Spark Streaming trong Apache Spark
Bài đăng này đã không được cập nhật trong 2 năm
Spark Streaming là một thành phần quan trọng của Apache Spark, cho phép xử lý dữ liệu trực tiếp và liên tục từ nhiều nguồn khác nhau như Kafka, Flume, Kinesis, hoặc socket TCP/IP.
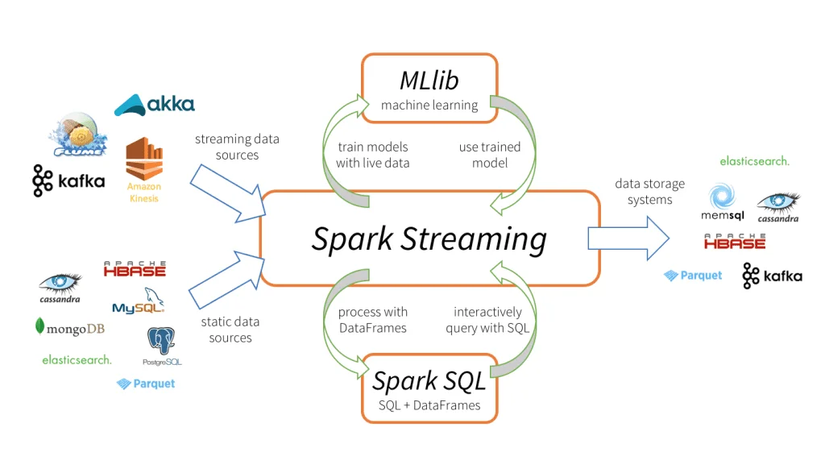
Dưới đây là một số điểm quan trọng cần hiểu về Spark Streaming:
1. Xử lý dữ liệu liên tục:
Spark Streaming cho phép xử lý dữ liệu liên tục, tức là dữ liệu được xử lý và phân tích ngay khi nó được sinh ra. Điều này rất hữu ích cho các ứng dụng yêu cầu phản hồi thời gian thực hoặc phân tích dữ liệu liên tục như giao dịch tài chính, giám sát hệ thống, và xử lý luồng truyền thông xã hội.
Để minh họa cách xử lý dữ liệu liên tục bằng Spark Streaming, hãy xem xét một ví dụ đơn giản về việc đếm từ trong dữ liệu nhận được từ một nguồn text liên tục.
- Khởi tạo SparkSession và SparkContext:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("StreamingWordCount") \
.getOrCreate()
sc = spark.sparkContext
- Tạo DStream từ nguồn dữ liệu:
Trong ví dụ này, chúng ta sẽ sử dụng một nguồn dữ liệu socket TCP/IP. Điều này cho phép chúng ta kết nối với một cổng trên máy cục bộ để nhận dữ liệu.
from pyspark.streaming import StreamingContext
# Tạo một StreamingContext với khoảng thời gian nhỏ nhất 1 giây
ssc = StreamingContext(sc, 1)
# Kết nối đến cổng localhost 9999 để nhận dữ liệu
lines = ssc.socketTextStream("localhost", 9999)
- Xử lý dữ liệu:
# Phân tách các từ từ dòng dữ liệu
words = lines.flatMap(lambda line: line.split(" "))
# Đếm số lượng từ
word_counts = words.map(lambda word: (word, 1)).reduceByKey(lambda x, y: x + y)
- In kết quả:
word_counts.pprint()
# Khởi động quá trình xử lý dữ liệu liên tục
ssc.start()
# Đợi quá trình kết thúc
ssc.awaitTermination()
- Gửi dữ liệu đến cổng 9999:
Sử dụng terminal để gửi dữ liệu đến cổng 9999:
nc -lk 9999
- Kết quả:
Khi bạn nhập các câu văn vào terminal, Spark Streaming sẽ đếm số lần xuất hiện của mỗi từ và in kết quả lên màn hình mỗi giây.
Ví dụ:
$ nc -lk 9999
hello world
hello spark
hello streaming
Kết quả trên màn hình của Spark Streaming sẽ là:
-------------------------------------------
Time: ...
-------------------------------------------
('world', 1)
('hello', 1)
('hello', 2)
('spark', 1)
('hello', 3)
('streaming', 1)
Đây là một ví dụ cụ thể về cách xử lý dữ liệu liên tục bằng Spark Streaming để đếm số từ trong dữ liệu đầu vào từ một nguồn text liên tục.
2. Micro-batch Processing:
Spark Streaming sử dụng mô hình micro-batch processing, trong đó dữ liệu đến trong một khoảnh khắc nhất định được nhóm lại thành các micro-batch và xử lý bằng các quá trình xử lý tương tự như xử lý dữ liệu tĩnh trong Apache Spark.
Để minh họa cách hoạt động của micro-batch processing trong Spark Streaming, hãy xem xét một ví dụ cụ thể về xử lý dữ liệu từ một nguồn Kafka.
Giả sử chúng ta có một chuỗi dữ liệu nhận được từ một topic Kafka, trong đó mỗi tin nhắn đại diện cho một sự kiện được ghi lại từ các thiết bị cảm biến. Dữ liệu này liên tục trôi vào Kafka và chúng ta muốn sử dụng Spark Streaming để phân tích dữ liệu này theo các micro-batch.
Dưới đây là một ví dụ cụ thể về cách xử lý dữ liệu từ Kafka bằng cách sử dụng micro-batch processing trong Spark Streaming:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
# Khởi tạo SparkContext
sc = SparkContext("local[2]", "KafkaStreamProcessing")
# Khởi tạo StreamingContext với khoảng thời gian micro-batch là 5 giây
ssc = StreamingContext(sc, 5)
# Khởi tạo Kafka Stream để đọc dữ liệu từ Kafka
kafka_params = {
"bootstrap.servers": "localhost:9092",
"auto.offset.reset": "latest",
"group.id": "spark-streaming-group"
}
kafka_stream = KafkaUtils.createDirectStream(ssc, ["sensor-events"], kafka_params)
# Xử lý dữ liệu trong mỗi micro-batch
def process_batch(rdd):
# Thực hiện xử lý dữ liệu trong mỗi RDD
# Ví dụ: tính tổng giá trị của dữ liệu cảm biến trong mỗi micro-batch
total_value = rdd.map(lambda x: float(x[1])).reduce(lambda x, y: x + y)
print("Total value in this batch:", total_value)
# Ánh xạ mỗi micro-batch vào hàm process_batch
kafka_stream.foreachRDD(process_batch)
# Bắt đầu quá trình xử lý dữ liệu
ssc.start()
ssc.awaitTermination()
Trong ví dụ này:
- Chúng ta khởi tạo một SparkContext và một StreamingContext với khoảng thời gian micro-batch là 5 giây.
- Sử dụng KafkaUtils để tạo một Kafka Stream để đọc dữ liệu từ một topic Kafka gọi là "sensor-events".
- Mỗi micro-batch từ Kafka Stream được xử lý trong hàm
process_batch, trong đó chúng ta có thể thực hiện các phương thức xử lý dữ liệu tùy ý. Trong ví dụ này, chúng ta tính tổng giá trị của dữ liệu cảm biến trong mỗi micro-batch.- Cuối cùng, chúng ta bắt đầu quá trình xử lý dữ liệu bằng cách gọi
ssc.start()và chờ cho quá trình kết thúc bằng cách gọissc.awaitTermination().
Đây là một ví dụ cụ thể về cách sử dụng micro-batch processing trong Spark Streaming để xử lý dữ liệu từ Kafka.
3. DStream:
DStream (Discretized Stream) là một thành phần quan trọng của Spark Streaming, là một chuỗi liên tục các RDDs (Resilient Distributed Datasets) được tạo ra bởi việc chia dữ liệu nhận được thành các micro-batch. Dưới đây là một ví dụ cụ thể về cách sử dụng DStream để xử lý dữ liệu liên tục trong Apache Spark:
Giả sử chúng ta muốn tính tổng của các số được gửi đến từ một nguồn dữ liệu liên tục, ví dụ như một cổng TCP/IP hoặc Kafka. Dưới đây là cách bạn có thể sử dụng DStream để thực hiện điều này:
from pyspark import SparkConf, SparkContext
from pyspark.streaming import StreamingContext
# Khởi tạo SparkConf và SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("DStream Example")
sc = SparkContext(conf=conf)
# Khởi tạo StreamingContext với batch interval là 1 giây
ssc = StreamingContext(sc, 1)
# Tạo DStream từ nguồn dữ liệu (ví dụ: cổng TCP/IP)
lines = ssc.socketTextStream("localhost", 9999)
# Xử lý từng dòng dữ liệu trong DStream
numbers = lines.flatMap(lambda line: line.split(" ")).map(lambda x: int(x))
# Tính tổng của các số trong mỗi batch
sums = numbers.reduce(lambda a, b: a + b)
# In kết quả tổng của mỗi batch
sums.pprint()
# Khởi chạy Spark Streaming
ssc.start()
# Chờ cho quá trình kết thúc
ssc.awaitTermination()
Trong ví dụ này:
- Chúng ta khởi tạo một
StreamingContextvớiSparkContextđã được khởi tạo trước đó, với batch interval là 1 giây.- Chúng ta tạo một
DStreamtừ một nguồn dữ liệu (ở đây là một cổng TCP/IP tại localhost:9999).- Dữ liệu được phân tách thành các số và được chuyển đổi thành RDDs.
- Chúng ta tính tổng của các số trong mỗi batch bằng cách sử dụng phương thức
reduce().- Kết quả tổng của mỗi batch được in ra màn hình bằng phương thức
pprint().
Đây là một ví dụ cụ thể về cách sử dụng DStream để xử lý dữ liệu liên tục trong Apache Spark.
4. Tích hợp dễ dàng:
Spark Streaming tích hợp chặt chẽ với các thành phần khác của hệ sinh thái Spark như Spark SQL, MLlib và GraphX, cho phép bạn kết hợp các phương tiện phân tích dữ liệu khác nhau để thực hiện các nhiệm vụ phức tạp trên dữ liệu liên tục.
5. Các nguồn dữ liệu đa dạng:
Spark Streaming hỗ trợ nhiều nguồn dữ liệu đầu vào như Kafka, Flume, Kinesis, và socket TCP/IP. Điều này cho phép bạn kết nối và xử lý dữ liệu từ nhiều nguồn khác nhau một cách linh hoạt.
6. Tích hợp với dữ liệu tĩnh:
Spark Streaming cũng tích hợp chặt chẽ với dữ liệu tĩnh trong Apache Spark, cho phép bạn kết hợp xử lý dữ liệu liên tục và dữ liệu tĩnh trong cùng một ứng dụng.
Tóm lại, Spark Streaming là một công cụ mạnh mẽ cho việc xử lý và phân tích dữ liệu liên tục trong Apache Spark, cho phép bạn xử lý dữ liệu từ nhiều nguồn khác nhau một cách linh hoạt và hiệu quả. Điều này làm cho việc xây dựng các ứng dụng dữ liệu liên tục trong lĩnh vực Big Data trở nên dễ dàng và hiệu quả hơn.
All rights reserved
