàng khớp nhau từ bảng phải dựa trên điều kiện join. Nếu không có sự khớp, nó trả về giá trị NULL cho các cột của bảng phải.
-
RIGHT JOIN: Trả về tất cả các hàng từ bảng phải và các hàng khớp nhau từ bảng trái dựa trên điều kiện join. Nếu không có sự khớp, nó trả về giá trị NULL cho các cột của bảng trái.
-
FULL OUTER JOIN: Trả về tất cả các hàng từ cả hai bảng, gồm các hàng khớp nhau khi có và giá trị NULL khi không có sự khớp. Nó kết hợp kết quả của cả left và right outer join.
-
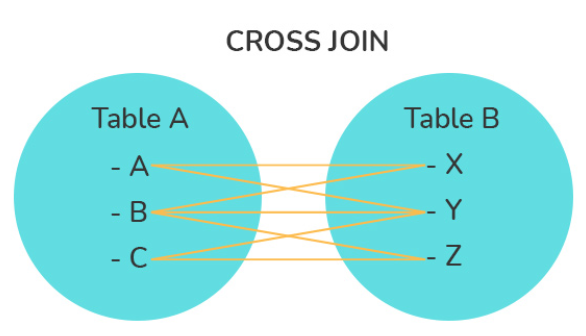
CROSS JOIN: Trả về tích Descartes của hai bảng, có nghĩa là nó kết hợp mỗi hàng từ bảng đầu tiên với mỗi hàng từ bảng thứ hai. Kết quả sẽ chứa tất cả các tổ hợp có thể của các hàng từ cả hai bảng. Một ví dụ: 1 bảng ghi có 10 bản ghi và 1 bản ghi có 5 bản ghi thì kết quả Cross Join sẽ trả về 5x10 = 50 bản ghi.
![center]()
-
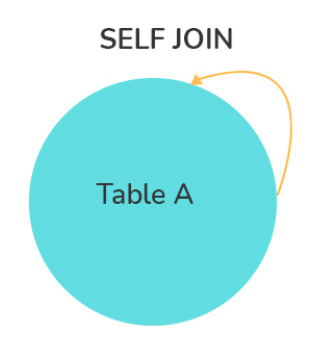
SELF JOIN: Self join là một loại join trong đó một bảng được kết hợp với chính nó bằng cách sử dụng các cột có mối quan hệ. Trong self join, bảng được coi như hai phiên bản khác nhau của chính nó và được đặt tên biệt thự để phân biệt giữa chúng. Self join thường được sử dụng khi bạn muốn so sánh các hàng trong cùng một bảng để tìm các mối quan hệ hoặc thông tin liên quan đến chính bảng đó.
![]()
2. Index là gì? Giải thích các loại index.
Trong cơ sở dữ liệu, Index là một cấu trúc dữ liệu phụ được tạo ra để tăng tốc độ truy vấn và tìm kiếm dữ liệu trong bảng. Nó hoạt động như một bảng bổ sung, chứa một bản sao nhỏ của dữ liệu từ các cột quan trọng trong bảng gốc và sắp xếp nó theo một cách tối ưu để tìm kiếm nhanh hơn.
Khi một câu truy vấn được thực thi, hệ quản trị cơ sở dữ liệu sử dụng index để tìm kiếm thông tin một cách hiệu quả. Thay vì quét toàn bộ dữ liệu trong bảng, index giúp hạn chế số lượng bản ghi cần quét bằng cách xác định chính xác vị trí của dữ liệu cần tìm. Từ đó tối ưu được cách tìm kiếm dữ liệu trong bảng về thời gian và chi phí.
Các loại Index:
B-tree (Balanced Tree) là một loại index phổ biến và được sử dụng rộng rãi trong cơ sở dữ liệu. B-tree là một cây cân bằng với các node chứa khóa được sắp xếp theo thứ tự tăng dần hoặc giảm dần. Cây B-tree được thiết kế để cung cấp tìm kiếm dữ liệu nhanh chóng trong thời gian O(log n), trong đó n là số lượng bản ghi trong cơ sở dữ liệu do các bản ghi được được sắp xếp theo thuật toán B-tree. B-Tree thì sẽ phù hợp cho các bảng có số lượng dữ liệu lớn và trường dùng để đánh index có giá trị unique.
Bitmap index là một loại index trong cơ sở dữ liệu được sử dụng để tăng cường hiệu suất truy vấn cho các trường có số lượng giá trị rời rạc nhỏ. Nó sẽ phù hợp cho những cột thuộc tính về giới tính (male, female) hoặc các cột khác có những giá trị rời rạc với số lượng nhỏ. Bitmap index cho phép truy vấn nhanh chóng bằng cách sử dụng toán tử logic AND, OR, XOR trên các bitmap.
Clustered Index là loại index sắp xếp dữ liệu trong bảng theo thứ tự tăng dần hoặc giảm dần của khóa. Mỗi bảng chỉ có thể có một clustered index. Dữ liệu trong bảng được sắp xếp theo cùng một thứ tự như khóa trong clustered index.
Non-Clustered Index là loại index tạo một cấu trúc dữ liệu bổ sung và giữ một bản sao của các giá trị khóa cùng với con trỏ đến bản gốc. Non-clustered index không sắp xếp dữ liệu trong bảng mà chỉ tạo một cấu trúc tìm kiếm nhanh => đây chính là sự khác biệt giữa Clustered Index và Non-Clustered Index.
Unique Index Giống như non-clustered index, nhưng đảm bảo rằng các giá trị trong index là duy nhất.
3. Khi nào ta cần đánh index trong bảng? Và có khi nào đánh index mà nó không cải thiện hiệu suất truy vấn không?
Khi nào thì ta nên sử dụng index để mang lại hiệu quả, vì nếu tạo index không đúng cách thì cũng để bằng không.
Mục đích tạo ra index để cải thiện hiệu quả trong câu lệnh SELECT:
- Truy vấn SELECT thường xuyên: Nếu câu lệnh SELECT được thực hiện thường xuyên trên một trường cụ thể, việc tạo index trên trường đó có thể cải thiện hiệu suất truy vấn.
- Truy vấn JOIN: Khi sử dụng các câu lệnh JOIN để kết hợp hai hoặc nhiều bảng, tạo index trên các trường được sử dụng trong điều kiện JOIN sẽ giúp tăng tốc độ truy vấn.
- Truy vấn WHERE: Nếu câu lệnh SELECT có điều kiện WHERE dựa trên một trường cụ thể, tạo index trên trường đó sẽ giúp tìm kiếm và lọc dữ liệu nhanh hơn.
Ta nên lưu ý rằng việc tạo index cũng có nhược điểm. Index chiếm không gian lưu trữ và có tác động đến hiệu suất của các thao tác thêm, sửa, xóa dữ liệu (INSERT, UPDATE, DELETE). Khi cần thực hiện các thao tác thêm sửa xóa, ta có thể disable toàn bộ index cho bảng trong quá trình đó để thời gian nhanh nhất, rồi sau đó Rebuild lại. Do đó, cần xem xét và cân nhắc kỹ lưỡng khi tạo index, đảm bảo rằng lợi ích từ việc tăng tốc truy vấn vượt qua hạn chế của việc sử dụng index.
Nếu đã đánh index mà ta không thấy cải thiện hiệu suất truy vấn thì có thể là một số vấn đề sau:
- Lựa chọn sai trường để tạo index: Một trong những nguyên tắc quan trọng khi tạo index là lựa chọn đúng trường. Nếu index được đánh trên một trường không được sử dụng trong câu lệnh truy vấn hoặc không được sử dụng đúng cách, thì index có thể không cung cấp lợi ích nào và không cải thiện hiệu suất truy vấn.
- Do cột đánh index được truy vấn dùng trong 1 biểu thức, index sẽ không được thực hiện trong tình huống này.
- Thay đổi môi trường hoặc yêu cầu: Nếu môi trường cơ sở dữ liệu hoặc yêu cầu của truy vấn thay đổi sau khi index được tạo, có thể index không còn phù hợp hoặc không hiệu quả như trước. Trong trường hợp này, cần xem xét việc tạo lại hoặc điều chỉnh index để đáp ứng yêu cầu mới.
- Thống kê và phân tích dữ liệu: Khi index không được cập nhật thích hợp hoặc thông tin thống kê về dữ liệu không chính xác, nó có thể dẫn đến lựa chọn kế hoạch truy vấn không tối ưu và do đó không cải thiện hiệu suất.
- Cấu trúc câu lệnh truy vấn: Đôi khi, việc tạo index không cải thiện hiệu suất truy vấn do cấu trúc câu lệnh truy vấn không tối ưu. Câu lệnh truy vấn có thể cần được xem xét và tối ưu hóa lại để tận dụng tối đa index đã được tạo.
4. Phân biệt UNION, MINUS và INTERSECT?
UNION: Toán tử UNION được sử dụng để kết hợp các kết quả của hai hoặc nhiều câu lệnh SELECT thành một kết quả duy nhất. Nó loại bỏ các hàng trùng lặp trong kết quả cuối cùng. Các cột trong mỗi câu lệnh SELECT phải có cùng kiểu dữ liệu và theo cùng một thứ tự. Số lượng cột cũng phải khớp.
MINUS: Toán tử MINUS được sử dụng để lấy các hàng xuất hiện trong câu lệnh SELECT đầu tiên nhưng không xuất hiện trong câu lệnh SELECT thứ hai. Nó trả về các hàng duy nhất từ câu lệnh SELECT đầu tiên bằng cách so sánh chúng với các hàng trong câu lệnh SELECT thứ hai.
INTERSECT: Toán tử INTERSECT được sử dụng để lấy các hàng xuất hiện trong cả hai câu lệnh SELECT đầu tiên và thứ hai. Nó trả về các hàng chung giữa hai tập kết quả.
UNION, MINUS và INTERSECT yêu cầu các câu lệnh SELECT có cùng số lượng cột và kiểu dữ liệu tương thích. Ngoài ra, chúng hoạt động trên các hàng duy nhất và thứ tự của các cột trong kết quả được xác định bởi câu lệnh SELECT đầu tiên.
5. Có 2 bảng dữ liệu, cần biết 2 bảng giống nhau ko? Giả sử 2 bảng số lượng lớn.
Ta có nhiều cách để xử lí vấn đề này, ta có thể dùng COUNT(*) hoặc MINUS. Và khi 2 bảng có số lượng các bản ghi là lớn, sử dụng MINUS có thể hiệu quả hơn vì nó chỉ trả về các hàng khác nhau giữa hai bảng thay vì đếm tất cả các hàng.
Cách 1: Sử dụng COUNT(*)
- Đếm số lượng bản ghi trong bảng thứ nhất.
- Đếm số lượng bản ghi trong bảng thứ hai.
- So sánh kết quả. Nếu số lượng bản ghi trong hai bảng bằng nhau, có thể kết luận rằng hai bảng giống nhau.
Cách 2: Sử dụng MINUS
- Thực hiện câu lệnh MINUS với hai câu lệnh SELECT trên hai bảng.
- Nếu kết quả trả về là rỗng (không có hàng nào), có thể kết luận rằng hai bảng giống nhau.
- Nếu kết quả không rỗng, tức là hai bảng khác nhau.
6. Hãy nêu sự khác biệt giữa việc sử dụng DROP và TRUNCATE.
Câu lệnh DROP và TRUNCATE được sử dụng để loại bỏ các đối tượng trong cơ sở dữ liệu, nhưng chúng có một số khác biệt về chức năng và hành vi:
Câu lệnh DROP:
- Câu lệnh DROP là một câu lệnh DDL (Data Definition Language - Ngôn ngữ Định nghĩa Dữ liệu).
- Nó được sử dụng để xóa một cách vĩnh viễn các đối tượng trong cơ sở dữ liệu, chẳng hạn như bảng, view, index, hoặc sequence.
- Khi bạn sử dụng câu lệnh DROP, tất cả dữ liệu, metadata và các đối tượng liên quan của đối tượng bị xóa đều bị xóa.
- Câu lệnh DROP không thể được hoàn tác, vì nó là một hoạt động commit ngầm định không thể hoàn tác.
- Quan trọng là sử dụng câu lệnh DROP cẩn thận, vì nó xóa đối tượng và dữ liệu của nó một cách vĩnh viễn.
Câu lệnh TRUNCATE:
- Câu lệnh TRUNCATE là một câu lệnh DDL (Data Definition Language - Ngôn ngữ Định nghĩa Dữ liệu).
- Nó được sử dụng để xóa tất cả các dòng từ một bảng, hiệu quả đặt lại bảng về trạng thái ban đầu.
- Khi bạn sử dụng câu lệnh TRUNCATE, cấu trúc bảng, ràng buộc và các chỉ mục được bảo tồn, nhưng tất cả dữ liệu trong bảng đều bị xóa.
Ta có thể thấy một số khác biệt rõ ràng kể trên, câu lệnh DROP được sử dụng để xóa một cách vĩnh viễn các đối tượng cơ sở dữ liệu, trong khi câu lệnh TRUNCATE được sử dụng để xóa tất cả các dòng từ một bảng trong khi bảo tồn cấu trúc của bảng. Vậy nên dùng TRUNCATE có thể là an toàn hơn khi muốn xóa dữ liệu, nhưng nó vẫn tùy thuộc vào yêu cầu cụ thể.
7. Hãy nêu sự khác biệt giữa việc sử dụng DELETE và TRUNCATE.
Đối với câu lệnh DELETE:
- Nó được sử dụng để xóa các dòng dữ liệu cụ thể từ một bảng dựa trên một điều kiện hoặc tiêu chí được chỉ định.
- Câu lệnh DELETE chậm hơn so với TRUNCATE, đặc biệt khi xóa một số lượng lớn các dòng, vì nó tạo ra các transaction log và có thể gây thêm chi phí.
- Nó có thể được rollback bằng cách sử dụng câu lệnh ROLLBACK nếu được thực hiện trong một giao dịch.
Đối với câu lệnh TRUNCATE:
- Nó được sử dụng để xóa tất cả các dòng từ một bảng, hiệu quả đặt lại bảng về trạng thái ban đầu.
- Câu lệnh TRUNCATE nhanh hơn so với DELETE, đặc biệt khi xóa một số lượng lớn các dòng, vì nó không tạo ra transaction log và không phải ghi lại từng dòng riêng lẻ.
- Nó không thể được rollback, vì đây là một hoạt động commit ngầm định không thể hoàn tác.
- Câu lệnh TRUNCATE không sử dụng mệnh đề WHERE, vì nó xóa tất cả các dòng từ bảng.
Kết bài
Trên đây là một vài câu hỏi về kiến thức SQL các bạn có thể tham khảo để phục vụ bổ sung kiến thức cũng như chuẩn bị cho các cuộc phỏng vấn về nghề nghiệp liên quan đến dữ liệu trong cơ sở dữ liệu sử dụng SQL. Nếu các bạn muốn biết nhiều hơn các câu hỏi, có thể tham khảo link các câu hỏi mình để bên dưới nhé.
Cảm ơn các bạn đã đọc bài viết.
Reference
- SQL Interview Questions (https://www.interviewbit.com/sql-interview-questions/#sql)
- Top 115 SQL Interview Questions You Must Prepare In 2023 (https://www.edureka.co/blog/interview-questions/sql-interview-questions)
All rights reserved
