Scale Database với kiến trúc Master Slave
Bài đăng này đã không được cập nhật trong 2 năm
Sau bài viết đầu tiên về đầu tiên những sai lầm khi làm việc với CSDL mình đã nhận được rất nhiều chia sẻ tích cực từ. Các anh chị bạn bè cũng đã có những góp ý về cách viết, nội dung, cách sắp xếp các bài viết để người đọc lôi cuốn hơn. Mình rất cảm ơn những ý kiến đóng góp đó và sẽ có những thay đổi cụ thể hơn.
Từ giờ mỗi bài viết của mình sẽ cố gắng chỉ trình bày 1 khía cạnh và phân tích nó thay vì cố gắng truyền đạt tất cả mọi thứ trong một bài viết. Tuần này là chia sẻ về chủ đề mở rộng database với kiến trúc Master Slave
Bài toán
Thực tế khi mới bắt đầu mình và mọi người đều sẽ code trên máy tính cá nhân của mình, mọi thứ sẽ cài đặt trên đó. Sau đó chúng ta đến việc tách các phần code logic tại một server và database tại một server. Thực tế mọi chuyện đến đây không có gì sai cả và hoàn toán đúng, nếu doanh nghiệp - cá nhân của bạn vẫn vận hành đều đặn với chi phí vận hành hợp lý hoặc các ứng dụng không quá phức tạp thì việc mở rộng SCALE hay thay đổi là điều chưa cần thiết.
Tuy nhiên khi business đang mong muốn làm hoặc giải quyết những điều sau thì các kỹ sư sẽ phải triển khai mở rộng hệ thống (scale backend, scale database …). Trong bài này sẽ mình nói về scale database với kiến trúc Master Slave:
- Concurrency - Khi bạn muốn sản phẩm của mình đáp ứng tốt khả năng sử dụng đồng thời của nhiều người dùng. Cho phép nhiều thao tác đọc, ghi đồng thời vào database
- Load - Nhiều người dùng truy cập và nhiều dữ liệu khiến database chậm phản hồi. Bạn không muốn điều đó hoặc giảm thời gian phản hồi xuống
- High availability - Bạn muốn ứng dụng của bạn luôn chạy dù có vấn đề gì xảy ra đi nữa, vì nó ảnh hưởng đến lợi nhuận của doanh nghiệp và công việc của khách hàng. Một server bị trục trặc, ngay lập tức phải có server khác đảm nhận.
Khi bạn muốn giải quyết và thực hiện các vấn đề trên. Chúng ta sẽ cần mở rộng database và trong bài viết này sẽ nói đến cách mở rộng database với kiến trúc Master Slave (Tuy nhiên kiến trúc này không hoàn toàn có thể giải quyết được tất cả các vấn đề trên một cách hoàn hảo - 100% ~ cùng tìm hiểu nhé)
Master Slave là gì
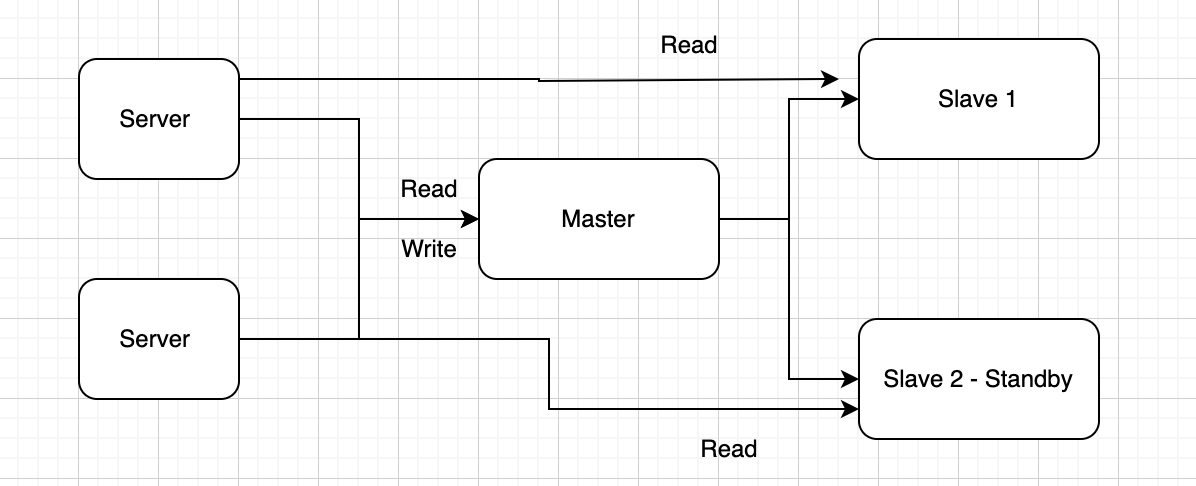
- Master: Là server chính hay gọi là primary server. Đây là nơi mà các hành động “WRITE - GHI” như insert, update, delete sẽ được thực hiện tại đây
- Slave: Là các server copy của master server hay được gọi là replicate. Nó copy dữ liệu và sẽ được updated thông qua việc replication. Các thao tác đọc có thể thực hiện tại các slave server. Có thể thấy từ giờ các thao tác đọc hoàn toàn có thể thực hiện trên các slave server hay là slave node ⇒ giảm tải việc truy cập vào master server
Như vậy từ định nghĩa trên có thể rút ra được:
- Master nhận thực hiện cả hành động ĐỌC và GHI
- Các slave chỉ cho phép các hành động ĐỌC (Tất nhiên như vậy cũng là rất tốt rồi). Nhưng tại sao lại chỉ có ĐỌC, chúng ta sẽ tìm hiểu cách thực hiện việc replication
Quy trình làm việc của Master-Slave replication
- Initialization: Đầu tiên cần tạo một bản copy FULL của master database tại các slave server. Hành động này có thể gọi là snapshotting. Quá trình này đối với các DB cỡ GB trở lên là mất thời gian, không nhanh ! Phải chờ đợi
- Replication Logs: Như đã chia sẻ ở post trước, các hành động trước khi được thực hiện thay đổi thực sự trên dữ liệu, đã được tạo ra trên WAL file (Write-Ahead log). Các WAL file này sẽ được tạo ra từ Master server và gửi đến Slave node, ở đây các thay đổi trên WAL file sẽ được cập nhật trên cả Slave server.
Thực tế khi tìm hiểu đến đây và áp dụng cho product tại công ty mình đã rất lo lắng và thấy sự mong manh của việc stream WAL file log này. Có một số vấn đề sau:
- Xảy ra gián đoạn hoặc ngưng hẳn việc gửi và nhận WAL File thì sao ? Làm sao để biết và kiểm soát việc đó
- Việc gửi và nhận WAL file này nếu chậm sẽ tạo ra 2 kết quả khác nhau vì thực tế 2 cơ sở dữ liệu chưa hoàn toàn giống nhau 100%, ảnh hưởng nghiêm trọng đến trải nghiệm người dùng. Thường được gọi là result inconsistency Đến đây sẽ có 2 chế độ replication để khắc phục phần nào 2 câu hỏi trên.
Chế độ Replication:
- Synchronous Replication: Ở chế độ này master server sẽ đợi cho đến khi các hành động GHI đã được nhân bản xong ở các Slave node (nhận đầy đủ các WAL file) thì mới tiến hành thực thi WRITE. Điều này đảm bảo không bị inconsistency
- Asynchronous Replication: Ở chế độ này master server sẽ không quan tâm việc slave server có đồng bộ dữ liệu được hay không, nó ngay lập tức thực thi mỗi khi có yêu cầu. Có thể dẫn đến inconsistency
Sai lầm của mình: Mình đã từng design và sau khi học xong đã tự tin apply synchronous replication để đảm bảo việc không bị inconsistency nhưng nó phát sinh ra vấn đề khác. Mình có 3 slave server hay có thể gọi là 3 nodes và một master node. Theo lý thuyết: khi có một hành động WRITE, master sẽ gửi WAL đến các slave node. Đợi đến khi cả 3 slave node đồng bộ xong, lệnh mới được thi. HÀNH ĐỘNG WRITE NÀY ĐÃ BỊ CHẬM ĐI - LATENCY tăng lên.
Tuy nhiên KHI MỘT TRONG 3 NODE, không đồng bộ được ~ đã xảy ra vấn đề. Thì HÀNH ĐỘNG SẼ MÃI CHỜ, KHÔNG ĐƯỢC THỰC THI TRÊN CẢ MASTER VÀ TẤT CẢ. Vô tình tạo ra SINGLE POINT OF FAILURE của toàn bộ hệ thống
Hot standby
Hot standby là một các sử dụng standby server (là một slave node) sẽ thay thế master server để làm master khi master server hiện tại có vấn đề. Đảm bảo tính high availability và là một chiến lược chống lỗi trong database system. Việc cài đặt này cũng không khó và có các hướng dẫn khác trên internet tốt hơn mình. Chỉ cần chú ý các vấn đề sau:
- Đảm bảo config để Master server và các slave servers có thể giao tiếp với nhau
- Cài đặt chế độ standby, trigger_file và thông tin master tại Slave server được chỉ định Tuy nhiên quá trình chuyển giao từ standby server hay salve node thành master có thể mất một chút thời gian nên không hẳn sẽ đảm bảo 100% HIGH AVAILABILITY
Kết
Đến đây mình nghĩ sẽ có 3 câu hỏi chính mà mọi người nếu muốn ứng dụng kiến trúc này vào production:
- Làm sao quản lý và theo dõi được việc replication (stream file) để biết khi nào lỗi, delay …
- Thiết kế và code ở tầng application để có thể tối ưu việc READ và WRITE riêng
- Thiết kế và code ở tầng application để có thể ĐỔI không truy cập vào master nữa, mà dùng standby server khi master gặp vấn đề
Nếu ai thích đọc nội dung tiếng anh, hãy đọc link này: https://nmdan.com/blog/scale-database-with-master-slave
- FB cá nhân: Minh Dân
- Website cá nhân: nmdan.com
All rights reserved
