[Series Pandas DataFrame] Phân tích dữ liệu cùng Pandas (Phần 7)
Bài đăng này đã không được cập nhật trong 5 năm
Làm việc với Time Series trong Pandas
Pandas thật sự vượt trội trong việc xử lý với Time Series. Mặc dù chức năng này một phần dựa trên datetimes và timedeltas của NumPy, nhưng Pandas cung cấp tính linh hoạt hơn nhiều.
Tạo một DataFrames với Time-Series Labels
Trong phần này, bạn sẽ tạo Pandas DataFrame bằng cách sử dụng dữ liệu nhiệt độ mỗi giờ trong một ngày (đơn vị: độ C).
>>> temp_c = [24.0, 24.1, 24.8, 24.4, 24.0, 24.4, 24.8, 25.0,
... 26.0, 26.8, 27.3, 27.1, 28.2, 29.1, 29.4, 28.1,
... 28.0, 27.9, 27.5, 27.4, 26.9, 26.0, 25.2, 24.7]
Và bây giờ bạn có biến temp_c, là danh sách các giá trị nhiệt độ trong một ngày.
Bước tiếp theo là tạo một chuỗi ngày và giờ. Pandas cung cấp một hàm rất tiện lợi, đó là date_range() để thực hiện việc này:
>>> dt = pd.date_range(start='2021-07-18 00:00:00.0', periods=24, freq='H')
>>> dt
DatetimeIndex(['2021-07-18 00:00:00', '2021-07-18 01:00:00',
'2021-07-18 02:00:00', '2021-07-18 03:00:00',
'2021-07-18 04:00:00', '2021-07-18 05:00:00',
'2021-07-18 06:00:00', '2021-07-18 07:00:00',
'2021-07-18 08:00:00', '2021-07-18 09:00:00',
'2021-07-18 10:00:00', '2021-07-18 11:00:00',
'2021-07-18 12:00:00', '2021-07-18 13:00:00',
'2021-07-18 14:00:00', '2021-07-18 15:00:00',
'2021-07-18 16:00:00', '2021-07-18 17:00:00',
'2021-07-18 18:00:00', '2021-07-18 19:00:00',
'2021-07-18 20:00:00', '2021-07-18 21:00:00',
'2021-07-18 22:00:00', '2021-07-18 23:00:00'],
dtype='datetime64[ns]', freq='H')
date_range() chấp nhận các đối số mà bạn sử dụng để chỉ định thời gian bắt đầu hoặc kết thúc, số khoảng thời gian, tần suất, time-zone, v.v.
Bây giờ bạn đã có các giá trị nhiệt độ và thời gian tương ứng, bạn có thể tạo DataFrame như sau:
>>> temp = pd.DataFrame(data={'temp_c': temp_c}, index=dt)
>>> temp
temp_c
2021-07-18 00:00:00 24.0
2021-07-18 01:00:00 24.1
2021-07-18 02:00:00 24.8
2021-07-18 03:00:00 24.4
2021-07-18 04:00:00 24.0
2021-07-18 05:00:00 24.4
2021-07-18 06:00:00 24.8
2021-07-18 07:00:00 25.0
2021-07-18 08:00:00 26.0
2021-07-18 09:00:00 26.8
2021-07-18 10:00:00 27.3
2021-07-18 11:00:00 27.1
2021-07-18 12:00:00 28.2
2021-07-18 13:00:00 29.1
2021-07-18 14:00:00 29.4
2021-07-18 15:00:00 28.1
2021-07-18 16:00:00 28.0
2021-07-18 17:00:00 27.9
2021-07-18 18:00:00 27.5
2021-07-18 19:00:00 27.4
2021-07-18 20:00:00 26.9
2021-07-18 21:00:00 26.0
2021-07-18 22:00:00 25.2
2021-07-18 23:00:00 24.7
Và đây là kết quả sau khi bạn đã tạo DataFrame với time-series và date-time.
Indexing Và Slicing
Khi bạn có Pandas DataFrame với dữ liệu time-series, bạn có thể áp dụng phương pháp slicing để chỉ lấy một phần thông tin một cách thuận tiện:
>>> temp['2021-07-18 06':'2021-07-18 18']
temp_c
2021-07-18 06:00:00 24.8
2021-07-18 07:00:00 25.0
2021-07-18 08:00:00 26.0
2021-07-18 09:00:00 26.8
2021-07-18 10:00:00 27.3
2021-07-18 11:00:00 27.1
2021-07-18 12:00:00 28.2
2021-07-18 13:00:00 29.1
2021-07-18 14:00:00 29.4
2021-07-18 15:00:00 28.1
2021-07-18 16:00:00 28.0
2021-07-18 17:00:00 27.9
2021-07-18 18:00:00 27.5
Trong ví dụ trên, mình đã trích xuất nhiệt độ từ 6 giờ sáng đến đến 6 giờ tối. Mặc dù mình chỉ cung cấp dữ liệu dưới dạng string, nhưng Pandas có thể hiểu được rằng các row labels của mình là các giá trị ngày và giờ và phân tích chúng.
Resampling và Rolling
Ví dụ ở trên đã cho chúng ta thấy cách kết hợp các date-time row labels và sử dụng phương pháp slicing để lấy thông tin bạn cần từ dữ liệu time-series. Điều này chỉ là khởi đầu. Và có những thứ còn tốt hơn. 
Nếu bạn muốn chia một ngày thành từng khoảng thời gian và nhận được nhiệt độ trung bình cho mỗi khoảng thời gian, thì bạn chỉ cần thực hiện một thao tác duy nhất. Pandas cung cấp phương thức .resample() để thực hiện việc đó, và bạn có thể kết hợp phương thức này với các phương thức khác như .mean() để lấy dữ liệu mà bạn đang cần:
>>> temp.resample(rule='4h').mean()
temp_c
2021-07-18 00:00:00 24.325
2021-07-18 04:00:00 24.550
2021-07-18 08:00:00 26.800
2021-07-18 12:00:00 28.700
2021-07-18 16:00:00 27.700
2021-07-18 20:00:00 25.700
Bây giờ chúng ta có một Pandas DataFrame mới với 6 rows. Mỗi row tương ứng với một khoảng thời gian là bốn giờ. Ví dụ: giá trị 24.325 giá trị nhiệt độ trung bình của bốn giờ đầu tiên của DataFrame temp, và giá trị là giá trị nhiệt độ trung bình của bốn cuối cùng trong ngày là 25.700.
Ngoại trừ hàm .mean(), bạn có thể sử dụng .min() hoặc .max() để lấy nhiệt độ thấp nhất và cao nhất trong mỗi khoảng thời gian. Bạn cũng có thể sử dụng .sum() để lấy tổng giá trị dữ liệu, mặc dù thông tin này có thể không hữu ích khi bạn đang làm việc với nhiệt độ. 
Ở một số trường hợp, bạn có thể cần thực hiện một số rolling-window analysis. Điều này liên quan đến việc tính toán, thống kê cho một số hàng liền kề được chỉ định, tạo nên window of data của bạn. Bạn có thể "roll" window bằng cách chọn một tập hợp các hàng liền kề khác nhau để thực hiện các phép toán của mình.
Pandas cung cấp phương pháp .rolling() cho mục đích này:
>>> temp.rolling(window=4).mean()
temp_c
2021-07-18 00:00:00 NaN
2021-07-18 01:00:00 NaN
2021-07-18 02:00:00 NaN
2021-07-18 03:00:00 24.325
2021-07-18 04:00:00 24.325
2021-07-18 05:00:00 24.400
2021-07-18 06:00:00 24.400
2021-07-18 07:00:00 24.550
2021-07-18 08:00:00 25.050
2021-07-18 09:00:00 25.650
2021-07-18 10:00:00 26.275
2021-07-18 11:00:00 26.800
2021-07-18 12:00:00 27.350
2021-07-18 13:00:00 27.925
2021-07-18 14:00:00 28.450
2021-07-18 15:00:00 28.700
2021-07-18 16:00:00 28.650
2021-07-18 17:00:00 28.350
2021-07-18 18:00:00 27.875
2021-07-18 19:00:00 27.700
2021-07-18 20:00:00 27.425
2021-07-18 21:00:00 26.950
2021-07-18 22:00:00 26.375
2021-07-18 23:00:00 25.700
Với ví dụ trên ta có DataFrame với nhiệt độ trung bình mỗi 4 giờ cho mỗi khung window. Tham số window chỉ định kích thước di chuyển của window.
Ở trong ví dụ, giá trị thứ 4 (24.325) là nhiệt độ được tính trung bình của các giờ (00:00:00, 01:00:00, 02:00:00, 03:00:00). Giá trị thứ 5 là nhiệt độ trung bình cho các giờ (01:00:00, 02:00:00, 03:00:00, 04:00:00). Và cứ thế, nhiệt độ trung bình sẽ được tính toán đến hàng cuối cùng. Với 3 hàng đầu tiên sẽ không có giá trị vì thiêu dữ liệu để tính toán.
Plotting với Pandas DataFrames
Với Pandas, bạn có thể visualize data hoặc tạo các plot dựa trên DataFrames.
Nếu bạn muốn làm việc với plots, thì trước tiên bạn cần import matplotlib.pyplot:
>>> import matplotlib.pyplot as plt
Và giờ bạn có thể sử dụng pandas.DataFrame.plot() để tạo và plt.show() để hiển thị nó.
>>> temp.plot()
>>> plt.show()
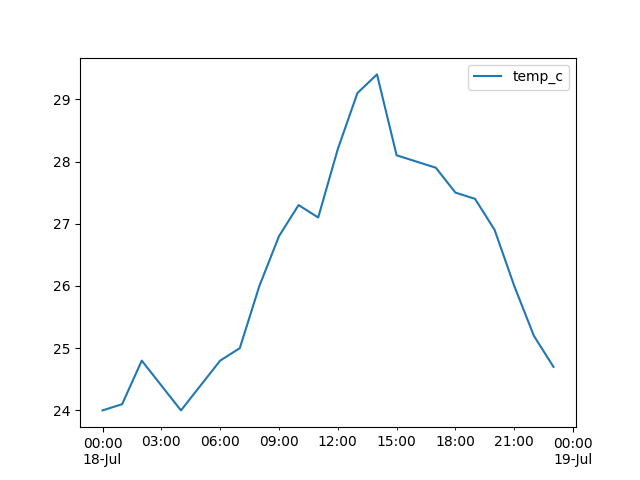
Bạn cũng có thể áp dụng .plot.line() và nhận được kết quả tương tự. Cả .plot() và .plot.line() đều có nhiều tham số tùy chọn mà bạn có thể sử dụng để chỉ định giao diện plot của mình.
Bạn có thể lưu hình ảnh plot bằng cách sử dụng phương thức .getfigure() và .savefig():
>>> temp.plot().get_figure().savefig('tempSG.png')
Hành trình làm quen với Pandas đến đây là kết thúc! Hi vọng bạn sẽ yêu thích nó. 
All rights reserved
