So sánh Onion Architecture và Clean Architecture
Bài đăng này đã không được cập nhật trong 2 năm
Mô hình kiến trúc N-layer đã khá phổ biến trong phát triển phần mềm, nhưng nó vẫn có khá nhiều điểm yếu. Từ đó, nhiều kiến trúc khác đã ra đời để giúp việc phát triển được tốt hơn. Trong bài viết này, chúng ta sẽ tìm hiểu 2 mô hình được sử dụng rộng rãi là Onion và Clean.

1. Kiến trúc N-Layer
Chúng ta sẽ có các lớp logic và vật lý khác nhau đáp ứng cho các nhu cầu trong quá trình phát triển ứng dụng. Hầu hết các ứng dụng sử dụng kiến trúc này đều sẽ chứa 4 lớp: presentation, business, persistence và database. Tùy thuộc vào độ phức tạp của ứng dụng mà các lớp sẽ nhiều hoặc ít hơn.
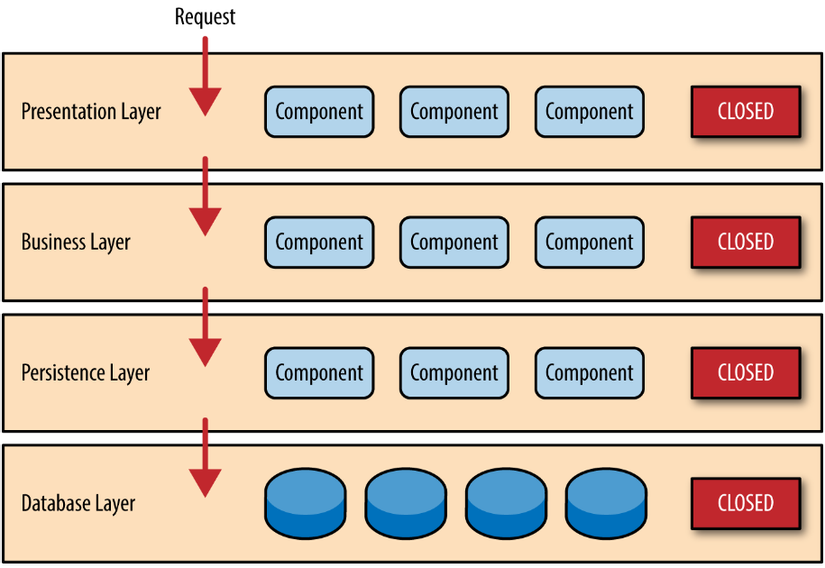 Nguồn: Software Architecture Patterns by Mark Richards
Các lớp trong mô hình kiến trúc này sẽ đảm nhiệm một vai trò cụ thể, và khi đứng từ một lớp nào đó, chúng ta chỉ có thể giao tiếp với các lớp bên trên hoặc bên dưới của nó. Trong đó:
Nguồn: Software Architecture Patterns by Mark Richards
Các lớp trong mô hình kiến trúc này sẽ đảm nhiệm một vai trò cụ thể, và khi đứng từ một lớp nào đó, chúng ta chỉ có thể giao tiếp với các lớp bên trên hoặc bên dưới của nó. Trong đó:
Presentation: là lớp sẽ đảm nhiệm việc tương tác với người dùng, như là giao diện người dùng hoặc cung cấp thông tin dưới dạng Web API. Business: được xem như là thành phần chính trong các ứng dụng, là lớp sẽ chứa các logic nghiệp vụ, ánh xạ trực tiếp đến các nghiệp vụ thực tế mà ứng dụng cần đáp ứng. Persistence: là lớp truy xuất và lưu trữ dữ liệu bằng cách giao tiếp với lớp Database. Database: là nơi lưu trữ dữ liệu của ứng dụng, như là các cơ sở dữ liệu (SQL, No-SQL) hoặc File (Excel, CSV) ... Kiến trúc N-Layer có một số ưu điểm có thể kể đến đó là đơn giản, có thể tái sử dụng, kiểm thử độc lập, giúp cho lập trình viên có thể dễ tiếp cận và làm việc với các logic nghiệp vụ nhanh chóng. Vì vậy, chúng ta có thể sử dụng kiến trúc này cho các ứng dụng quy mô nhỏ hoặc thông thường.
Tuy nhiên, đối với các ứng dụng quy mô lớn, tính mở rộng và phức tạp cao, thì kiến trúc sẽ hoạt động không hiệu quả. Do thiết kế phân lớp, việc thay đổi logic ở một lớp nào đó sẽ khó cập nhật lại ở các lớp khác, đồng thời cũng gây giảm hiệu suất vì các lớp không liền kề phải giao tiếp gián tiếp thông qua một lớp khác. Điều này làm cho ứng dụng sẽ ngày càng trở nên phức tạp và cồng kềnh hơn khi logic nghiệp vụ cũng nhiều hơn.
2. Kiến trúc Onion
Được giới thiệu lần đầu tiên bởi Jeffrey Palermo và năm 2008, để khắc phục các vấn đề kể trên của N-Layer, dựa trên mô hình Domain Driven, tức là xây dựng ứng dụng theo hướng tập trung vào Domain (nghiệp vụ). Từ cái tên "Onion", dịch ra là củ hành tây, ta có thể hiểu được ý đồ của mô hình này là đặt domain làm trung tâm, và bao bọc dần xung quanh bởi các lớp hệ thống khác.
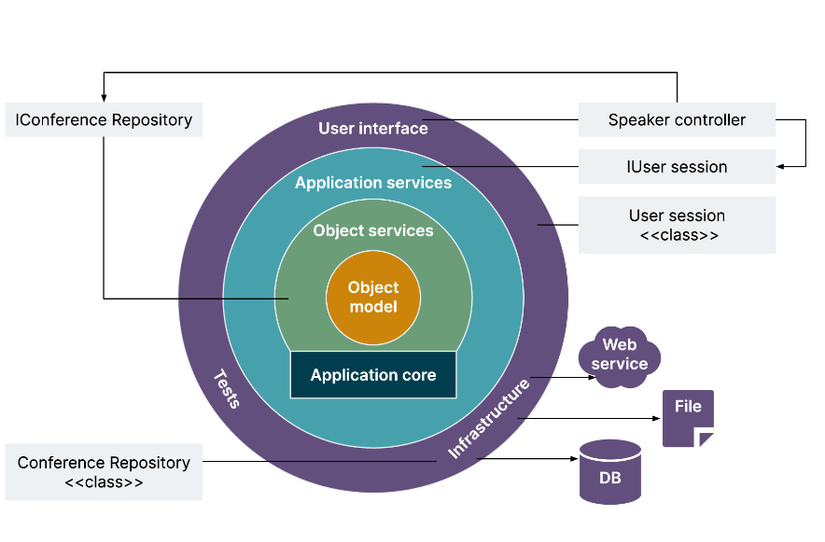 Nguồn: Demystifying software architecture patterns
Các lớp trong Onion được cải tiến dựa trên nguyên lý Dependency Inversion để giải quyết vấn đề phân lớp quá chặt chẽ của N-Layer. Đối với các lập trình viên .NET Core, việc cải tiến này được thể hiện thông qua Dependency Injection, được hỗ trợ sẵn, nhằm giảm tối đa sự phụ thuộc giữa các lớp, service với nhau.
Nguồn: Demystifying software architecture patterns
Các lớp trong Onion được cải tiến dựa trên nguyên lý Dependency Inversion để giải quyết vấn đề phân lớp quá chặt chẽ của N-Layer. Đối với các lập trình viên .NET Core, việc cải tiến này được thể hiện thông qua Dependency Injection, được hỗ trợ sẵn, nhằm giảm tối đa sự phụ thuộc giữa các lớp, service với nhau.
Thông thường, Onion sẽ có 4 lớp chính: domain model, domain services, application service và presentation. Như đã đề cập ở trên, Domain Model sẽ là lớp trung tâm của kiến trúc này. Trong đó:
Domain Model: là nơi tập trung các trạng thái và phương thức, hành vi nghiệp vụ của ứng dụng. Domain Services: là lớp kế tiếp domain model, chứa các interfaces cho việc lưu trữ dữ liệu, phương thức truy xuất, còn được gọi là Repository. Application Services: chứa các interfaces với các phương thức như là Thêm, xóa, sửa.. Ở các lớp services sẽ chỉ chứa các interfaces và các commons class. Presentation: chứa UI và tests. Lớp này cũng chứa các cài đặt của các interface ở tầng services. Một số ưu điểm của kiến trúc này:
Ít bị ràng buộc giữa các lớp với nhau Xây dựng tập trung vào nghiệp vụ Linh hoạt, dễ chuyển đổi, bổ sung và mở rộng Có thể đưa vào phát triển với mẫu DDD (Domain-Driven Design) Bên cạnh đó, một số nhược điểm dễ nhận thấy ở kiến trúc Onion này là:
Khó tiếp cận đối với những lập trình viên mới bắt đầu tham gia, đòi hỏi thời gian học và tìm hiểu sâu Phức tạp và khó áp dụng nếu ứng dụng không có nhiều nghiệp vụ
3. Kiến trúc Clean
Kiến trúc Clean được giới thiệu bởi Uncle Bob vào năm 2012, dựa trên nguyên lý và thừa hưởng các đặc tính của kiến trúc Onion. Điểm khác biệt là kiến trúc này lấy Entities (các đối tượng nghiệp vụ) làm trung tâm.
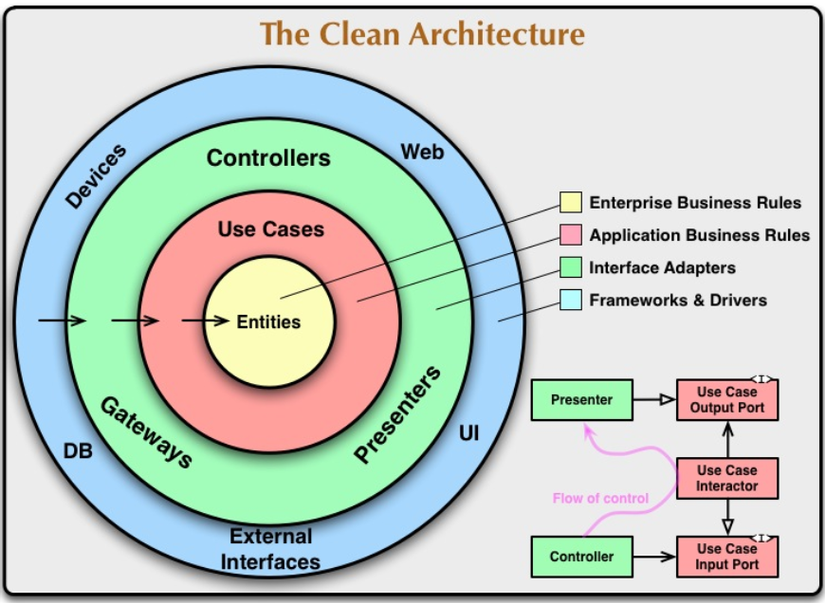 Nguồn: The Clean Code Blog by Robert C. Martin
Các lớp trong kiến trúc clean sẽ được phân tách dựa trên các vai trò cụ thể:
Nguồn: The Clean Code Blog by Robert C. Martin
Các lớp trong kiến trúc clean sẽ được phân tách dựa trên các vai trò cụ thể:
Các entities sẽ là nơi chứa các logic nghiệp vụ chính (enterprise wide business), có thể là các đối tượng cùng phương thức, hành vi của nó, hoặc là tập hợp các cấu trúc dữ liệu (danh sách, node..) và các hàm. Các entities có thể được sử dụng ở nhiều nơi khác trong ứng dụng hoặc xuyên suốt quá trình xử lý nghiệp vụ. Các entities sẽ chỉ ràng buộc với chính nó. Bên ngoài sẽ là lớp chứa nghiệp vụ của ứng dụng - use cases (application specific business). Các thành phần trong lớp này sẽ chứa những cài đặt cho việc ứng dụng đó làm những gì (use cases). Những thay đổi ở lớp này sẽ không được tác động tới các entities, cũng như chính nó cũng sẽ không bị tác động bởi sự thay đổi của các thành phần khác (database, UI, thư viện...). Bao bọc các lớp nghiệp vụ sẽ là lớp thứ ba, chứa các interface adapters, dùng để khai báo interface chuyển đổi dữ liệu và thông tin được yêu câu giữa các lớp nghiệp vụ và các dịch bên ngoài, như là cơ sở dữ liệu, các frameworkss hay là API bên thứ ba. Lớp ngoài cùng sẽ chứa các frameworks và drivers, là các cái đặt cụ thể cho các interface adapters. Đây được xem là nơi chứa mọi chi tiết mà ở các lớp khác khai báo thông qua interfaces. Các frameworks và tools như là cơ sở dữ liệu, web framework, các thư viện bên thứ ba... Kiến trúc Clean vẫn đi theo nguyên lý của Onion: ràng buộc giữa các lớp nên là từ cấp thấp hơn sẽ phụ thuộc vào lớp cấp cao hơn thông qua các interfaces, có thể sử dụng Dependency Injection. Như vậy các logic xử lý chính sẽ không bị phụ thuộc vào các thay đổi đến từ lớp bên ngoài (frameworks and drivers). Ngoài ra, số lượng các lớp ở kiến trúc này cũng không cố định. Nó tùy thuộc vào ứng dụng cụ thể phức tạp ra sao, các yêu cầu nghiệp vụ như thế nào...
Từ đó, ta có thể thấy một số ưu nhược điểm của kiến trúc này:
Ưu điểm: Có thể sử dụng với mô hình microservices hay mẫu DDD Các lớp độc lập với nhau, các logic nghiệp vụ không bị phụ thuộc vào các lớp khác Dễ kiểm thử Dễ mở rộng, vì các lớp đã có vai trò riêng của nó Nhược điểm: Khó để học và hiểu các nghiệp vụ đã được chia tách thành các lớp Cấu trúc phức tạp vì cần phải triển khai qua nhiều lớp Do các lớp không phụ thuộc nhau nên sẽ khá trừu tượng
4. Vậy kiến trúc Onion và Clean có giống nhau?
Tuy kiến trúc Clean ra đời có nhiều ảnh hưởng từ Onion, giữa 2 kiến trúc vẫn có những điểm giống và khác nhau.
Cả hai kiến trúc đều hướng tới việc chia ứng dụng thành nhiều lớp xử lý với các vai trò khác nhau, giúp cho việc xây dựng và triển khai dự án dễ dàng hơn. Cả hai kiến trúc đều áp dụng nguyên lý Dependency Inversion giữa các lớp, giúp cho sự ràng buộc giữa các lớp giảm bớt, các lớp cấp thấp hơn sẽ phụ thuộc lớp cấp cao hơn thông qua abstractions chứ không phải là trực tiếp. Ngoài ra các ứng dụng xây dựng trên 2 kiến trúc này sẽ có khả năng mở rộng cao và có thể được kiểm thử độc lập cho từng lớp.
Những điiểm khác nhau giữa hai kiến trúc:
Kiến trúc Onion Tập trung vào xử lý nghiệp vụ và đưa nó vào trung tâm Các lớp được chia theo vai trò chung (domain, repositories, services..), chủ yếu để phục vụ cho lớp domain trung tâm Các xử lý liên quan đến kỹ thuật, công nghệ được đưa các xử lý ra các lớp bên ngoài Kiến trúc Clean: Chia việc xử lý nghiệp vụ thành 2 lớp: enitities (enterprise wide business) và use cases (application specific business) Các lớp được chia theo vai trò cụ thể (entities, interface adapters, frameworks and drivers..) Sử dụng dependency inversion để phân tách các xử lý rồi mới đưa ra bên ngoài
5. Vậy ta nên sử dụng kiến trúc nào?
Các ứng dụng khác nhau sẽ có khối nghiệp vụ và độ phức tạp khác nhau. Cho nên, tùy vào mỗi ứng dụng và các yêu cầu chức năng của nó mà ta sẽ chọn kiến trúc cho phù hợp.
Một số gợi ý khi chọn kiến trúc Onion:
Thường dành cho mô hình nghiệp vụ của ứng dụng tương đối phức tạp, yêu cầu khá nhiều về tính nhất quán cũng như nhiều tính toán chặt chẽ. Các công nghệ, thư viện sử dụng ở các lớp services có thể linh động Chúng ta sẽ cân nhắc chọn kiến trúc Clean khi:
Mô hình nghiệp vụ không quá phức tạp, có thể chứa trong các đối tượng truyền dữ liệu cùng các hành vi và phương thức Các công nghệ, thư viên sử dụng ở các lớp services có tính phổ biến, cung cấp nhiều tính năng cho hệ thống
6. Kết luận
Onion và Clean đều là những kiến trúc rất hay, hướng ứng dụng tới việc xử lý những khía cạnh của nghiệp vụ, đưa các thư viện, dịch vụ khác ra các lớp bên ngoài. Những ứng dụng này sẽ có khả năng linh động cao, mở rộng tốt, và có tính bảo trì. Có thể nói, 2 kiến trúc này có thể sử dụng để xây dựng bất kỳ loại ứng dụng nào. Và các lập trình viên sẽ cần phải lựa chọn loại kiến trúc phù hợp với nhu cầu, sự phát triển của dự án, ứng dụng.
Tài liệu tham khảo
Software Architecture Patterns by Mark Richards Clean Architecture: A Craftsman’s Guide to Software Structure and Design The Clean code blog - Clean Architecture (Uncle Bob) The Onion Architecture - Jeffrey Palermo
All rights reserved
