Redis và những điều chưa biết
Các kiểu dữ liệu trong Redis
1. String
Nó có thể lưu trữ văn bản, số nguyên, hoặc số thực.
Đặc điểm:
- 512MB
- Lưu thông tin người dùng, bộ đếm, token
RedisTemplate<String, String> redisTemplate;
redisTemplate.opsForValue().set(key, value);
redisTemplate.opsForValue().get(key);
SET user:1:name "Alice" # Lưu tên người dùng
SET user:1:age 30 # Lưu tuổi người dùng
INCR user:1:age # Tăng tuổi lên 1
GET user:1:age # Kết quả: 31
2. Hash
Hash lưu trữ các cặp field-value, tương tự như một đối tượng hoặc bản ghi trong cơ sở dữ liệu.
Đặc điểm:
- Lưu thông tin nhóm
- 1 Hash chứa tối đa 2^32 field
RedisTemplate<String, Object> redisTemplate;
public void saveHash(String key, Map<String, Object> data) {
redisTemplate.opsForHash().putAll(key, data);
}
public Map<Object, Object> getHash(String key) {
return redisTemplate.opsForHash().entries(key);
}
public Object getHashField(String key, String field) {
return redisTemplate.opsForHash().get(key, field);
}
HSET user:2 name "Bob" age 25 email "bob@example.com" # Lưu thông tin người dùng
HGET user:2 name # Kết quả: "Bob"
HGETALL user:2 # Kết quả: tất cả thông tin
HDEL user:2 email # Xóa email khỏi hash
3. List
List là một danh sách các giá trị được sắp xếp theo thứ tự (FIFO hoặc LIFO).
Ứng dụng: Quản lý công việc theo hàng đợi, xử lý yêu cầu tuần tự.
Đặc điểm:
- Có thể sử dụng stack or queue
- 2^32 phần tử
RedisTemplate<String, String> redisTemplate;
redisTemplate.opsForList().leftPush(key, value);
public List<String> getList(String key) {
return redisTemplate.opsForList().range(key, 0, -1);
}
LPUSH tasks "task1" "task2" # Thêm vào đầu danh sách
RPUSH tasks "task3" # Thêm vào cuối danh sách
LRANGE tasks 0 -1 # Lấy tất cả phần tử (Kết quả: task2, task1, task3)
LPOP tasks # Lấy và xóa phần tử đầu tiên (task2)
4. Set
Set là một tập hợp các giá trị duy nhất, không có thứ tự.
Ứng dụng: Lưu trữ danh sách tag, người theo dõi (followers), hoặc quyền truy cập.
Đặc điểm:
- Lưu dữ liệu không trùng nhau
- Hỗ trợ các thao tác toán học trên tập hợp (union, intersection, difference).
RedisTemplate<String, String> redisTemplate;
redisTemplate.opsForSet().add(key, value);
public Set<String> getSet(String key) {
return redisTemplate.opsForSet().members(key);
}
SADD tags "redis" "database" "nosql" # Thêm các tag
SMEMBERS tags # Lấy tất cả phần tử
SREM tags "nosql" # Xóa phần tử "nosql"
Thời gian sống của key trong Redis
TTL - Time To Live Có các tính năng:
- Set thời gian sống cho key
- Đặt thời gian sống với mốc thời gian
- Kiểm tra thời gian sống
- Loại bỏ TTL khỏi key
Thông thường ta chỉ set thời gian sống cho key. Nhưng trong dự án tôi đã tìm hiểu được thêm cách có thể set thời gian cho từng field trong dữ liệu Hash.
Đó là sử dụng RMapCache (tức là đang dùng Redisson làm client Redis),
- Lưu trữ Map trong Redis
- Hỗ trợ expire từng key-value riêng biệt nếu cần
- Hoạt động như một ConcurrentMap
// Tạo RMapCache<String, Object> với key là KeyCha
RMapCache<String, Object> cacheMap = redissonClient.getMapCache("KeyCha"); // getMapCache("KeyCha") chỉ lấy về 1 cầu nối (proxy) tới cái KeyCha trong Redis.
// Trong KeyCha, bạn lưu tiếp 1 cấp key là KeyCon → value là 1 Map<String, String>
// 1. Tạo map cho KeyCon
Map<String, String> keyConMap = new HashMap<>();
KeyConMap.put("key1", "value1");
keyConMap.put("key2", "value2");
// 2. Đưa KeyCon vào KeyCha
cacheMap.put("KeyCon", keyConMap); // Khi put("KeyCon", value), nếu KeyCha chưa có → Redis tự tạo Hash.
Redisson sẽ gửi một lệnh đến Redis: HSET KeyCha KeyCon serialized(keyConMap).
- Nếu "KeyCha" chưa tồn tại → tự động tạo mới 1 Redis Hash tên "KeyCha", rồi thêm field "KeyCon".
- Nếu "KeyCha" đã tồn tại → thêm hoặc cập nhật field "KeyCon" trong đó.
// Lấy lại
Map<String, String> KeyCon = (Map<String, String>) cacheMap.get("KeyCon"); // Khi get("KeyCon"), nếu field "KeyCon" không tồn tại → trả null, không lỗi.
Ghi chú:
cacheMaptồn tại trong Redí như một Map lớn (HSET)KeyControng đó lại là 1 đối tượng kiểu Map<String, String>, sẽ được Redisson serialize (ví dụ bằng JSON hoặc codec nào bạn config)
Nếu bạn cần đặt expire cho từng field, bạn có thể dùng:
loanParamMap.put("KeyCon", keyConMap, 10, TimeUnit.MINUTES);
Khi các field hết thời gian thì key cũng bị xóa.
- Redis gốc không hỗ trợ TTL riêng cho từng field trong Hash.
- Với RedisTemplate, bạn có thể:
- Lưu từng field dưới dạng key riêng (đơn giản nhất).
- Sử dụng Sorted Set để quản lý TTL, kết hợp với logic tùy chỉnh.
- Nếu dự án yêu cầu TTL cho từng field mà không muốn triển khai logic phức tạp, nên cân nhắc dùng Redisson với RMapCache.
Khuyến cáo: không nên dùng RMapCache, vì sẽ rất tốn CPU của redis khi phải mã hóa value trước khi push redis.
Redis có giống Kafka không?
| Yếu tố | Redis Pub/Sub | Kafka |
|---|---|---|
| Yêu cầu lưu trữ lịch sử tin nhắn | Không cần | Cần lưu trữ để phân tích hoặc tái xử lý |
| Độ trễ | Thấp (real-time) | Thấp, nhưng cao hơn Redis do ghi vào đĩa |
| Quy mô | Quy mô nhỏ, đơn giản | Quy mô lớn, phức tạp |
| Độ tin cậy | Không đảm bảo độ tin cậy | Đảm bảo độ tin cậy (tin nhắn không mất) |
| Sử dụng tài nguyên | RAM | RAM + Disk |
| Khả năng mở rộng | Hạn chế | Mở rộng tốt |
Các mô hình triển khai Redis
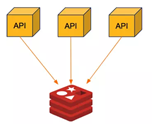
1. Mô hình đơn:
Mô hình đơn là mô hình triển khai đơn giản nhất với 1 node lưu toàn bộ dữ liệu:
- Ưu điểm: Chi phí thấp, vẫn đảm bảo hiệu suất cao với ứng dụng nhỏ.
- Nhược điểm: Không có tính dự phòng.
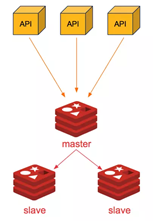
2. Mô hình Master-Slave
Mô hình Master-Slave rất quen thuộc trong triển các hệ thống cơ sở dữ liệu. Master-Slave nâng cấp hơn so với mô hình đơn khi có các 1 hoặc nhiều node Slave dự phòng. Có thể cho node Master làm node chuyên write và Slave chuyên read để chia tải.
- Ưu điểm: Có dữ liệu dự phòng, khi node Master gặp vấn đề có thể chuyển 1 node Slave thành Master (cấu hình thủ công), có khả năng chia tải.
- Nhược điểm: Khi chuyển 1 node Slave thành Master cần cấu hình thủ công, có độ trễ khi dữ liệu đồng bộ từ Master xuống Slave.
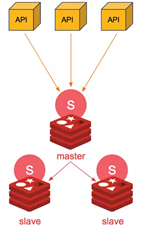
3. Mô hình Sentinel
Mô hình Sentinel gần như giống với Master-Slave và nâng cấp thêm ở việc tự động bầu chọn node nào sẽ là Master khi Master bị chết.
- Ưu điểm: Có dữ liệu dự phòng, khi node Master gặp vấn đề có thể tư động bầu chọn 1 node Slave thành Master, có khả năng chia tải.
- Nhược điểm: Tốn tài nguyên, có độ trễ khi dữ liệu đồng bộ từ Master xuống Slave.
4. Mô hình Cluster
Đây là mô hình chính chúng ta sẽ tìm hiểu trong bài viết này, cũng là mô hình triển khai đạt được hiệu quả tốt nhất đối với hệ thống lớn ở thời điểm hiện tại. Cụ thể thế nào, chúng ta sẽ làm rõ ở phần tiếp theo.
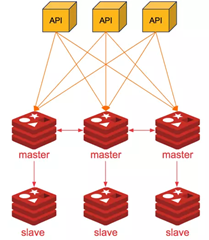
Mô Hình Cluster
Redis Cluster là một hệ thống gồm nhiều node master hoạt động song song. Mỗi master chịu trách nhiệm đọc và ghi một phần dữ liệu của toàn bộ cụm. Ngoài ra, mỗi master có thể đi kèm với một hoặc nhiều node slave để lưu trữ bản sao dự phòng, giúp bảo vệ dữ liệu khi có sự cố xảy ra. Một điểm cần lưu ý là, Redis Cluster chỉ sử dụng một cơ sở dữ liệu duy nhất (DB 0), nghĩa là bạn không thể chuyển đổi giữa các database như khi dùng Redis đơn lẻ.
1. Tư tưởng của Redis Cluster
Theo định lý CAP, không thể đồng thời có tính nhất quán và khả dụng tuyệt đối trong một hệ thống phân tán. Redis Cluster được thiết kế để đạt được sự cân bằng giữa tính nhất quán và khả dụng ở mức chấp nhận được, đảm bảo hệ thống luôn duy trì được hoạt động ổn định, chịu lỗi tốt và cho hiệu năng cao.
Một điểm đặc biệt của Redis Cluster là không có một máy chủ trung gian (proxy). Mỗi node đều biết được vị trí chứa dữ liệu của các key và sẽ hướng dẫn client trực tiếp đến node đó.
Mặc dù Redis Cluster không phù hợp với mọi trường hợp, nhưng với đa số ứng dụng sử dụng Redis, nó là một giải pháp hợp lý và hiệu quả.
2. Khả năng mở rộng theo chiều ngang (Horizontal Scalability)
Redis Cluster chia dữ liệu thành 16,384 Hash Slots. Mỗi master node chịu trách nhiệm quản lý một số lượng nhất định các hash slot này, mỗi slot chứa một tập hợp các key được xác định thông qua một thuật toán băm.
Nếu bạn cần các key liên quan nằm chung một hash slot để thực hiện các truy vấn liên quan đến nhiều key, bạn có thể sử dụng Hash Tags. Cách băm key và sử dụng Hash Tags sẽ được trình bày chi tiết ở phần sau.
Cách phân chia dữ liệu này cho phép mở rộng hệ thống bằng cách thêm các master node vào cụm. Khi có thêm node, các hash slot có thể được phân bổ lại một cách tự động, nhờ vào cấu hình cụm được chia sẻ giữa tất cả các node. Vì Redis Cluster có 16,384 hash slot, về lý thuyết bạn có thể có tối đa 16,384 master node.
3. Tính sẵn sàng cao (High Availability)
Trước khi có Redis Sentinel, các nhà phát triển phải tự xây dựng hệ thống để đảm bảo khả năng hoạt động liên tục (High Availability - HA). Với Sentinel, Redis đã tích hợp sẵn tính năng này. Trong Redis Cluster, mỗi master node có thể đi kèm với một hoặc nhiều slave node (tương tự như cụm Sentinel).
Khi master gặp sự cố, các slave sẽ tự động được bầu chọn để nâng cấp thành master mới. Quá trình này diễn ra qua một cổng giao tiếp riêng giữa các node, giúp hệ thống có thêm thời gian để quản trị viên kiểm tra và khắc phục sự cố. Hệ thống chỉ gặp rủi ro cao khi một master bị hỏng mà không có slave dự phòng.
4. Hiệu năng
Redis Cluster ưu tiên hiệu năng cao cho các thao tác đọc và ghi. Một số điểm chính:
- Đồng bộ bất đồng bộ: Dữ liệu được đồng bộ từ master sang slave một cách bất đồng bộ qua một cổng riêng, giúp giảm độ trễ trong giao tiếp với client.
- Không thực hiện merge dữ liệu: Khi có sự khác biệt giữa các phiên bản dữ liệu, phiên bản mới nhất luôn được ưu tiên, tránh việc so sánh và hợp nhất dữ liệu gây lỗi.
- Ưu tiên hiệu năng: Một số trường hợp, dữ liệu trên slave có thể bị thiếu nếu có lỗi xảy ra trong quá trình đồng bộ, nhưng điều này được chấp nhận để đảm bảo hiệu năng của hệ thống.
5. The Cluster Bus
Redis Cluster không chỉ mở một cổng để giao tiếp với client như thường lệ mà còn cần mở thêm một cổng phụ để các node trao đổi thông tin với nhau – giống như mạng lưới điện trong thành phố. Cổng này mặc định được tính bằng cách lấy cổng client cộng thêm 10000, hoặc có thể được cấu hình lại trong file redis.conf.
Ví dụ 1: Nếu Redis lắng nghe kết nối client trên cổng 6379 và bạn không thay đổi cài đặt, thì cổng bus sẽ là 16379 (6379 + 10000).
Ví dụ 2: Nếu Redis lắng nghe kết nối client trên cổng 6379 và bạn đặt cổng bus là 20000 trong redis.conf, thì cổng bus sẽ mở trên 20000.
Giao tiếp giữa các node diễn ra qua “Cluster bus protocol” – một giao thức binary riêng của Redis. Dữ liệu được truyền theo các frame với loại và kích cỡ khác nhau. Vì giao thức này chỉ phục vụ mục đích trao đổi thông tin giữa các node nên không có tài liệu chính thức cho việc phát triển phần mềm dựa trên nó. Để hiểu rõ hơn, bạn cần xem mã nguồn trong các file cluster.h và cluster.c.
6. Hash Slot
Như đã đề cập ở phần Khả năng mở rộng theo chiều ngang, Redis chia dữ liệu thành 16,384 phần gọi là hash slot. Các hash slot này được dùng để phân bố các key trên toàn bộ cluster. Mỗi node sẽ xử lý một tập hợp các hash slot và có thể có thêm một hoặc nhiều bản sao trên các node slave.
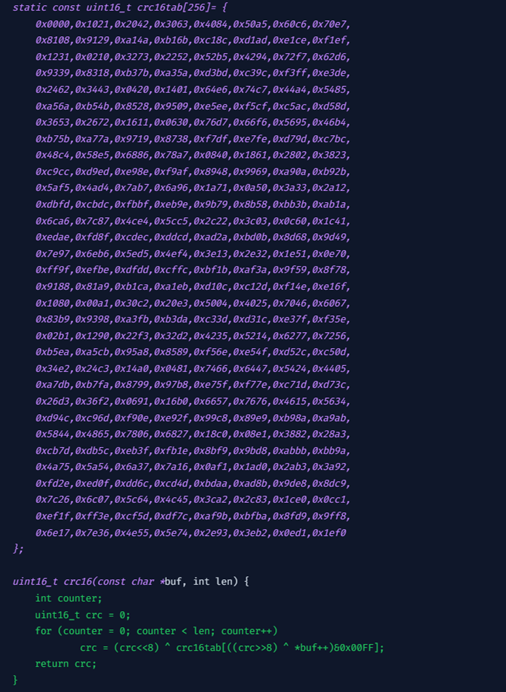
Thuật toán ánh xạ một key vào hash slot:
HASH_SLOT = CRC16(key) mod 16384
- CRC16: Là một hàm băm tạo ra một giá trị kiểm tra (checksum) cho chuỗi bit của key, giúp dò lỗi khi dữ liệu được truyền qua mạng hoặc lưu trữ.
- Quá trình: Hàm băm CRC16 chia lấy dư chuỗi bit của key với một số bit có độ dài 16 bit. Mặc dù kết quả đầu ra có 16 bit, Redis chỉ sử dụng 14 bit trong số đó. Sau đó, kết quả được lấy phần dư khi chia cho 16384 để xác định hash slot tương ứng.
Các thử nghiệm cho thấy hàm băm CRC16 của Redis phân phối các key đều trên 16,384 hash slot, đảm bảo cân bằng tải hiệu quả. Lý thuyết cho phép có tới 16,384 master node trong cluster, tuy nhiên kích thước tối đa được đề xuất là khoảng 1,000 node.
7. Thao tác đa phím (Multi-keys operations)

 Multi-keys operations là những thao tác làm việc với nhiều key cùng lúc. Ví dụ:
Multi-keys operations là những thao tác làm việc với nhiều key cùng lúc. Ví dụ:
MSET: ghi nhiều key trong một lệnhMGET: đọc nhiều key cùng lúcSUNION: lấy hợp của nhiều tập hợp (sets)- Hoặc một khối lệnh
MULTI ... EXECthao tác với nhiều key khác nhau
Tuy nhiên, khi sử dụng Redis Cluster, có một hạn chế quan trọng:
Bạn không thể thực hiện các Multi-keys operations nếu các key không nằm trong cùng một hash slot. Trong trường hợp này, Redis sẽ báo lỗi
CROSSSLOT.
Ví dụ về lỗi CROSSSLOT Giả sử bạn có hai key:
- mykey1 nằm ở slot 650
- mykey2 nằm ở slot 8734
Khi bạn thực hiện:
SUNION mykey1 mykey2
Redis sẽ báo lỗi:
CROSSSLOT Keys in request don't hash to the same slot
Giải pháp: Hash Tags
Redis hỗ trợ một cơ chế gọi là Hash Tags để giải quyết vấn đề này.
Hash Tag là gì? Hash tag cho phép bạn chỉ định phần nào của key sẽ được dùng để tính toán vị trí (hash slot) lưu trữ. Bạn sử dụng một cặp dấu ngoặc nhọn { } để đánh dấu phần này.
Giả sử bạn lưu trữ thông tin người dùng:
MSET user:1000.name Angela user:1000.age 20
Redis sẽ tính hash slot cho từng key dựa trên toàn bộ chuỗi key:
- user:1000.name → slot A
- user:1000.age → slot B
Nếu 2 key rơi vào slot khác nhau → bạn không thể dùng Multi-keys operations.
Cách khắc phục: Sử dụng hash tag:
MSET {user:1000}.name Angela {user:1000}.age 20
Lúc này, Redis chỉ dùng phần trong dấu ngoặc nhọn {user:1000} để tính toán:
- Cả hai key sẽ cùng nằm trên một slot duy nhất
- Bạn có thể thực hiện
MGET,SUNION,MULTI ... EXECthoải mái
Lưu ý khi sử dụng Hash Tag
- Lập trình viên cần quyết định cẩn thận: nên lưu dữ liệu nào cùng slot để phục vụ cho các Multi-keys operations.
- Không nên cố nhét toàn bộ dữ liệu vào một slot, vì điều này có thể làm mất cân bằng hệ thống.
- Cần đánh đổi giữa:
- Tối ưu hóa truy vấn đa key
- Cân bằng dữ liệu giữa các node trong Redis Cluster
8. MOVED Redirection
Khi một client kết nối đến Redis Cluster, nó có thể gửi truy vấn tới bất kỳ node nào trong cụm, bao gồm cả node chính (master) và node bản sao (replica).
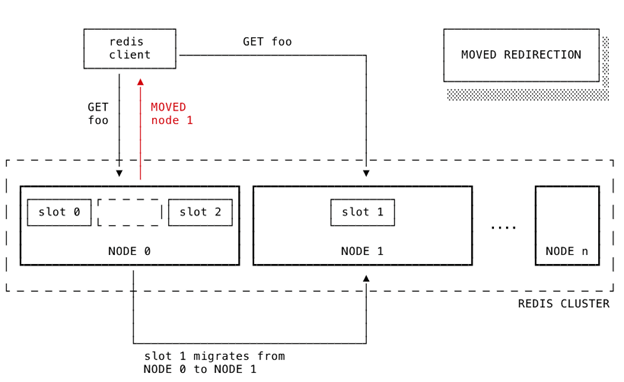
Redis xử lý truy vấn từ client như thế nào?
- Node nhận truy vấn sẽ phân tích nội dung truy vấn:
- Nếu truy vấn hợp lệ (chỉ chứa 1 key hoặc nhiều key nằm trong cùng một hash slot), node sẽ tra cứu xem node nào chịu trách nhiệm với hash slot đó.
- Nếu node hiện tại đang quản lý slot đó:
- Truy vấn sẽ được xử lý trực tiếp và kết quả trả về cho client.
- Nếu slot đó thuộc về một node khác:
- Node hiện tại sẽ trả về một thông báo MOVED cho client.
MOVED Redirection là gì? Khi một key không nằm trên node được truy vấn, Redis sẽ trả về thông báo MOVED, ví dụ:
MOVED 3999 127.0.0.1:6381
Thông tin này bao gồm:
- Hash slot của key: 3999
- Địa chỉ node đang nắm giữ slot đó: 127.0.0.1:6381
Sau khi nhận được MOVED, client sẽ:
- Gửi lại truy vấn đến node chính xác mà Redis chỉ định (ở ví dụ trên là 127.0.0.1:6381)
Trường hợp gặp nhiều lần MOVED Trong một số trường hợp hiếm, client có thể nhận liên tiếp nhiều thông báo MOVED, nguyên nhân là:
- Trong quá trình xử lý lại truy vấn (sau khi nhận MOVED), Redis Cluster có thể thay đổi cấu hình (ví dụ: hash slot được di chuyển sang node khác).
- Khi đó, node mới được truy vấn lại không còn nắm giữ hash slot ban đầu, và trả về một thông báo MOVED khác → client sẽ tiếp tục chuyển hướng.
Cách client tối ưu truy vấn trong Redis Cluster Để giảm thiểu việc liên tục nhận MOVED, client có thể ghi nhớ vị trí của các hash slot:
- Sau khi nhận được MOVED, client ghi nhớ:
slot 3999 hiện nằm ở node 127.0.0.1:6381
- Redis cung cấp các lệnh cho phép client đồng bộ hóa toàn bộ sơ đồ phân phối slot:
- CLUSTER SLOTS
- CLUSTER SHARDS (áp dụng Redis >= 7.0)
Nhờ đó, client có thể cache sơ đồ cluster và phân phối truy vấn hiệu quả hơn, giảm tối đa số lần bị redirect.
Tóm tắt luồng hoạt động:
Client → gửi truy vấn đến node bất kỳ
↓
Node kiểm tra slot chứa key:
→ nếu đúng slot → xử lý
→ nếu sai slot → trả về MOVED
↓
Client nhận MOVED → gửi lại truy vấn đến node được chỉ định
↓
Lưu lại thông tin slot → tối ưu cho các truy vấn sau
9. Client Connections And Redirection Handling
Để đạt hiệu suất tối ưu trong Redis Cluster, client nên lưu trữ (cache) thông tin ánh xạ giữa các hash slot và các node. Điều này giúp giảm thiểu số lần nhận thông báo MOVED và tăng tốc độ truy vấn.
Hai phương pháp cập nhật thông tin slot-node:
1 . Cập nhật từng phần (Incremental update) Sau khi nhận MOVED redirection, client có thể cập nhật riêng lẻ thông tin slot vừa được chuyển hướng mà không cần load lại toàn bộ cấu hình.
-
Ưu điểm: Hiệu suất tốt, chỉ cập nhật khi cần thiết.
-
Nhược điểm: Nếu nhiều truy vấn diễn ra đồng thời, có thể gây ra cạnh tranh ghi (write contention) giữa các luồng cùng sửa đổi bảng ánh xạ slot-node, dẫn đến dữ liệu không đồng bộ hoặc lỗi.
2 . Cập nhật toàn bộ (Full update) Trong một số tình huống, client nên cập nhật lại toàn bộ cấu hình Redis Cluster để đảm bảo dữ liệu ánh xạ luôn chính xác.
Các tình huống nên thực hiện full update:
- Khi client khởi động lần đầu
- Khi client nhận được thông báo
MOVED - Khi hệ thống phát hiện slot không có node nào đảm nhiệm
Cập nhật cấu hình toàn bộ qua CLUSTER SLOTS
Client có thể sử dụng lệnh Redis sau để lấy thông tin toàn bộ ánh xạ slot-node:
CLUSTER SLOTS
Kết quả trả về sẽ là một mảng JSON hai chiều, mỗi phần tử đại diện cho một range các slot:
[
[startSlot, endSlot, masterNode, replicaNode1, replicaNode2, ...],
...
]
Ví dụ:
[
[0, 5460, ["127.0.0.1", 6379], ["127.0.0.1", 7380]],
[5461, 10922, ["127.0.0.1", 6380]],
[10923, 16383, ["127.0.0.1", 6381], ["127.0.0.1", 7382]]
]
Giải thích:
- startSlot và endSlot: Phạm vi slot mà node phụ trách.
- masterNode: Node chính chịu trách nhiệm xử lý.
- replicaNodeX: Các node bản sao (replica) phục vụ cho HA (High Availability).
Lưu ý khi ánh xạ slot-node:
- Redis có 16384 slot (từ 0 đến 16383).
- Client cần đảm bảo ánh xạ đủ toàn bộ 16384 slot.
- Với những slot không được node nào quản lý, client nên:
- Gán giá trị null hoặc undefined cho slot đó.
- Nếu truy vấn key rơi vào slot chưa được ánh xạ, client nên:
- Gọi lại CLUSTER SLOTS để cập nhật.
- Nếu slot vẫn không được gán → báo lỗi cho ứng dụng (ví dụ: "Slot 8456 không được quản lý bởi bất kỳ node nào").
10. Publish/Subscribe
Redis như một Message Broker
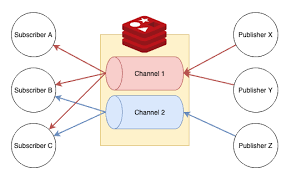
Ngoài vai trò lưu trữ dữ liệu dạng key-value, Redis còn được sử dụng như một message broker hiệu quả, đặc biệt trong các kiến trúc hệ thống phân tán. Redis cung cấp các mô hình messaging như:
- Pub/Sub (Publish/Subscribe)
- Streams (kể từ Redis 5.0)
- Và từ Redis 7.0 trở đi: Sharded Pub/Sub
Phần này mình chưa dùng bao giờ nên thôi để bảng tóm tắt, ai muốn tìm hiểu thêm thì tìm trên google nhé.
| Pub/Sub truyền thống | Sharded Pub/Sub |
|---|---|
| Message phát tán toàn cụm | Chỉ phát tán trong node nhóm phụ trách slot |
| Không có scale out tốt | Scale out hiệu quả trong cluster |
| Không kiểm soát slot | Gán channel vào slot dựa trên CRC16 |
| Không lưu message | Message ephemeral (vẫn không lưu), nhưng có kiểm soát hơn |
11. Kết luận
- Redis Cluster là một giải pháp có tính sẵn sàng cao và khả năng mở rộng theo chiều ngang, phù hợp với các hệ thống phân tán quy mô lớn.
- Redis không sử dụng proxy server ở giữa, giúp tránh được nguy cơ điểm lỗi đơn (SPOF – Single Point of Failure) gây gián đoạn giao tiếp giữa client và server.
- Dù Redis Cluster không đảm bảo tính khả dụng và nhất quán tuyệt đối (CAP Theorem), nhưng vẫn cung cấp mức độ tin cậy cao và đáp ứng tốt cho phần lớn các bài toán thực tế.
- Các node trong cụm giao tiếp qua một cổng riêng sử dụng Cluster Bus, đảm bảo cập nhật trạng thái và phân phối message nội bộ nhanh chóng.
- Dữ liệu được phân chia dựa trên 16384 hash slot, sử dụng thuật toán băm CRC16 để ánh xạ key vào slot, giúp đảm bảo sự phân phối đồng đều.
- Hash tag cho phép nhóm nhiều key vào cùng một slot, từ đó hỗ trợ thao tác với nhiều key (multi-key operations) trong cluster.
- Khi client truy vấn sai node, Redis sẽ trả về MOVED redirection kèm theo node chính xác mà client nên truy vấn lại — cơ chế này đóng vai trò quan trọng trong việc định tuyến thông minh.
- Để giảm số lần chuyển hướng MOVED, client nên lưu và duy trì cấu hình slot-node. Có thể chọn cập nhật một phần khi có thay đổi, hoặc toàn bộ khi khởi động hay khi phát hiện lỗi.
- Từ Redis 7.0, Sharded Pub/Sub được giới thiệu, tối ưu hiệu suất pub/sub bằng cách giới hạn truyền tải message trong các node liên quan, giúp mở rộng quy mô Redis pub/sub hiệu quả hơn.
Ai đã đọc tới cuối này thì chia sẻ thêm 1 hệ thống thực tế đã và đang triển khai: (Xin phép các anh mờ xanh :v ) Vì phần này chứa cấu hình thực tế nên mình sẽ không để mục lục
Redis Cluster đang được ứng dụng trong hệ thống mobile ebanking với mục đính caching. Cụ thể là làm quản lý session, lưu trữ data tạm thời giảm thiểu truy vấn vào Database cũng như dữ liệu cần lấy từ các microservice khác, chia sẻ dữ liệu tạm thời cho các microservice khác trong hệ thống. Từ đó đem lại hiệu quả về tốc độ cho ứng dụng.
Redis client được sử dụng là Redisson (https://redisson.org) dành cho Java với phiên bản Redisson 3.16.0.
1 File cấu hình:
1.1 Cấu hình khi sử dụng Redis cluster
Để bật chết độ redis cluster ta cần cấu hình ở trong Database ebanking và trong file “conf”. Nếu trong file “conf” chưa có các config liên quan đến redis cluster. Hãy thêm các config sau vào file.
#Redis cluster
REDISSON_CLUSTER_MODE=ON
IDLE_CONNECTION_TIMEOUT=10000
REDISSON_CLUSTER_CONNECT_TIMEOUT=10000
REDISSON_CLUSTER_TIMEOUT=3000
REDISSON_CLUSTER_RETRY_ATTEMPTS=3
REDISSON_CLUSTER_RETRY_INTERVAL=1500
REDISSON_CLUSTER_FAILED_SLAVE_RECONNECTION_INTERVAL=3000
REDISSON_CLUSTER_FAILED_SLAVE_CHECK_INTERVAL=60000
REDISSON_CLUSTER_PASSWORD=<password>
REDISSON_CLUSTER_SUBSCRIPTIONS_PER_CONNECTION=5
# REDISSON_CLUSTER_CLIENT_NAME=
# REDISSON_CLUSTER_LOAD_BALANCER=org.redisson.connection.balancer.RoundRobinLoadBalancer
REDISSON_CLUSTER_SUBSCRIPTION_CONNECTION_MINIMUM_IDLE_SIZE=1
REDISSON_CLUSTER_SUBSCRIPTION_CONNECTIONPOOL_SIZE=100
REDISSON_CLUSTER_SLAVE_CONNECTION_MINIMUMIDLE_SIZE=10
REDISSON_CLUSTER_SLAVE_CONNECTION_POOLSIZE=128
REDISSON_CLUSTER_MASTER_CONNECTION_MINIMUM_IDLE_SIZE=10
REDISSON_CLUSTER_MASTER_CONNECTION_POOL_SIZE=128
REDISSON_CLUSTER_READ_MODE=SLAVE
REDISSON_CLUSTER_SUBSCRIPTION_MODE=SLAVE
REDISSON_CLUSTER_NODE_ADDRESSES=redis://11.2.40.90:6379|redis://11.2.40.90:6380|redis://11.2.40.90:6381|redis://11.2.40.90:6382|redis://11.2.40.90:6383|redis://11.2.40.90:6384|redis://11.2.40.90:6385|redis://11.2.40.90:6386|redis://11.2.40.90:16379|redis://11.2.40.90:26379
REDISSON_CLUSTER_SCAN_INTERVAL=1000
REDISSON_CLUSTER_PING_CONNECTION_INTERVAL=30000
REDISSON_CLUSTER_KEEP_ALIVE=false
REDISSON_CLUSTER_TCP_NO_DELAY=true
REDISSON_CLUSTER_THREADS=32
REDISSON_CLUSTER_NETTY_THREADS=64
REDISSON_CLUSTER_REFERENCE_ENABLED=true
REDISSON_CLUSTER_TRANSPORT_MODE=NIO
REDISSON_CLUSTER_LOCK_WATCHDOG_TIMEOUT=30000
REDISSON_CLUSTER_RELIABLE_TOPIC_WATCHDOG_TIMEOUT=600000
REDISSON_CLUSTER_KEEP_PUB_SUB_ORDER=true
REDISSON_CLUSTER_USE_SCRIPT_CACHE=false
REDISSON_CLUSTER_MIN_CLEANUP_DELAY=5
REDISSON_CLUSTER_MAX_CLEANUP_DELAY=1800
REDISSON_CLUSTER_CLEAN_UP_KEYS_AMOUNT=100
# REDISSON_CLUSTER_NETTY_HOOK=org.redisson.client.DefaultNettyHook
REDISSON_CLUSTER_USE_THREAD_CLASS_LOADER=true
# REDISSON_CLUSTER_ADDRESS_RESOLVER_GROUP_FACTORY=org.redisson.connection.DnsAddressResolverGroupFactory
Hãy đảm bảo REDISSON_CLUSTER_MODE có giá trị ON. Sau đó cần bật config redis cluster trong Database ebanking ở bảng SYS_PARAM với cd = REDIS_MODE và value = CLUSTER. Hoàn tất việc config chế độ cluster trên ứng dụng.
Các cấu hình quan trọng cần chú ý:
- REDISSON_CLUSTER_MODE: ON/OFF tương ứng với kết nối redis với cluster mode hay không? Nếu để OFF redis sẽ được kết nối với sentinel hoặc single phục thuộc vào các cấu hình khác.
- REDISSON_CLUSTER_NODE_ADDRESSES: Đây là sanh sách các code trong cụm với định dạng redis://ip:port viết liên tiếp và các nhau bởi ký tự “|”
- REDISSON_CLUSTER_PASSWORD: mật khẩu kết nối vào cụm. Ở đây hệ thống Redis Cluster đang cấu hình với không cần username nên username sẽ mặc định là null.
- Chúng ta có thể thêm cấu hình username bằng config REDISSON_CLUSTER_CLIENT_NAME
1.2 Cấu hình sử dụng Redis Sentinel
Để config ứng dụng sử dụng chế độ sentinel, trong file “config” đặt giá trị REDISSON_CLUSTER_MODE=OFF , REDISSON_MODE=MULTI
1.3 Cấu hình sử dụng Redis Single
Để config ứng dụng sử dụng chế độ centinel, trong file “config” đặt giá trị REDISSON_CLUSTER_MODE=OFF , REDISSON_MODE=SINGLE
2 Kết nối Redis cluster trong quá trình khởi động ứng dụng Spring Boot
Để Redis cluster kết nối với server khi khởi động ứng dụng chúng ta cần thêm annotation @PostConstruct trên hàm init – là hàm khởi tạo kết nối đến Redis server. Hàm này nằm trong class RedisServer là một bean:
Tiếp theo chúng ta cần thêm annotation @ComponentScan vào class Application khởi chạy ứng dụng. Tham số đầu vào basePackages = "com.mp.mapp.*" chỉ ra package Spring sẽ thực hiện quét khởi tạo.
3 Thao tác đọc ghi vào Redis
Thao tác đọc và ghi dữ liệu vào Redis được thực hiện thông qua đối tượng RedissonClient. Ví dụ về hàm đọc thông tin tài khoản của khách hàng kiểu String:
public static String getBalanceCached(String custId, String requestId, String hostCifId) {
if (Utility.isNull(hostCifId)) {
return null;
}
RBucket<String> balanceCachedMap = getRedisClient().getBucket(BALANCE_CACHED_MAP + Constant.HYPHEN + hostCifId);
return balanceCachedMap.get();
}
Ví dụ về hàm ghi thông tin tài khoản của khách hàng kiểu String:
public static void addBalanceCached(String custId, String requestId, String hostCifId,
String getNonSavingAccountListOutputStr) {
if (Utility.isNull(hostCifId)) {
return;
}
RBucket<String> balanceCachedMap = getRedisClient().getBucket(BALANCE_CACHED_MAP + Constant.HYPHEN + hostCifId);
balanceCachedMap.set(getNonSavingAccountListOutputStr, Constant.BALANCE_CACHED_TIMEOUT_SECOND, TimeUnit.SECONDS);
}
Tất cả các thao tác với Redis bao gồm cấu hình, kết nối, đọc, ghi có thể tham khảo trên trang chính thức của thư viện Redisson (https://redisson.org)
All rights reserved
