So sánh performace giữa EXISTS vs IN vs JOIN
Bài đăng này đã không được cập nhật trong 6 năm
1. Mở đầu:
Khi bạn sử dụng join kết quả search của bạn sẽ không giống với mệnh đề In và Exists.
Chúng ta sẽ đến với các trường hợp cụ thể để thấy rõ hơn.
Chúng ta sẽ sử dụng database AdventureWorks2012.
Chúng ta sẽ sử dụng script để tạo 2 table BigTable và SmallTable.
Trong đó SmallTable là sub table của BigTable và có column ID sẽ ứng với các trường hợp.
2. EXISTS vs IN vs JOIN with PRIMARY KEY columns:
Scipt tạo và insert data và table với trường ID là primary key
USE AdventureWorks2012
GO
SET NOCOUNT ON
GO
CREATE TABLE BigTable (
ID INT NOT NULL,
FirstName NVARCHAR(100),
LastName NVARCHAR(100),
City NVARCHAR(100),
PRIMARY KEY (ID)
)
GO
INSERT INTO BigTable (ID,FirstName,LastName,City)
SELECT TOP 1000000 ROW_NUMBER() OVER (ORDER BY a.name) RowID,
N'NamA',
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)%2 = 1 THEN N'NamB'
ELSE N'NamC' END,
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 1 THEN N'Hà Nội'
WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 5 THEN N'Hải Phòng'
WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 3 THEN N'Huế'
WHEN ROW_NUMBER() OVER (ORDER BY a.name)%427 = 1 THEN N'Đà Nẵng'
ELSE 'Hồ Chí Minh' END
FROM sys.all_objects a
CROSS JOIN sys.all_objects b
GO
CREATE TABLE SmallTable (ID INT NOT NULL,
FirstName NVARCHAR(100),
LastName NVARCHAR(100),
City NVARCHAR(100),
PRIMARY KEY (ID)
)
GO
INSERT INTO SmallTable (ID,FirstName,LastName,City)
SELECT TOP(100000) * FROM BigTable ORDER BY ID
Và bây giờ sử dụng Include Actual Execution Plan 3 truy vấn sau để so sánh.
SET STATISTICS IO ON
SET NOCOUNT OFF
GO
print'Using IN Clause'
SELECT ID, City
FROM BigTable
WHERE ID IN (SELECT ID FROM SmallTable)
GO
print 'Using Exists Clause'
SELECT ID, City
FROM BigTable
WHERE EXISTS
(SELECT ID
FROM SmallTable
WHERE SmallTable.ID = BigTable.ID)
GO
Print 'Using JOIN'
SELECT bt.ID, bt.City
FROM BigTable bt
INNER JOIN SmallTable st ON bt.ID = st.ID
Kết quả nhận được như sau:

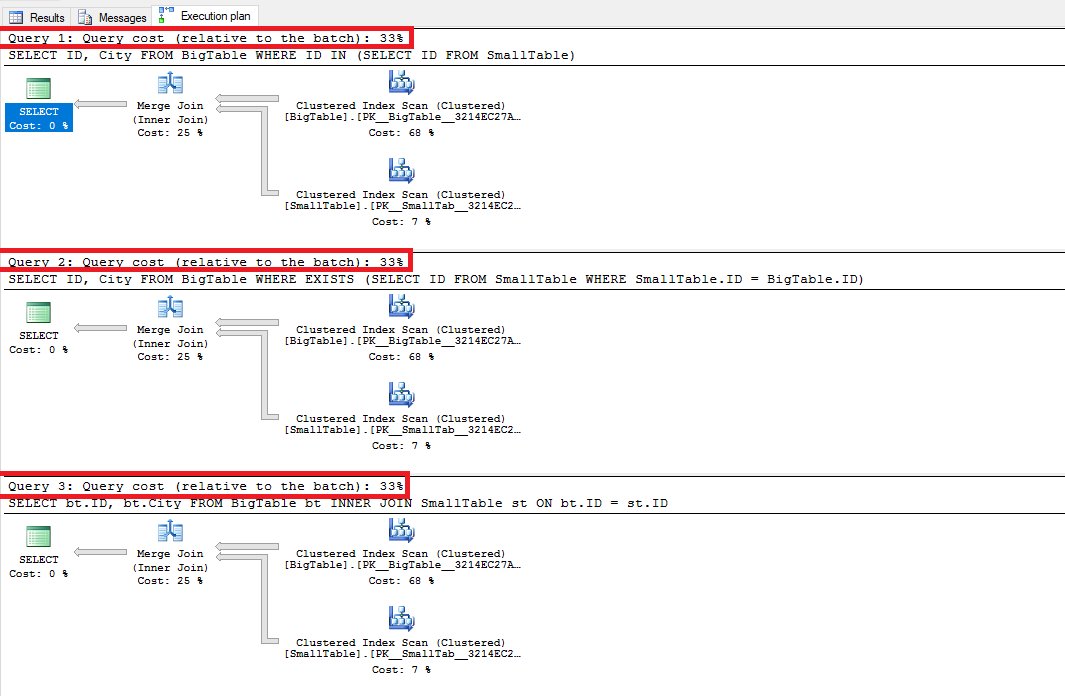
Ta có thể thấy trong trường hợp này EXISTS vs IN vs JOIN giống hết nhau về kết quả truy vấn và cost query lẫn execution plans.
3. NOT EXISTS vs NOT IN vs LEFT JOIN with PRIMARY KEY columns:
Bây giờ chúng ta sẽ so sánh trường hợp này bằng Script như sau:
SET STATISTICS IO ON
SET NOCOUNT OFF
print'Using NOT IN Clause'
SELECT ID, City
FROM BigTable
WHERE ID NOT IN
(SELECT ID
FROM SmallTable)
GO
print 'Using NOT Exists Clause'
SELECT ID, City
FROM BigTable
WHERE NOT EXISTS
(SELECT ID
FROM SmallTable
WHERE SmallTable.ID = BigTable.ID)
GO
Print 'Using LEFT JOIN'
SELECT bt.ID, bt.City
FROM BigTable bt
LEFT JOIN SmallTable st ON bt.ID = st.ID
WHERE st.ID IS NULL
Kết quả nhận được như sau:

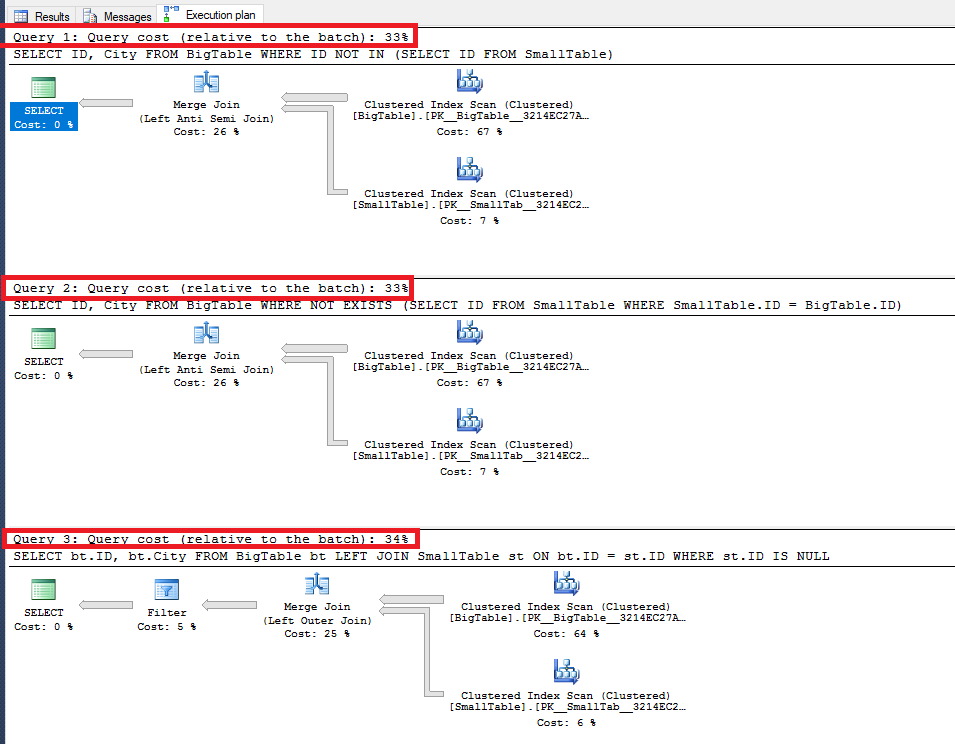
Trong trường hợp này kết quả search của 3 trường hợp vẫn giống nhau, Có sự khác biệt về plan khi IN và EXISTS đã lọc trước khi Merge Join, còn LEFT JOIN thì Merge Join xong mới Filter kết quả.Nhưng Query cost thì không có lệch nhiều ở đây.
4.EXISTS vs IN vs JOIN with NOT nullable columns:
Script vẫn tạo 2 table BigTable và SmallTable nhưng chỉ set cho column ID là NOT NULL chứ không phải là PRIMARY KEY. Vì column ID đã không set là PRIMARY KEY nên ta sẽ execute thêm 1 lần insert và table SmallTable để tạo ra giá trị trùng lặp.
INSERT INTO SmallTable (ID,FirstName,LastName,City)
SELECT TOP(100000) * FROM BigTable ORDER BY ID
Sau đó chúng ta tạo index cho 2 table này:
CREATE CLUSTERED INDEX IX_BigTable_ID
ON BigTable(ID)
GO
CREATE CLUSTERED INDEX IX_SmallTable_ID
ON SmallTable(ID)
Sau đó chúng ta sẽ thực hiện Execute Plan cho 3 câu truy vấn như trường hợp 1.
SET STATISTICS IO ON
SET NOCOUNT OFF
GO
print'Using IN Clause'
SELECT ID, City
FROM BigTable
WHERE ID IN (SELECT ID FROM SmallTable)
GO
print 'Using Exists Clause'
SELECT ID, City
FROM BigTable
WHERE EXISTS
(SELECT ID
FROM SmallTable
WHERE SmallTable.ID = BigTable.ID)
GO
Print 'Using JOIN'
SELECT bt.ID, bt.City
FROM BigTable bt
INNER JOIN SmallTable st ON bt.ID = st.ID
Bạn sẽ nhận ra sự khác biệt kết quả trong trương hợp này.

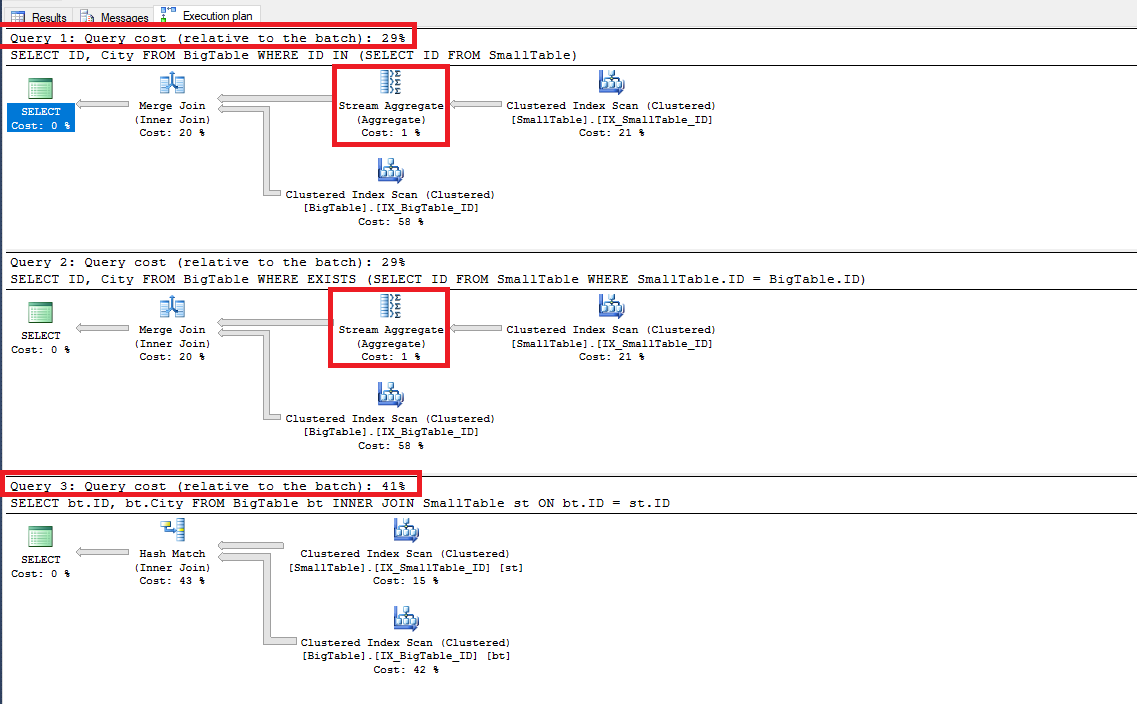
Kết quả giữa IN và EXISTS thì giống hệt nhau, nhưng INNER JOIN thì khác cả về kết quả trả về và Query Cost. Như ở trên ta có thể thấy IN và EXISTS đã có bước lọc các record trùng lặp trước nên kết quả trả về chi 100000 record. Trong khi JOIN lại không có bước lặp trùng lặp này nên kết quả search Là 200000. Ngoài ra vì trùng lặp dữ liệu nên dẫn đến mất đi tác dụng của việc đánh index table, SQl Server phải sử dụng Hash Match thay vì Merge Join làm cho Query Cost nhiều hơn. Chúng ta có thể edit lại câu Script INNER JOIN như sau:
Print 'Using JOIN'
SELECT bt.ID, bt.City
FROM BigTable bt
INNER JOIN (SELECT DISTINCT ID FROM SmallTable) st ON bt.ID = st.ID
Trong các trường hợp khác như : NOT EXISTS vs NOT IN vs JOIN with NOT NULLable columns, EXISTS vs IN vs JOIN with NULLable columns Cũng sẽ có kết quả như trường hợp này. Nhưng trường hợp dưới đây có sự khác biệt
5.NOT EXISTS vs NOT IN vs LEFT JOIN with nullable columns:
Script vẫn tạo 2 table BigTable và SmallTable nhưng set cho column ID là NULL. Sau đó chúng ta vẫn tạo index cho 2 table này. Chúng ta thực hiện execute Plan cho 3 truy vấn sau :
SET STATISTICS IO ON
SET NOCOUNT OFF
print'Using NOT IN Clause'
SELECT ID, City
FROM BigTable
WHERE ID NOT IN
(SELECT ID
FROM SmallTable)
GO
print 'Using NOT Exists Clause'
SELECT ID, City
FROM BigTable
WHERE NOT EXISTS
(SELECT ID
FROM SmallTable
WHERE SmallTable.ID = BigTable.ID)
GO
Print 'Using LEFT JOIN'
SELECT bt.ID, bt.City
FROM BigTable bt
LEFT JOIN (SELECT DISTINCT ID FROM SmallTable) st ON bt.ID = st.ID
WHERE st.ID IS NULL
Kết quả Execution Plan như sau:
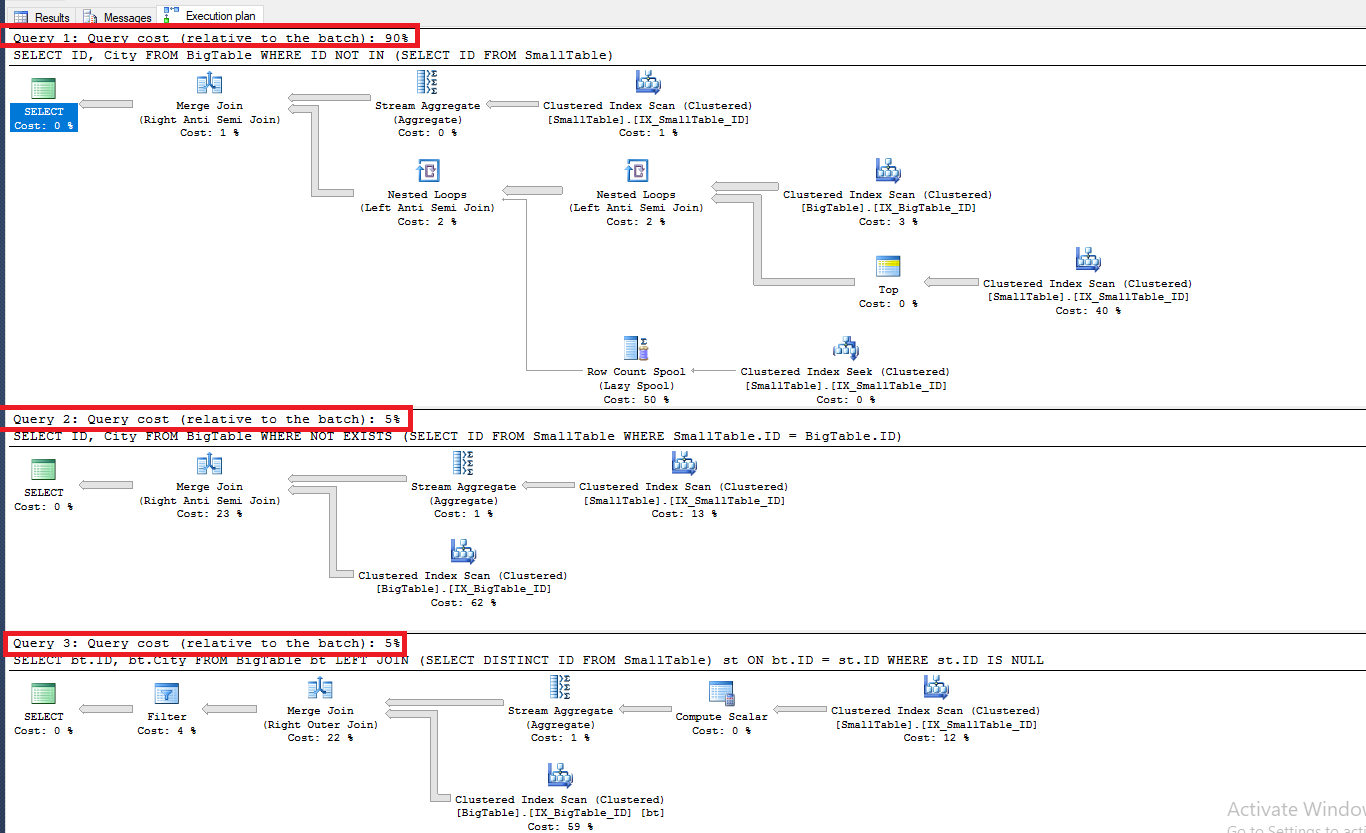
Kết quả trên cho ta thấy trong trường hợp nullable columns Mềnh đề IN có Query Cost rất cao, vì ở đây xuấy hiện Row Count Spool trong Execution Plan. Để hiểu rõ hơn về case này bạn có thể tham khảo bài viết này : https://sqlsunday.com/2019/01/03/nullable-columns-and-performance/
6 Lời kết:
Trước đây chính tôi cũng đặt câu hỏi nên dùng IN, EXISTS, JOIN cho performance tốt nhất. Hy vọng bài viết này có thể giúp mọi người giải quyết được vấn đề đề này.
All rights reserved
