Regular Expression Reference
Bài đăng này đã không được cập nhật trong 4 năm
Tạm dừng series bài viết về module của Python (PyMOTM) để tránh nhàm chán, hôm nay mình xin chia sẻ về Regular Expression (hay còn gọi là biểu thức chính quy) trong lập trình. Bài viết này mình sẽ giới thiệu về Regular Expression, những tokens, modifiers mà RegEx hỗ trợ. Mình sẽ dịch nó (theo những gì mình hiểu) kèm với những ví dụ đi cùng (nếu có thể) để bạn có thể hiểu hơn về RegEx nhé.
Regular Expression là gì?
Regular Expression (Biểu thức quy tắc - gọi tắt là RegEx) là một chuỗi ký tự đặc biệt được dùng làm mẫu (pattern) để phân tích, so sánh sự trùng khớp của một tập hợp các chuỗi cho trước nào đó. Vậy trong lập trình, RegEx dùng để làm gì? Chúng ta thường xuyên sử dụng nó để kiểm tra tính hợp lệ (validate) của form (dữ liệu do người dùng nhập và đưa lên server cho chúng ta xử lý). Hoặc nó cũng được sử dụng để tìm kiếm, thay thế, xử lý hay trích xuất dữ liệu từ một tập hợp các đoạn văn bản nào đó.
Vâng, vậy là chúng ta đã có cái nhìn cơ bản về RegEx rồi. Giờ chúng ta sẽ đi tìm hiểu các tokens và modifiers của RegEx nhé. Mình sẽ chia bài viết thành nhiều phần. Mỗi phần là một tập hợp các tokens được sử dụng để xử lý trong các trường hợp yêu cầu cụ thể.
RegEx tokens
General tokens
\n: Newline. Tìm kiếm ký tự xuống dòng (line-feed)\r: Carriage return. Tìm kiếm ký tự điều khiển (control character) đưa con trỏ về đầu dòng (không bao gồm xuống dòng)\t: Tab. Tìm kiếm ký tự tab ngang (tập hợp 1 số spacebar nhất định nào đó)\0: Null. Tìm kiếm ký tự null. Một ký tự dùng để kết thúc chuỗi trong văn bản.
Anchors
\G: Start of match. Trả về kết quả của lần tìm kiếm trước đó hoặc lần gặp đầu tiên của một chuỗi. Khi bạn sử dụng token này với modifierg(global).

^: Start of string. Tìm kiếm ở vị trí bắt đầu của một chuỗi. Nếu bạn sử dụng modifierm(multipleline) thì nó sẽ tìm kiếm theo vị trí bắt đầu của chuỗi ở mỗi dòng.

$: End of string. Tìm kiếm ở vị trí cuối cùng của một chuỗi. Nếu bạn sử dụng modifiermthì nó sẽ tìm kiếm theo vị trí cuối cùng của chuỗi ở mỗi dòng.

\A: Start of string. Cũng là tìm kiếm ở ví trí bắt đầu của mỗi chuỗi. Nhưng không giống với^,\Akhông bị ảnh hưởng bởi modifierm. Nếu bạn đã làm việc với RoR, khi viết RegEx và chạy Rubocop, nó sẽ khuyên bạn sử dụng\Athay vì^đấy

\Z: End of string. Cũng là tìm kiếm ở vị trí cuối cùng của chuỗi. Nhưng không giống với$vì\Zkhông bị ảnh hưởng bởi modifierm. Cũng giống với\A, Rubocop sẽ khuyên bạn sử dụng token này thay thế token$

\z: Absolute end of string. Về ý nghĩa thì nó cũng giống với token\Z, nhưng nó ngược lại với\Z, nó sẽ không tìm kiếm nếu như vẫn còn một ký tự newline đằng sau nó. Bạn có thể xem 2 ảnh của\Zvà\zđể so sánh.

\b: A word boundary. Tìm kiếm chính xác từ đó mà không chứa một ký tự bất kỳ nào khác. Bạn có thể xem ảnh để hiểu rõ hơn. Mình đã viết ví dụ rất rõ ràng để mô tả token\bnày

\B: Non-word boundary. Ngược lại của token\b.

Meta sequences
.: Any single character. Tìm kiếm một ký tự bất kỳ (bao gồm cả ký tự khoảng trắng \s) khác ký tự xuống dòng (newline).\s: Any whitespace character. Tìm kiếm ký tự khoảng trắng, tab ngang hay một ký tự xuống dòng (newline)\S: Any non-whitespace character. Ngược lại với token\slà tìm kiếm một ký tự không phải là khoảng trắng, tab ngang hoặc ký tự xuống dòng (newline).

\d: Any digit. Tìm kiếm số thập phân. Tương đương với[0-9].\D: Any non-digit. Ngược lại với token\d. Là tìm kiếm 1 ký tự không phải là một số thập phân.

\w: Any word character. Tìm kiếm chữ, số và dấu gạch dưới (underscore) không bao gồm khoảng trắng (whitespace), tab ngang và dấu xuống dòng (newline).\W: Any non-word character. Ngược lại với token\s. Là tìm kiếm một ký tự không phải là chữ, số và dấu gạch dưới (underscore).

\v: Vertical whitespace character. Tìm kiếm xuống dòng (newline) và ký tự tab dọc. Bạn có thể xem thêm định nghĩa về vertical tab tại đây!\n: Newline character. Tìm kiếm ký tự xuống dòng (newline).\uYYYY: Hex character YYYY. Tìm kiếm ký tự unicode với mã hex.

\xYY: Hex character YY. Tìm kiếm ký tự 8-bit với mã hex.

\ddd: Octal character ddd. Tìm kiếm ký tự với mã Oct.

cY: Control character Y. Tìm kiếm ký tự ASCII thông thường được gắn kèm với phím Control (Ctrl). Ví dụ:cClà tìm kiếm ký tự Control+C[\b]: Backspace character. Tìm kiếm ký tự điều khiển backspace (trên bàn phím là nút xóa 1 ký tự về bên trái - ngược với phím Del(ete) là xóa 1 ký tự về bên phải)\: Escape character. Ký tự này được sử dụng để escape 1 ký tự điều khiển nào đó.

Quantifiers
?: Zero or one. Tìm kiếm một ký tự nào đó với điều kiện có hoặc không có cũng được. Ví dụ bạn muốn validate một URL nào đó cho phép cả http hoặc https. Bạn có thể dùng/^http|https/cũng được. Nhưng nó khá là thừa. Thay vào đó bạn có thể sử dụng tokens?để thực hiện việc này. Trong ảnh dưới đây. Mình có viết 5 ví dụ. Thì ví dụ thứ 3 để mọi người hiểu làm sao sử dụng?với số lượng ký tự lớn hơn 1.

*: Zero or more. Tìm kiếm một ký tự nào đó với điều kiện không có hoặc có nhiều hơn một lần.

+: One or more. Tìm kiếm 1 hoặc nhiều ký tự xuất hiện liên tiếp nhau (không giống với*là không có hoặc có nhiều).{n}: Exactly of n. Tìm kiếm chính xác số lần (n) xuất hiện của một ký tự nào đó.

{n,}: n or more. Tìm kiếm chính xác số lần (n) xuất hiện liên tiếp từ n cho đến vô hạn.

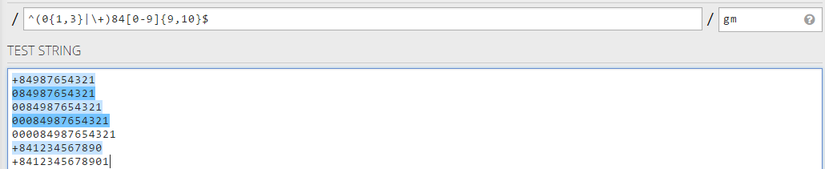
{n,m}: Between n and m: Tìm kiếm chính xác số lần xuất hiện trong khoảng từncho đếnmlần. Mình sẽ lấy ví dụ là 1 validate đơn giản số điện thoại của Việt Nam nhé
*: Greedy quantifier. Tìm kiếm không quan tâm đến việc nó chứa những ký tự gì bên trong mà chỉ cần biết nó có phù hợp với pattern của mình hay không. Bạn nên cẩn thận khi sử dụng pattern kiểu này để tránh việc tìm cả những dữ liệu không mong muốn.

*?: Lazy quantifier. Kiểu tìm kiếm một vài ký tự bất kỳ. Không quan tâm đến việc nó chứa gì. Chỉ cần phù hợp với pattern của mình đưa ra.

Group constructs
(...): Capture everything enclosed. Nhóm (gộp) một hoặc nhiều pattern cần tìm kiếm.

(a|b): Match either a or b. Tìm kiếm chuỗi nào phù hợp với pattern này hoặc pattern kia. Bạn có thể xem lại ví dụ của(...)hoặc ví dụ về validate số điện thoại của phần{n,m}.(?=...): Positive lookahead. Tìm kiếm pattern trước nó với điều kiện phải phù hợp với subpattern đằng sau nó. Bạn có thể xem ví dụ để hiểu hơn

(?!..): Native lookahead. Ngược lại với pattern(?=...). Tìm kiếm pattern trước nó với điều kiện không được giống (phủ định) subpattern đằng sau nó.

(?<=...): Possitive lookbehind. Tìm kiếm một giá trị mà có giá trị trước đó phù hợp với pattern được đưa ra trong cặp(?<=...).

(?<!...): Negative lookbehind. Ngược lại vớiPositive lookbehindlà tìm kiếm một giá trị mà có giá trị trước đó không giống (phủ định) với giá trị đưa ra trong cặp(?<!...).

Character classes
[abc]: Single character. Tìm kiếm một trong các ký tự được xuất hiện trong pattern.

[^abc]: Single character but except pattern. Tìm kiếm các ký tự không thuộc một trong các ký tự được xuất hiện trong pattern.

[a-z]: A character in the range. Tìm kiếm một hoặc các ký tự nằm trong khoảng pattern.

[^a-z]: A character not in the range. Tìm kiếm một hoặc các ký tự không nằm trong khoảng pattern.

[[:alnum:]]: Letters and digits. Tìm kiếm tất cả các chữ và số. Tương đương với[a-zA-Z0-9][[:alpha:]]: Lettes. Tìm kiếm tất cả các chữ cái alpha. Tương đương với[a-zA-Z][[:ascii:]]: ASCII codes from 0 to 127. Tìm kiếm các ký tự nằm có mã ASCII nằm trong khoảng từ 0-127. Bạn có thể tham khảo ASCII codes table tại đây.[[:blank:]]: Space or tab only. Chỉ tìm kiếm dấu khoảng trắng hoặc dấu tab ngang.[[:cntrl:]]: Control character. Tìm kiếm các ký tự điều khiển, bao gồm dấu ngắt dòng (newline), ký tự null (null character), tab và ký tự thoát (escape character).[[:digit:]]: Decimal digits. Tìm kiếm chữ số thập phân. Tương tự với pattern[0-9].[[:lower:]]: Lowercase letters. Tìm kiếm các ký tự chữ thường. Tương tự với[a-z].[[:punct:]]: Visible punctuation character. Tìm kiếm các ký tự đặc biệt trong khoảng ASCII code từ 0-127 không bao gồm khoảng trắng.[[:space:]]: Whitespace. Tìm kiếm dấu khoảng trắng (spacebar). Tương tự\s.[[:upper:]]: Uppercase letters. Tìm kiếm các ký chữ hoa. Tương tự[A-Z][[:word:]]: Word character. Tìm kiếm các chữ, số và dấu gạch dưới. Tương tự\w.[[:xdigit:]]: Tìm kiếm số chữ số thập lục phân. Tương tự[0-9A-Fa-f]. Dùng để tìm kiếm mã màu trong CSS rất tiện ^^!

RegEx modifier
RegEx modifier là gì? Nó là các cờ (flag) điều khiển, thông báo rằng bạn muốn thực hiện pattern của mình như thế nào đối với dữ liệu đầu vào. Ví dụ, bạn muốn tìm kiếm tất cả các ký tự từ a-z bao gồm cả hoa và thường, thì bạn có thể sử dụng pattern [a-zA-Z]. Nhưng bạn có thể rút ngắn pattern của mình bằng cách sử dụng modifier i(nsensitive) như sau: /[a-z]+/i.
g: global. Tìm kiếm từ đầu cho đến cuối. Gặp kết quả thì trả ra và tiếp tục chứ không dừng lại.m: multiple-line. Tìm kiếm trên nhiều dòng. Sử dụng^và$để tìm kiếm pattern đó trên mỗi dòng chứ không phải là tìm kiếm từ vị trí bắt đầu đến kết thúc của một chuỗi.i: insensitive. Bỏ qua phân biệt hoa thường.x: extended. Sử dụng để viết comment trong pattern.

X: eXtra. Khi bạn sử dụng modifier này thì ký tự sau dấu\(escape) mà là một ký tự đặc biệt thì sẽ không được escape nữa mà sẽ báo lỗi.

s: single-line. Hay còn gọi là DOTALL. Sử dụng modifier này khi bạn muốn tìm kiếm tất cả, bao gồm cả dấu xuống dòng (newline). Bạn có thể xem ảnh ví dụ để hiểu rõ hơn


U: Ungreedy. Modifier này đảo ngược lại quá trình tìm kiếm của quantifier+, hay còn gọi là tắt bỏ tính năng mặc định của modifier này. Khi bạn muốn bật nó lên trong lúc sử dụng modifier này thì bạn chỉ cần thêm?là được. Modifier này khá là khó giải thích. Nên mình sẽ sử dụng hình ảnh để minh họa nhé!




Lời kết
Trong bài viết ngăn này, mình giới thiệu đơn giản về các tokens và các modifier được RegEx hỗ trợ. Nhưng không phải ngôn ngữ nào cũng sử dụng giống nhau, vì vậy bạn cũng nên tìm hiểu xem ngôn ngữ bạn đang sử dụng có hỗ trợ modifier hay tokens đó hay không trước khi sử dụng nhé. Ví dụ như modifier g(lobal) được hỗ trợ bởi JavaScript nhưng trong PHP thì lại không !
Bài viết của mình đến đây xin được phép kết thúc. Hy vọng bài viết này sẽ có ích với bạn !
Original post: https://namnv609.cf/posts/regular-expression-reference.html
All rights reserved
