[Ruby] Crawl Data và Scrape Data
Bài đăng này đã không được cập nhật trong 3 năm
Hi 👋
Trong lĩnh vực thu thập dữ liệu trên web, hai thuật ngữ phổ biến là "scraping" và "crawling". Cả hai đều là các phương pháp để lấy dữ liệu từ các trang web, tuy nhiên chúng có một số khác biệt quan trọng. Trong bài viết này, chúng ta sẽ tìm hiểu về scrape và crawl data trong Ruby.
1. Scrape Data:
Scraping data (còn được gọi là web scraping) là quá trình lấy dữ liệu từ một trang web cụ thể bằng cách trích xuất thông tin từ các phần tử HTML của trang đó. Scraping thường được sử dụng khi bạn chỉ quan tâm đến dữ liệu từ một số trang web cụ thể và muốn lấy thông tin từ các thành phần nhất định trên trang web đó.
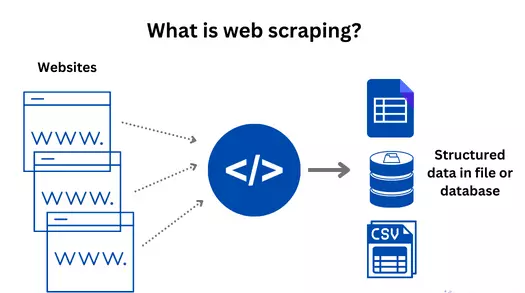
Trong Ruby, ta có thể sử dụng các thư viện như Nokogiri hoặc Mechanize để scrape data từ trang web. Các thư viện này cung cấp các công cụ để trích xuất dữ liệu từ các phần tử HTML, như <tag>, class, id, hoặc XPath.
Ví dụ, bạn có thể sử dụng Nokogiri để scrape thông tin từ một trang web:
ruby
require 'nokogiri'
require 'open-uri'
# Đọc nội dung HTML của trang web
html = open('https://example.com').read
# Tạo đối tượng Nokogiri từ nội dung HTML
doc = Nokogiri::HTML(html)
# Trích xuất thông tin từ các phần tử HTML
title = doc.at_css('title').text
Tuy nhiên Nokogiri chỉ cung cấp công cụ để trích xuất dữ liệu từ các phần tử HTML của trang web, không thực hiện các thao tác đăng nhập. Vậy đối với những trang web yêu cầu đăng nhập thì phải làm sao ?
Để scrape một trang web yêu cầu đăng nhập, ta cần sử dụng một công cụ tự động hóa trình duyệt như Selenium hoặc Mechanize. Cả hai công cụ này đều hỗ trợ Ruby và cho phép bạn thực hiện các thao tác như điều hướng trang, nhập liệu và đăng nhập vào trang web.
Dưới đây là một ví dụ về cách sử dụng gem Nokogiri và Selenium để scrape một trang web yêu cầu đăng nhập:
ruby
require 'selenium-webdriver'
require 'nokogiri'
# Khởi tạo trình duyệt Selenium
driver = Selenium::WebDriver.for :chrome
# Đăng nhập vào trang web
driver.get('https://example.com/login')
driver.find_element(:id, 'username').send_keys('your_username')
driver.find_element(:id, 'password').send_keys('your_password')
driver.find_element(:id, 'login-button').click
# Chờ cho trang web tải xong
sleep(3)
# Lấy nội dung HTML của trang web đã đăng nhập
html = driver.page_source
# Tạo đối tượng Nokogiri từ nội dung HTML
doc = Nokogiri::HTML(html)
# Trích xuất thông tin từ các phần tử HTML
title = doc.at_css('title').text
puts title
# Đóng trình duyệt
driver.quit
Trong ví dụ trên, chúng mình sử dụng Selenium để tự động hóa trình duyệt Chrome và thực hiện các thao tác đăng nhập vào trang web, bạn có thể tham khảo gem và tài liệu về Selenium tại đây. Sau khi đăng nhập thành công, chúng ta lấy nội dung HTML của trang web đã đăng nhập và sử dụng Nokogiri để trích xuất thông tin từ các phần tử HTML.
Lưu ý rằng việc scrape một trang web yêu cầu đăng nhập có thể vi phạm các quy định và chính sách của trang web đó. Hãy đảm bảo bạn có quyền truy cập và sử dụng dữ liệu từ trang web trước khi thực hiện bất kỳ hành động scrape nào.
2. Crawl Data:
Crawling data là quá trình tự động duyệt qua các trang web và lấy dữ liệu từ nhiều trang web khác nhau. Crawling thường được sử dụng khi bạn muốn thu thập dữ liệu từ nhiều nguồn khác nhau hoặc lấy toàn bộ dữ liệu từ một trang web lớn.
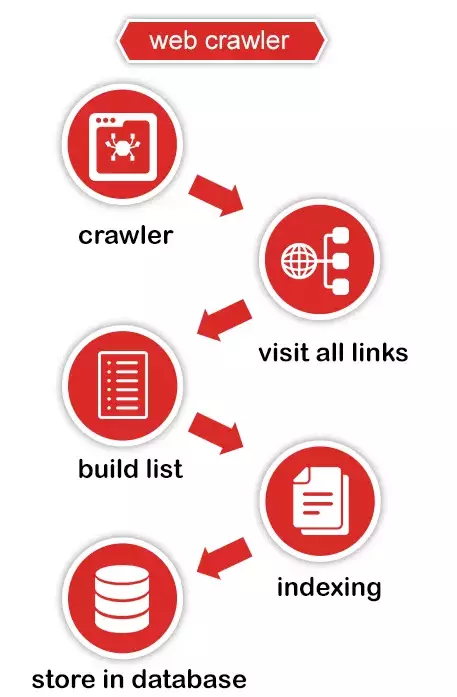
Trong Ruby, ta có thể sử dụng các thư viện như Mechanize hoặc Faraday để crawl data từ trang web. Các thư viện này cung cấp các công cụ để tự động thực hiện các thao tác trên trình duyệt web, như điều hướng qua các liên kết và lấy dữ liệu từ các trang web khác nhau.
Ví dụ, ta có thể sử dụng Mechanize để crawl dữ liệu từ một trang web:
ruby
require 'mechanize'
# Tạo một đối tượng Mechanize
agent = Mechanize.new
# Truy cập trang web
page = agent.get('https://example.com')
# Duyệt qua các liên kết trên trang web và lấy dữ liệu
page.links.each do |link|
puts link.text
# Lấy nội dung HTML của trang đã crawl
html = link.body
# Sử dụng gem Nokogiri để phân tích mã HTML
doc = Nokogiri::HTML(html)
#Trích xuất thông tin từ các phần tử HTML để lấy data
title = doc.at_css('title').text
end
Đối với trang web cần đăng nhập thì sao ? Đừng lo gem mechanize đã support chúng ta việc này !
ruby
require 'mechanize'
agent = Mechanize.new
page = agent.get('https://example.com')
# Tìm biểu mẫu đăng nhập
login_form = page.forms.first
# Điền thông tin đăng nhập vào biểu mẫu
login_form['username'] = 'your_username'
login_form['password'] = 'your_password'
# Click vào nút đăng nhập và gửi biểu mẫu đi
logged_in_page = login_form.submit
# Truy cập vào trang web đã đăng nhập
data_page = agent.get('https://example.com/data')
# Lấy dữ liệu từ trang đã crawl
data = data_page.body
Với gem mechanize chúng ta có thể dễ dàng thực hiện các thao tác như submit form, click button, upload_file, download_file ... Chi tiết hơn ae có thể vào gem để tìm hiểu chi tiết nhé.
Tóm lại, scrape và crawl data là hai phương pháp khác nhau để lấy dữ liệu từ web. Scrape data là quá trình trích xuất thông tin từ một trang web cụ thể, trong khi crawl data là quá trình tự động duyệt qua nhiều trang web và lấy dữ liệu từ chúng. Ruby cung cấp các thư viện mạnh mẽ để thực hiện cả hai phương pháp này, giúp bạn thu thập dữ liệu một cách hiệu quả và tự động.
Trên đây là những hiểu biết của mình về việc thu thập thông tin, dữ liệu từ trang web khác. Bài viết được tham khảo từ tài liệu chính thức của gem Nokogiri , Mechanize, SeleniumHQ
(Trong bài tiếp theo mình sẽ đi sâu vào ví dụ cụ thể phân tích, cào dữ liệu từ 1 trang web) . Cảm ơn các bạn đã theo dõi!. Chúc các bạn 1 tuần làm việc hiệu quả !
All rights reserved
