Spark streaming với Kafka
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu chung về Spark
Trước khi Spark ra đời, Hadoop là một tool mạnh mẽ và phổ biến, tuy nhiên Hadoop có những hạn chế nhất định và Spark ra đời để cải thiện các hạn chế đó. Ví dụ như việc Machine learning phát triển dẫn tới việc chạy thuật toán ML trên Hadoop rất mất thời gian vì các thuật toán ML đa số có tính chất iterative, nên việc sau mỗi lần lặp dữ liệu được lưu tại một bộ nhớ và phải đọc lại để làm đầu vào cho iteration tiếp theo rất tốn thời gian.
Spark bao gồm 5 thành phần chính:
- Spark core: nền tảng cốt lõi của Spark, thực hiện các công việc như quản lý bộ nhớ, I/O operation, scheduling, v.v. Các thành phần khác muốn hoạt động đều phải thông qua Spark core.
- Spark SQL: một module tập trung vào việc xử lý dữ liệu có cấu trúc.
- Spark streaming: thành phần hỗ trợ xử lý dữ liệu streaming, input có thể là từ các nguồn như Kafka, Flume, v.v.
- Spark MLlib: thư viện ML được tích hợp trong Spark
- Spark GraphX: cung cấp các API dành cho tính toán đồ thị
Giới thiệu tổng quan về Spark tới đây thôi, và trong bài viết này, mình sẽ đưa ra cách cài đặt cơ bản của mình cho Spark streaming với dữ liệu đầu vào từ Kafka (Mình đã viết 1 bài về cài đặt Kafka multi broker trên Docker tại đây, ae nào chưa biết thì tham khảo qua nhé 😄).
Cài đặt Spark standalone
Để cho đơn giản, thì mình sẽ cài Spark standalone thẳng trên máy luôn (mình dùng Ubuntu nên sẽ viết theo cách cài đặt cho Ubuntu, ae nào dùng OS khác thì có thể tham khảo thêm trên mạng vì có rất nhiều rồi 😗).
Yêu cầu tiên quyết để cài Spark trên máy là ae cần cài JDK, Scala và Python trước. Để cài JDK ae có thể xem tại document của Ubuntu tại đây, nhanh gọn và dễ hiểu vl. Còn Scala thì cũng tại document của nó ở đây luôn nhé, cũng nhanh gọn và dễ hiểu vler. Còn về Python, ae dùng Ubuntu chỉ cần mở terminal lên chạy sudo apt install python3 là ngon rồi.
Sau đó thì mng vào đây để tải Spark về, chọn release và package type sao cho phù hợp với máy của mình. Nhớ chú ý tới phần version của Scala nhé.
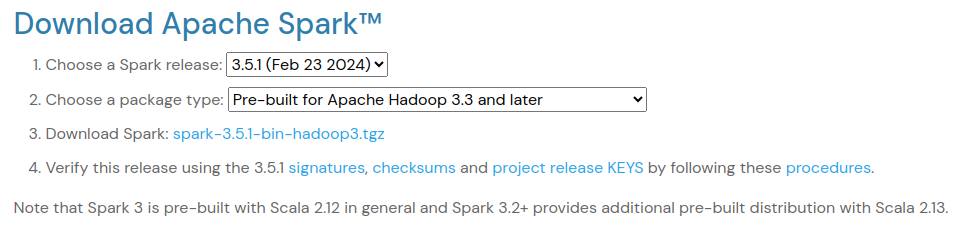 Sau khi đã tải, giải nén nó bằng command dưới đây. Ae có thể chọn 1 directory mình muốn nhé, còn command ở dưới sẽ giải nén ở ngay directory đang đứng. Để giải nén tới dir khác thì ae thêm
Sau khi đã tải, giải nén nó bằng command dưới đây. Ae có thể chọn 1 directory mình muốn nhé, còn command ở dưới sẽ giải nén ở ngay directory đang đứng. Để giải nén tới dir khác thì ae thêm -C /target/directory vào cuối command.
tar xvzf <file_name>.tgz
Sau khi đã giải nén xong, mình cần cấu hình môi trường cho Spark. Ae vào file .profile ở home directory
sudo nano ~/.profile
và thêm 3 dòng này vào cuối
export SPARK_HOME=<absolute_spark_dir>
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3
và thế là xong rồi. Sau đó chạy vào $SPARK_HOME và chạy Spark lên thôi
$SPARK_HOME/sbin/start-all.sh
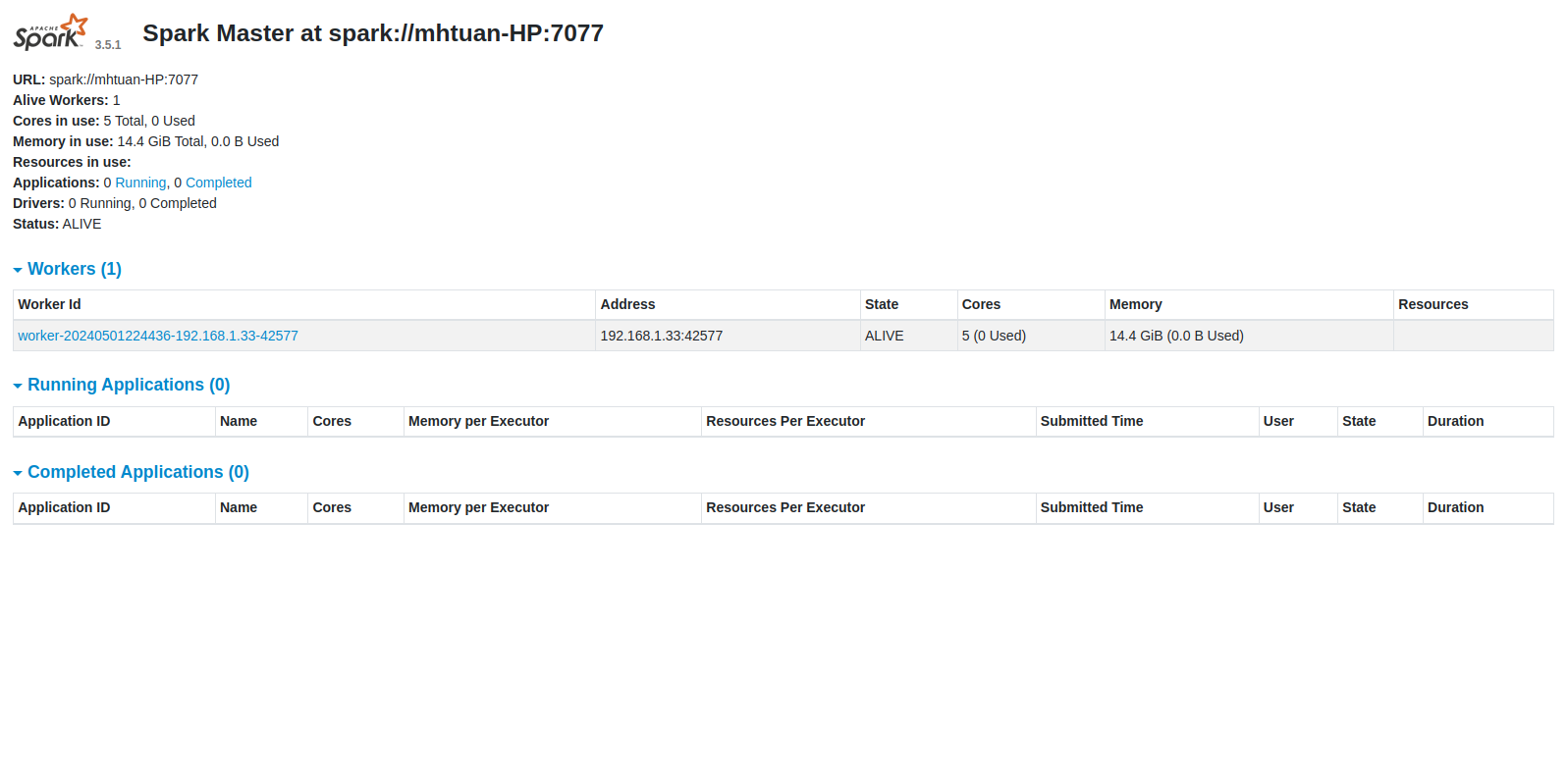
Khi nó chạy xong rồi, ae lên http://localhost:8080/ là web UI của nó và thấy giao diện trông như dưới này là ngon zai 😄.
Spark streaming với Kafka
Tạo 1 folder và file code rồi phệt thôi. Trong ví dụ này, mình sẽ demo cơ bản 1 luồng stream từ Kafka -> Spark streaming -> Clickhouse (Lý do Clickhouse vì mình đang làm dở nên dùng làm ví dụ luôn 😁, ae nào chưa biết Clickhouse là cái gì thì có thể đọc tại đây).
Đầu tiên mình cần xác định các biến môi trường, ví dụ như host, port của các broker Kafka chẳng hạn. Mình sẽ để tất cả các biến đó trong 1 file .env, định dạng như sau
CLICKHOUSE_HOST=127.0.0.1
CLICKHOUSE_PORT=9000
CLICKHOUSE_USER=default
CLICKHOUSE_PASSWORD=tuandeptrai
KAFKA_HOST=localhost
KAFKA_BROKER1_PORT=9091
KAFKA_BROKER2_PORT=9092
KAFKA_BROKER3_PORT=9093
Tiếp tới, mình đi vào coding thôi. Library cần thiết để code là pyspark, ae có thể install qua command pip install pyspark. Đầu tiên là import các dependency cần thiết và load các biến từ .env
from pyspark.sql import SparkSession
from pyspark.sql.types import StringType, StructField, StructType, IntegerType
from pyspark.sql.functions import from_json,current_timestamp
import os
from dotenv import load_dotenv
load_dotenv()
CLICKHOUSE_HOST = os.getenv('CLICKHOUSE_HOST')
CLICKHOUSE_PORT = os.getenv('CLICKHOUSE_PORT')
CLICKHOUSE_USER = os.getenv('CLICKHOUSE_USER')
CLICKHOUSE_PASSWORD = os.getenv('CLICKHOUSE_PASSWORD')
KAFKA_HOST = os.getenv('KAFKA_HOST')
KAFKA_BROKER1_PORT = os.getenv('KAFKA_BROKER1_PORT')
KAFKA_BROKER2_PORT = os.getenv('KAFKA_BROKER2_PORT')
KAFKA_BROKER3_PORT = os.getenv('KAFKA_BROKER3_PORT')
Tiếp theo, mình define schema cho table mình muốn đẩy vào sử dụng StructType của spark.sql. Mỗi column sẽ được định nghĩa bởi StructField với 2 param bắt buộc là name và dataType, mình dùng thêm 1 param optional thứ 3 là nullable
json_schema = StructType([
StructField('sslsni', StringType(), True),
StructField('subscriberid', StringType(), True),
StructField('hour_key', IntegerType(), True),
StructField('count', IntegerType(), True),
StructField('up', IntegerType(), True),
StructField('down', IntegerType(), True)
])
Tiếp tới, ae khởi tạo Spark session và định nghĩa những cấu hình cần thiết cho nó. Phần master thì ae lên web UI và lấy cái URL ngay dưới cái logo Spark nhé.
spark = SparkSession.builder \
.appName("Streaming from Kafka") \
.config("spark.streaming.stopGracefullyOnShutdown", True) \
.config('spark.jars.packages', 'org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1') \
.config("spark.sql.shuffle.partitions", 4) \
.master("spark://mhtuan-HP:7077") \
.getOrCreate()
Tiếp theo, dùng con spark để subscribe 1 topic nhất định từ con kafka để consume message. Sau đó mình sẽ dùng spark sql để xử lý data mới consume được.
df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", f"{KAFKA_HOST}:{KAFKA_BROKER1_PORT},{KAFKA_HOST}:{KAFKA_BROKER2_PORT},{KAFKA_HOST}:{KAFKA_BROKER3_PORT}") \
.option("failOnDataLoss", "false") \
.option("subscribe", "test-url-1204") \
.load()
json_df = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING) as msg_value")
json_expanded_df = json_df.withColumn("msg_value", from_json(json_df["msg_value"], json_schema)).select("msg_value.*")
exploded_df = json_expanded_df.select("sslsni", "subscriberid", "hour_key", "count", "up", "down")
df_with_date = exploded_df.withColumn("inserted_time", current_timestamp())
Cuối cùng mình sẽ insert data vào con Clickhouse. Hàm foreach_batch_function để execute và đẩy data vào Clickhouse sau mỗi micro batch data được consume. Về cơ bản, con spark streaming sẽ gom các batch nhỏ data được consume từ kafka và đẩy vào Clickhouse theo từng batch, chứ không phải cứ nhận được 1 message là thực hiện insert 1 lần.
def foreach_batch_function(df, epoch_id):
df.write \
.format("jdbc") \
.mode("append") \
.option("driver", "com.github.housepower.jdbc.ClickHouseDriver") \
.option("url", "jdbc:clickhouse://" + CLICKHOUSE_HOST + ":" + CLICKHOUSE_PORT) \
.option("user", CLICKHOUSE_USER) \
.option("password", CLICKHOUSE_PASSWORD) \
.option("dbtable", "default.raw_url") \
.save()
writing_df = df_with_date \
.writeStream \
.foreachBatch(foreach_batch_function) \
.start()
writing_df.awaitTermination()
Vậy là xong phần code rồi 😄. Để chạy, mình dùng spark submit với command như sau
spark-submit --packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.5.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1,com.github.housepower:clickhouse-integration-spark_2.12:2.7.1,com.github.housepower:clickhouse-native-jdbc-shaded:2.7.1 streaming.py
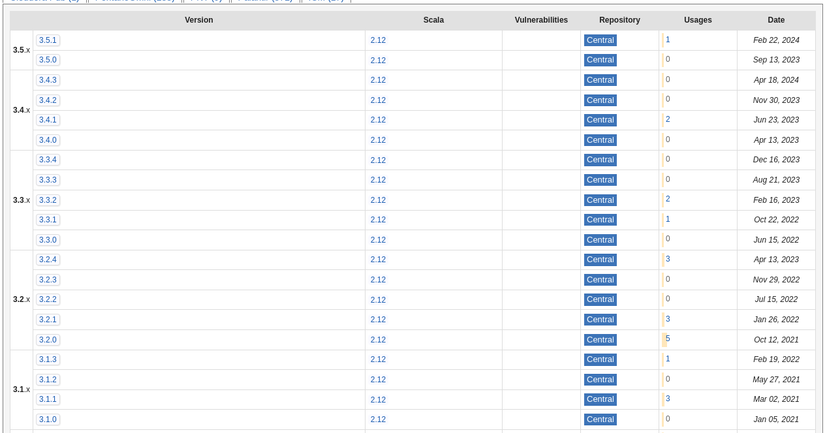
Các package ở trong command là các package cần thiết để chạy. Lưu ý là ae cần check lại các package này xem có khớp version với Scala và Java ở máy của ae không. Ví dụ, với package org.apache.spark:spark-streaming-kafka-0-10_2.12:3.5.1, ae chỉ cần copy paste vào google, rồi vào maven để check, ví dụ như trang này. Có một cột là version của dependency và 1 cột là Scala, cần để ý xem version của Scala có match với version Scala trên máy cài đặt không.
Tới đây là hết rồi, cũng không quá phức tạp để dựng 1 con spark streaming cơ bản nhỉ 😁. Cảm ơn ae đã đọc, ae có câu hỏi gì thì comment nhá, nếu mình biết mình sẽ support 😙
All rights reserved
