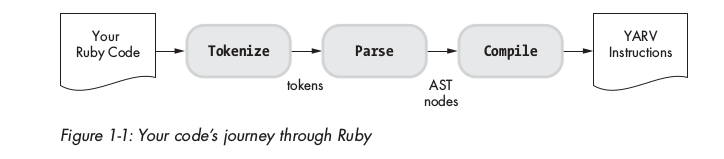
Ruby tokenization and parsing
Bài đăng này đã không được cập nhật trong 5 năm
Điều gì sẽ xảy ra khi bạn mở irb và chạy 1 đoạn code ruby, ( ex: puts 100 ) ?
Đoạn code đó đã được xử lý như thế nào để ra in ra được số 100 trên màn hình console ?
Bài viết này mình sẽ nói về quá trình này  .
.
Tokenization
Đầu tiên, đoạn code được ruby token hóa, đọc tất cả các dòng text trong file source code và convert chúng thành những tokens.
Ví dụ, viết 1 đoạn code ruby và lưu nó vào trong 1 file:
# simple.rb
10.times do |n|
puts n
end
Khi chạy ruby simple.rb, đầu tiên ruby sẽ mở file này lên đọc toàn bộ text có trong file này:

Ruby C source code loop từng kí tự và process từng kí tự một.
Bắt đầu scanning từ character đầu tiên:

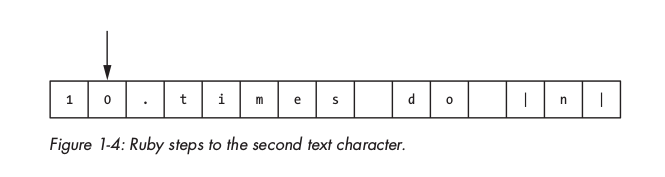
Kí tự 1 được ruby hiểu là bắt đầu của một numeric và tiếp tục lặp tới kí tự kế, là 0:
tiếp tục:
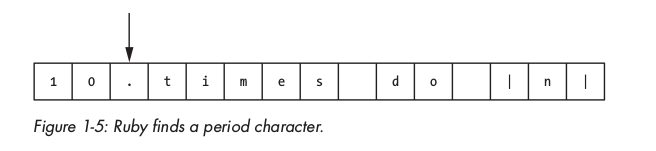
Kí tự này là dấu chấm ., ruby cho rằng có thể nó là một phần của float value và tiếp tục lặp:
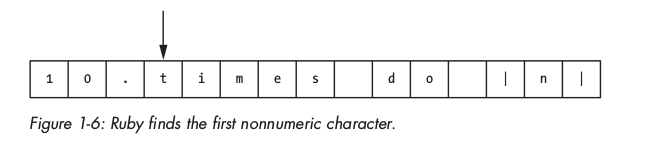
Kí tự kế lại là t, vì nó không phải là một kí tự numeric, ruby "hiểu" rằng không có số numeric nào sau dấu chấm .  , vậy nên nó cho rằng
, vậy nên nó cho rằng . là một token riêng biệt và quay lại 1 step:
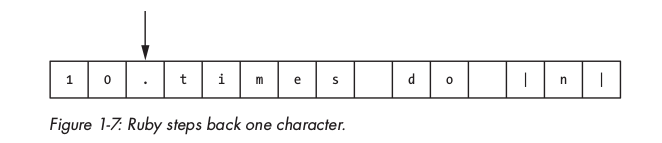
Vì . được cho là một token nên hai kí tự đầu 1, 0 sẽ là một số integer, ruby convert chúng thành 1 token ( loại tINTEGER )

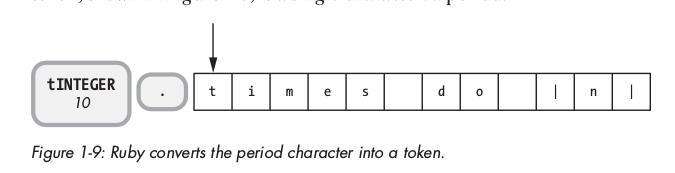
Tiếp tục convert . thành một token:
Kế tiếp, ruby lặp và tìm thấy 5 kí tự và convert thành token: times ( loại tIDENTIFIER ):
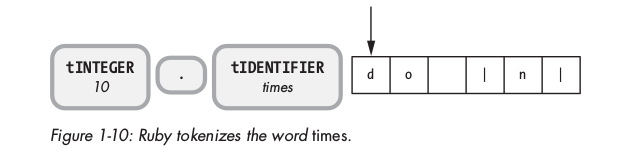
Identifiers trong ruby code không phải là các reserved words, chúng là các tên biến, method hay tên class.
Tiếp, ruby đọc được kí tự do và convert nó thành keyword_do ( do là một trong những reserved words trong ruby ):
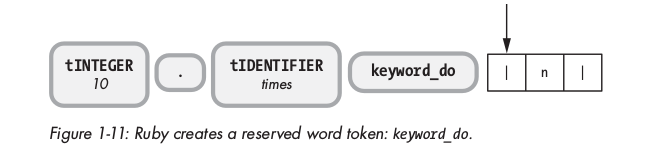
Các reserved words đã được định nghĩa trong C source code.
Cuối cùng, các kí tự còn lại đều được convert thành các tokens:

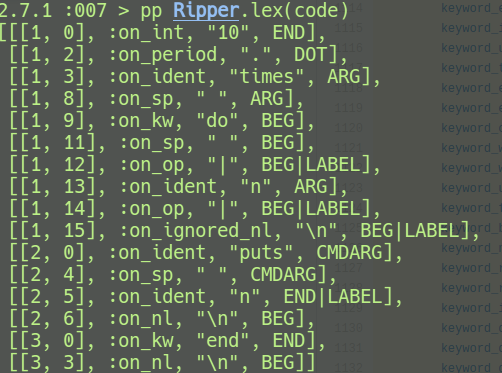
Ta có thể kiểm tra đoạn code của mình đã được convert thành các token:
code = <<STR
10.times do |n|
puts n
end
STR
pp Ripper.lex(code)
Parsing
Sau khi convert cả file text, ruby đi tới quá trình parsing.
Trong quá trình parsing, các tokens được gom nhóm thành những sentences hoặc phrases mà ruby có thể hiểu được.
Quá trình này ruby sử dụng parser generator ( được gọi là Bison ).
Quá trình Tokenization và Parsing trong lúc build time và run time được minh họa ở hình dưới:
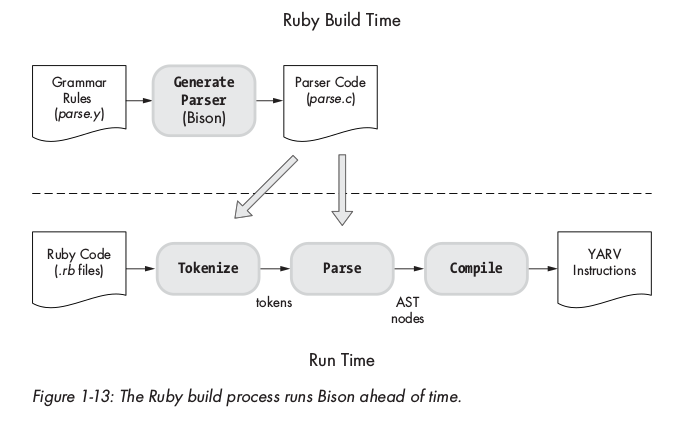
Trong thời gian Ruby build time, Ruby build process dùng Bison để gen ra file parse.c từ file parse.y , vì thế nên parse.c sẽ chứa phần code token hóa ở mục trước.
Trong quá trình run time, 2 tiến trình tokenization và parsing sẽ diễn ra đồng thời, parsing sẽ token hóa khi nào nó cần token mới.
LALR Parse Algorithm
Thuật toán được parsing dùng là LALR ( Look-Ahead Left Reversed Rightmost
Derivation ), bao gồm 2 phần:
- Left Reversed Rightmost Derivation (
LR):parsingxử lý cáctokenstừ trái sang phải, match theo thứ tự xuất hiện củatokensdựa trên cácgrammar rulescó trongparse.y. - Look ahead (
L):parsingcũng đồng thời kiểm tra cáctokenphía trước trong quá trình process để quyết định match đúnggrammar rulephù hợp.
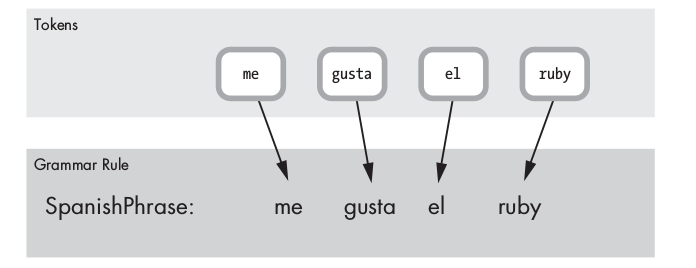
Ví dụ, mong muốn dịch một câu từ tiếng Spanish sang English:
"Me gusta el Ruby" => "I like Ruby"
Các grammar rules được định nghĩa trong parse.y. parser generator ( Bison ) gen ra file parse.c từ file này, và các rule trong parse.y đều có syntax quy định:

Theo rule trên thì nếu các tokens bằng với me, gusta, eq, ruby thì match với SpanishPhrase rule, và nếu match thì đoạn code C bên trong sẽ được chạy:
Một ví dụ khác, lúc này có 2 câu tiếng Spanish và muốn kiếm tra xem input sẽ match với câu ( rule ) nào:
"Me gusta el Ruby" => "I like Ruby"
"Le gusta el Ruby" => "She/He/It likes Ruby"
File parse.y sẽ như sau:

Lúc này sẽ có tới 4 grammar rule thay vì 1 như ví dụ trước. Có 2 directive ở đây, đó là:
$$: Chứa giá trị trả về từchild grammar rulechoparent grammar rule$1: Chứa giá trị lấy từchild grammar rulevà dùng trongparent grammar rule
Ở đây SpanishPhrase rule là parent của VerbAndObject, VerbAndObject là parent của SheLikes và ILike.
Bắt đầu quá trình parsing, các tokens được thực hiện từ trái qua phải ( LR ):
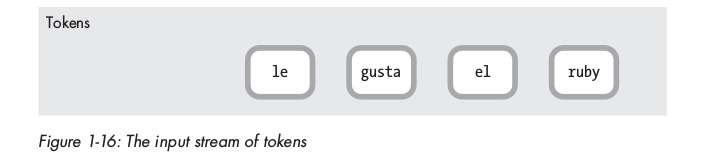
Đầu tiên, token le được shift ( đẩy ra ) khỏi mảng tokens, đưa vào một stack ( grammar rule stack ):
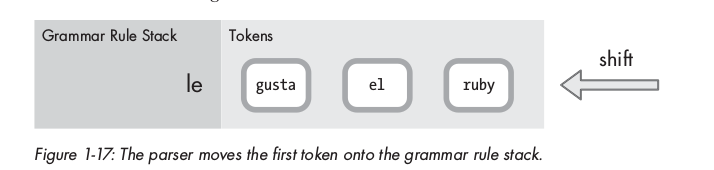
Vì le không match với bất kì grammar rule nào, nên parse tiếp tục shift gusta vào:
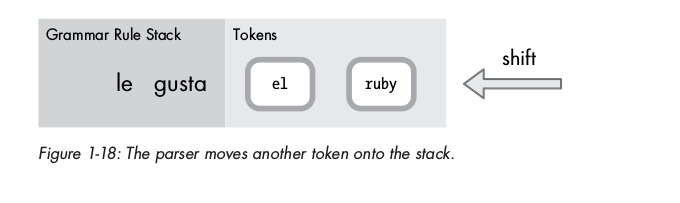
Lúc này có 2 token trong stack: le và gusta,
parser check các rules được defined, thấy match với rule SheLikes, do vậy, parser thay thế cặp token le + gusta thành rule SheLikes được match ( reduce ):
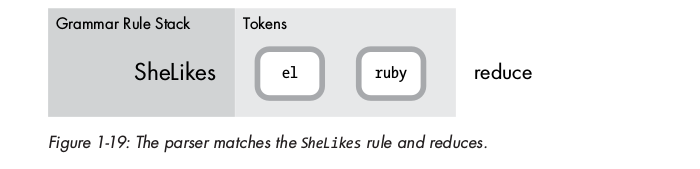
Tiếp tục, parser reduce lần nữa với một match rule khác ( VerbAndObject ):
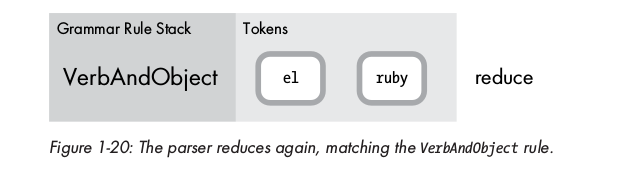
Vậy tại sao parser lại biết được có thể tiếp tục reduce lần thứ 2 này mà không tiếp tục shift thêm token mới ?
Làm thế nào parser quyết định khi nào thì shift hay reduce ?
Quay lại thời điểm 2 token được shift vào stack: le + gusta:
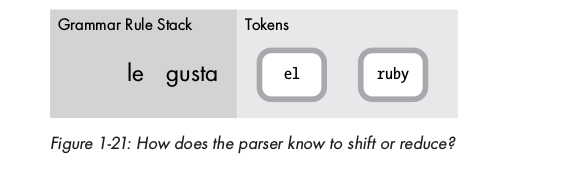
Đây là lúc parser sử dụng phần LA ( look ahead ) trong thuật toán.
Để tìm kiếm đúng rule, parser check token kế tiếp trong mảng tokens:
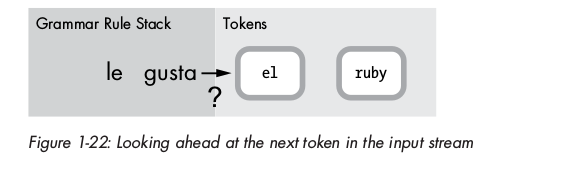
Dựa vào 1 bảng được tính toán từ trước, bảng này chứa các khả năng xảy ra dựa theo token kế tiếp và rule vừa được match là gì, parser sẽ quyết định rule nào mới được match.
Theo đó, bảng này sẽ chỉ ra nếu rule vừa được match ( SheLikes ) nếu đi theo với token kế tiếp ( el ) thì sẽ match được một rule mới ( VerbAndObject ).
Sau khi reduce với rule VerbAndObject, parser tiếp tục shift token el vào stack:
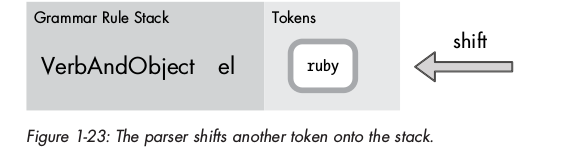
Không có rule nào match, tiếp tục shift token ruby:
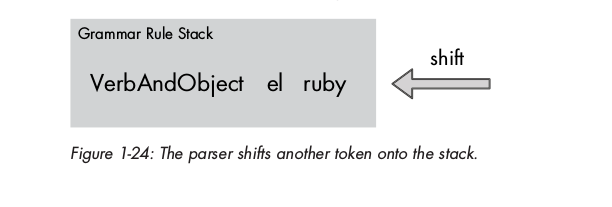
Cuối cùng, rule match là SpanishPhrase:

Trên thực tế, các grammar rule được defined trong parse.y rất nhiều và phức tạp, nhưng sẽ tuân theo các syntax như trên ( $$, $1, $2, ... )
Sau đây là ví dụ thực tế về code sẽ được parse sang grammar rules:

Sau khi tất cả source code được parse sang các grammar rules, và tiếp tục được convert sang một data structure được gọi là abstract syntax tree ( AST ):
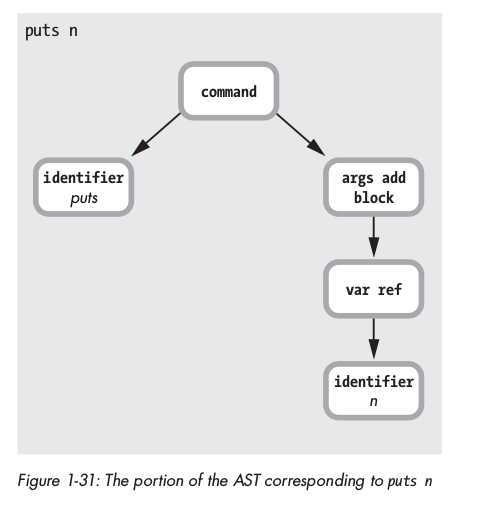
Sau đó, các AST nodesnày sẽ được compile thành YARV instructions ( sẽ nói ở bài viết khác ).
Cảm ơn mn đã đọc bài viết của mình.
All rights reserved
