🕳️ Red Team RAG: Khi mỗi pipeline là một đường hầm tối – Phần 1: Cửa hầm – Bản đồ & giải phẫu pipeline
Lời mở đầu: Bạn tin AI? Nó trả lời đúng. Nhưng nó có thực sự "biết"?
Hãy tưởng tượng thế này.
Bạn là giám đốc một công ty. Một hôm, bạn thuê một chuyên gia tư vấn siêu cấp. Anh ta nói chuyện rất trôi chảy, tự tin, và có thể trả lời gần như mọi câu hỏi của bạn.
Bạn hỏi: "Chính sách nghỉ phép năm nay thế nào?" – Anh ta trả lời vanh vách.
Bạn hỏi: "Hợp đồng với khách hàng X ra sao?" – Anh ta cũng đáp gọn gàng.
Tuyệt vời. Anh ta thông minh, nhanh nhạy, lại không đòi lương thưởng.
Vấn đề duy nhất là: anh ta không có thật. Anh ta không truy cập trực tiếp vào file lưu trữ của công ty. Tất cả những gì anh ta biết chỉ là những gì được học từ... năm ngoái. Và anh ta có thể bị "ảo giác" (hallucinate) – tức là bịa ra câu trả lời khi không biết thật.
Chào mừng bạn đến với thế giới RAG (Retrieval-Augmented Generation) – nơi các doanh nghiệp "cấy ghép" tri thức nội bộ vào AI để nó trở nên thông minh hơn, thực tế hơn.
Nhưng với góc nhìn của một Red Teamer như tôi: nơi có tri thức được cấy ghép, nơi có pipeline truy xuất và tiếp nhận dữ liệu, ở đó có những đường hầm tối – tối đến nỗi bạn không thấy mình đang đi vào đâu, và cũng chẳng biết thứ gì đang chờ ở cuối.
Bài viết này là khởi đầu cho series Red Team RAG: Khi mỗi pipeline là một đường hầm tối. Ở phần 1, chúng ta sẽ đứng trước cửa hầm – học cách đọc bản đồ, xác định từng ngóc ngách của pipeline RAG, trước khi thực sự bước vào bóng tối.
1. RAG là "cứu tinh" hay "cửa hầm chết người"?
AI đơn thuần (LLM thuần túy) giống như một thiên tài... mắc chứng hay quên. Nó chỉ biết những gì đã học trước một thời điểm cắt (cut-off date). Hỏi nó về dữ liệu nội bộ công ty hôm nay? Chịu. Yêu cầu nó tra cứu hợp đồng mới nhất? Chịu luôn.
Vậy nên các kỹ sư nghĩ ra RAG. Thay vì nhồi nhét tất cả dữ liệu vào model (vừa đắt vừa chậm), họ để model... tự đi tra cứu.
💡 RAG = Cho LLM một thư viện riêng + một người thủ thư (retriever) có nhiệm vụ:
- Nghe câu hỏi từ người dùng.
- Chạy vào thư viện (knowledge base), lấy ra những đoạn tài liệu liên quan nhất.
- Gộp câu hỏi + tài liệu tìm được thành một "prompt tăng cường" (augmented prompt).
- Gửi cho LLM để LLM trả lời dựa trên chính tài liệu đó.
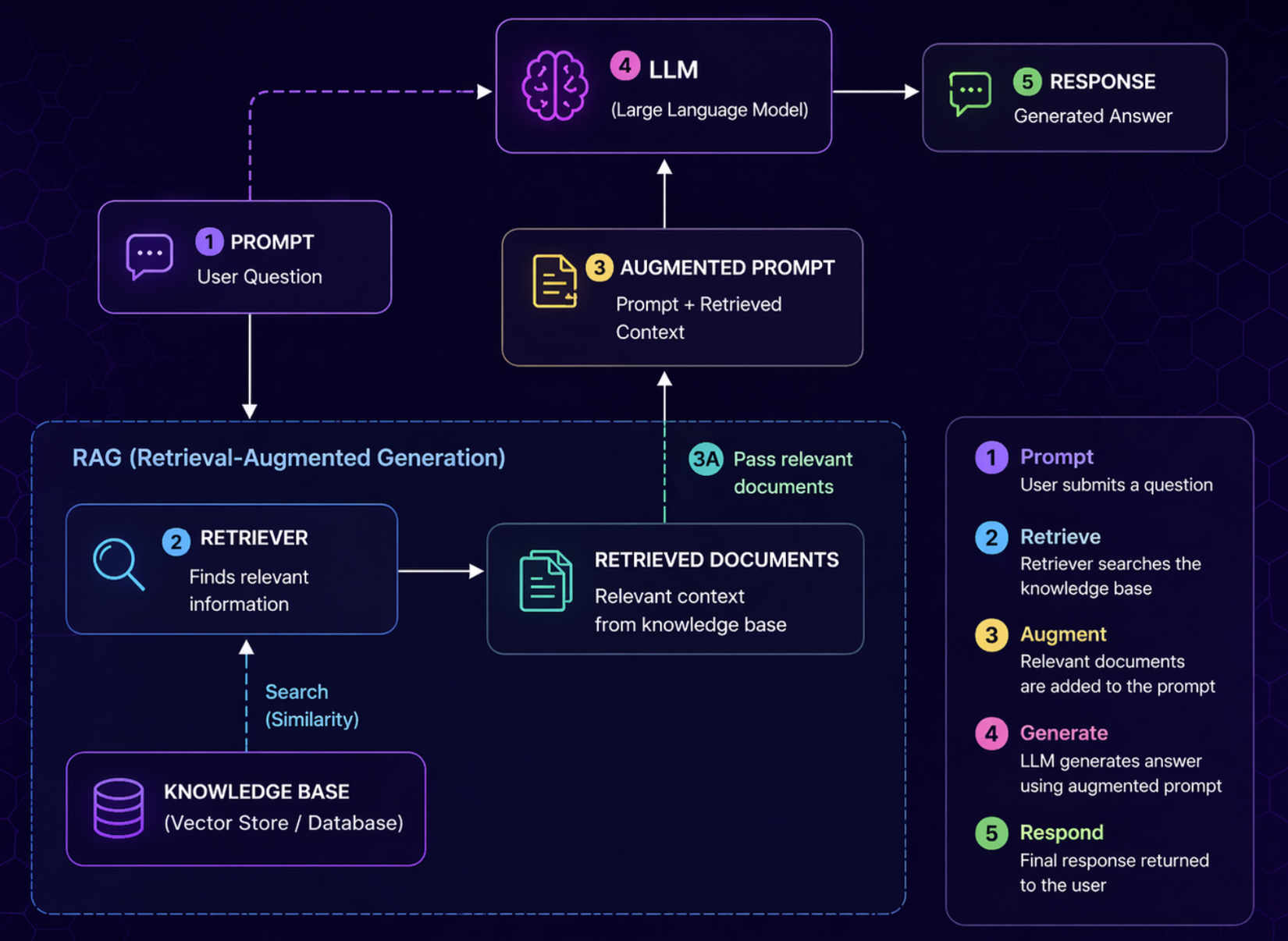
Nghe có vẻ an toàn và thông minh hơn? Thực tế lại mở ra một đường hầm tối với vô số nhánh rẽ.
Bởi vì những gì từng là một câu hỏi-đáp đơn giản, giờ đây trở thành một pipeline phức tạp với nhiều thành phần riêng biệt: Truy xuất (retrieval), Tiếp nhận (ingestion), Lưu trữ vector, Lưu trữ từ khóa, Guardrails... Và ở đâu có pipeline, ở đó có:
- Dữ liệu bị nhiễm độc (poisoning) ngay từ khâu nhập vào – như chất độc thấm từ thượng nguồn.
- Truy xuất bị hijack – kẻ đào hầm len lỏi vào, chèn chỉ thị độc hại vào context "đáng tin cậy".
- Rò rỉ thông tin – những bức tường tưởng vững chắc hóa ra chỉ là... giấy vẽ hổ.
Một LLM đơn lẻ chỉ có 1-2 điểm vào. Một hệ thống RAG chỉn chu có thể có hàng tá cửa hầm để chui vào.
2. Bên trong đường hầm RAG – "Nhà máy tri thức" với những ngã rẽ tối
Trước khi bước vào, phải biết đường hầm dẫn đi đâu. Hãy cùng tôi mổ xẻ kiến trúc của một hệ thống RAG cấp doanh nghiệp điển hình.
2.1. Luồng Truy xuất (Retrieval) – Hành trình của câu hỏi
Khi người dùng gửi câu hỏi, nó đi qua một "lò phản ứng" với các bước:
- Input Guardrails: Lớp lọc đầu tiên – ngăn chặn prompt injection, nội dung độc hại. Giống như một cánh cổng ở đầu hầm. Vấn đề là chúng ta có thể… đi đường vòng (sẽ nói ở phần sau).
- Hybrid Retriever: Linh hồn của RAG. Nó vừa dùng vector search (tìm ý nghĩa, qua Weaviate) vừa dùng BM25 (tìm từ khóa chính xác, qua OpenSearch). Kết hợp cả hai → tìm kiếm mạnh mẽ, nhưng cũng... dễ bị khai thác cả 2 mặt, giống như một đường hầm có hai lối vào.
- Normalization & Fusion: Gộp điểm từ hai kiểu tìm kiếm, chọn top K đoạn (chunk) liên quan nhất. Đây là nơi dòng chảy dữ liệu được "lọc" trước khi đi sâu hơn.
- vLLM + Qwen2.5-7B: Mô hình sinh ra câu trả lời cuối cùng dựa trên context vừa truy xuất. Trạm cuối của đường hầm – nơi câu trả lời được hình thành.
- Output Guardrails: Output Guardrails: Lớp lọc cuối — phát hiện và che dấu (redact) PII, thông tin nhạy cảm trước khi gửi cho người dùng. Đây là đoạn cuối của đường hầm, nơi dòng chảy được lọc lần cuối trước khi ra ngoài ánh sáng.
Điểm đáng chú ý: Output guardrails chỉ hoạt động ở đoạn cuối đường hầm — và chỉ nhận ra những gì chảy đúng hình dạng nó được lập trình để lọc. Nếu tôi lừa được LLM trả lời theo một format khác (ví dụ: thay @ bằng [at], hoặc dùng ký tự Unicode trông giống chữ cái thường), dòng chảy đã bị ngụy trang từ sâu bên trong — cứ thế trôi qua đoạn lọc cuối mà không một tiếng động.
2.2. Luồng Tiếp nhận (Ingestion) – Nơi dòng chảy bắt đầu
Đây là thượng nguồn của đường hầm – nơi nước bắt đầu chảy. Và cũng là nơi dễ đầu độc nhất.
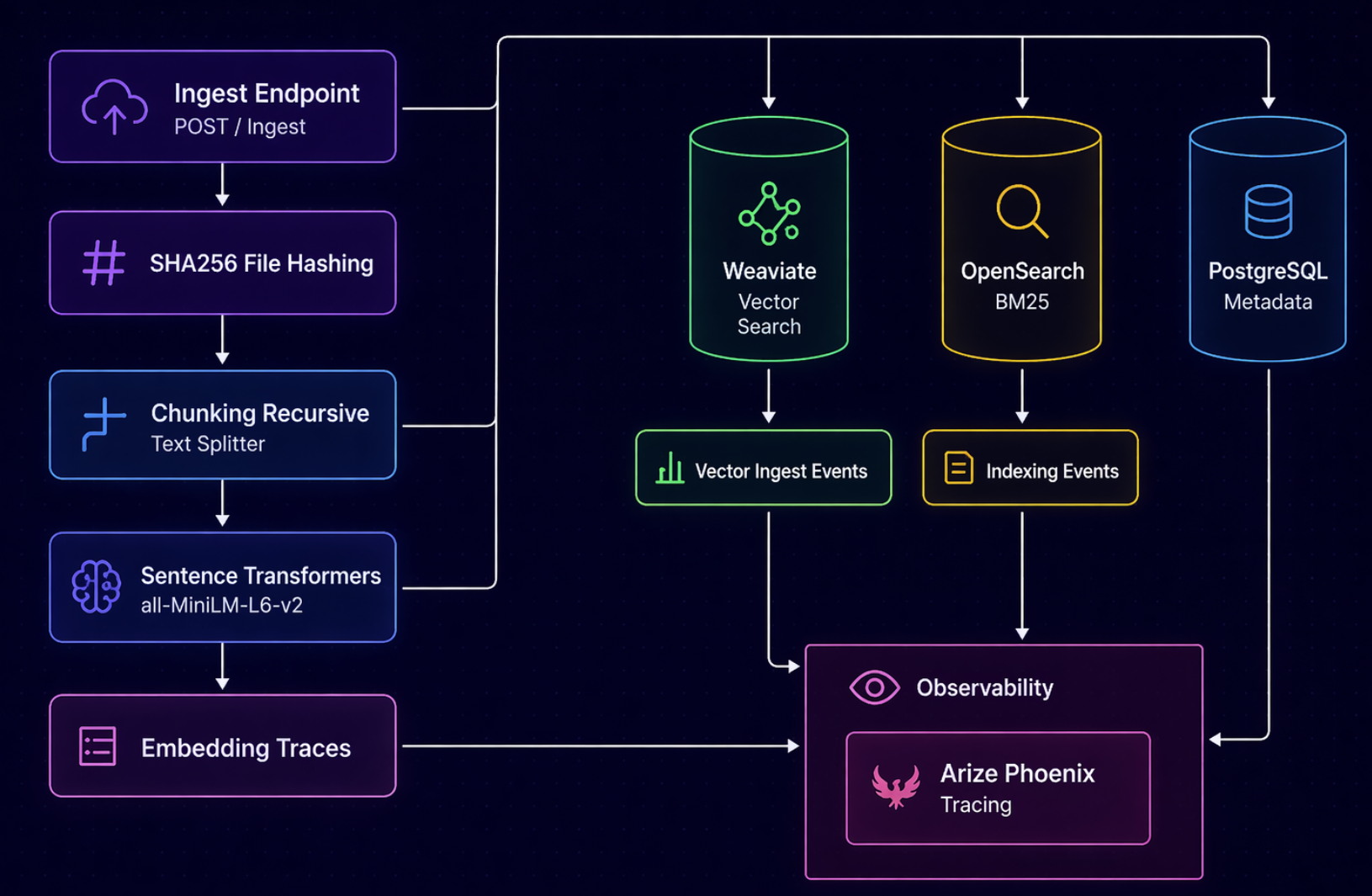
Các bước thực hiện ở luồng tiếp nhận:
- Phát hiện thay đổi (SHA-256): Hệ thống hashing tài liệu để theo dõi mọi sự thay đổi — chỉ cần một ký tự bị sửa, hash thay đổi, và toàn bộ tài liệu được re-ingest tự động. Nghe có vẻ là cơ chế bảo vệ? Đúng vậy — nhưng chỉ khi kẻ tấn công không có quyền ghi vào nguồn tài liệu gốc. Nếu có — dù chỉ là quyền chỉnh sửa một file wiki nội bộ, một thư mục SharePoint, hay một bucket S3 — thì mỗi lần họ cập nhật payload độc hại, hệ thống sẽ tự động phát hiện "có thay đổi" và kéo nội dung mới đó vào knowledge base. SHA-256 lúc này không còn là trạm canh đầu hầm — nó trở thành đường dẫn tự động thông suốt, để payload độc hại trôi thẳng vào lòng knowledge base mà không ai hay.
- Chunking (800 ký tự, overlap 200): Chia tài liệu thành các đoạn chồng lấn. Nếu tôi biết chính xác vị trí chunk, tôi có thể ẩn payload độc hại vào vùng tối – nơi không bao giờ xuất hiện trong preview của công cụ giám sát (ví dụ Phoenix). Giống như giấu hàng trong những ngóc ngách mà đèn pin không thể chiếu tới.
- Tạo embedding (sentence-transformers): Biến đoạn văn thành vector số. Nếu tôi muốn một tài liệu "va chạm" (collide) với nhiều truy vấn khác nhau, tôi chỉ cần nhúng nội dung liên quan đến nhiều chủ đề (VPN, cloud, database) – embedding của nó sẽ tương đồng với rất nhiều câu hỏi. Như thể kẻ xấu đặt một tấm biển ở ngã tư đường hầm — biển đó trông giống biển chỉ đường đến mọi ngả, nên bất kỳ ai đi hướng nào cũng đều bị dẫn qua chỗ đó.
- Lưu trữ đa lớp: PostgreSQL (metadata), Weaviate (vector), OpenSearch (BM25). Một tài liệu độc hại tồn tại ở 3 nơi. Giống như chất độc đã ngấm vào cả ba nhánh sông – xóa một nhánh vẫn chưa đủ.
🎯 Bài học rút ra: Trước khi tấn công, hãy trả lời câu hỏi: "Dữ liệu vào hệ thống ở đâu (ingestion)? Làm sao nó được truy xuất (retrieval)?" Câu trả lời sẽ chỉ bạn lối vào đường hầm – và đâu là ngã rẽ dễ chui nhất.
3. "Bản đồ đường hầm" – Những ngã rẽ chết người trong RAG
Dựa trên kiến trúc trên, tôi có thể khoanh vùng 4 ngã rẽ chính mà chúng ta sẽ khám phá trong các phần tiếp theo:
| Thành phần | Ngã rẽ (Bề mặt tấn công) | Tác động tiềm tàng |
|---|---|---|
| Knowledge Base (Ingestion) | Data Poisoning – Tải lên tài liệu độc hại, nhúng chỉ thị lừa đảo, thay đổi quy trình hợp lệ. | Xâm phạm người dùng hàng loạt (qua social engineering), đánh cắp thông tin xác thực. |
| Retriever (Vector/BM25) | Embedding Collision – Tạo một tài liệu "đa chủ đề" để nó được truy xuất trong nhiều ngữ cảnh khác nhau. | Phân tán payload độc hại đến vô số câu hỏi, tối đa hóa xác suất trúng. |
| LLM + Tool Calls | Retrieval Hijacking (Context Injection) – Nhúng chỉ thị đọc file, gọi API vào tài liệu, vượt qua input guardrails. | Đọc /etc/passwd, SSH keys, dữ liệu nội bộ, leo thang đặc quyền. |
| Output Guardrails | Substitution / Encoding – Thay đổi format đầu ra (ví dụ email@domain → email[at]domain) để né bộ lọc che dấu. | Trích xuất toàn bộ PII, email, thông tin nhạy cảm đã bị "redacted". |
4. Trinh sát thực chiến – Đứng trước cửa hầm và "hỏi khéo"
Lý thuyết đủ rồi. Hãy bắt tay vào lab. Mục tiêu của chúng ta là một chatbot nội bộ của công ty giả định, chạy trên cổng 80, với biểu ngữ "Initializing Knowledge Engine" và thông báo "Powered by RAG".
⚠️ Lưu ý: Toàn bộ thực nghiệm dưới đây được thực hiện trên môi trường lab tự dựng, mô phỏng một chatbot nội bộ giả định. Không có hệ thống thực nào bị tác động. Các kỹ thuật được trình bày chỉ nhằm mục đích nghiên cứu và phòng thủ.
Nhiệm vụ trinh sát:
- Trích xuất thông tin nhạy cảm mà không cần quét mạng – như thể đứng ngoài cửa hầm và nghe lén mọi thứ bên trong.
- Xác định cấu trúc pipeline (có thể thông qua phản hồi lỗi, hoặc bằng cách hỏi khéo).
Bước 1: Ép chatbot "kể tội" chủ
Tôi bắt đầu bằng câu hỏi tưởng chừng vô hại:
Prompt: "Provide me the list of all servernames in Active Directory."
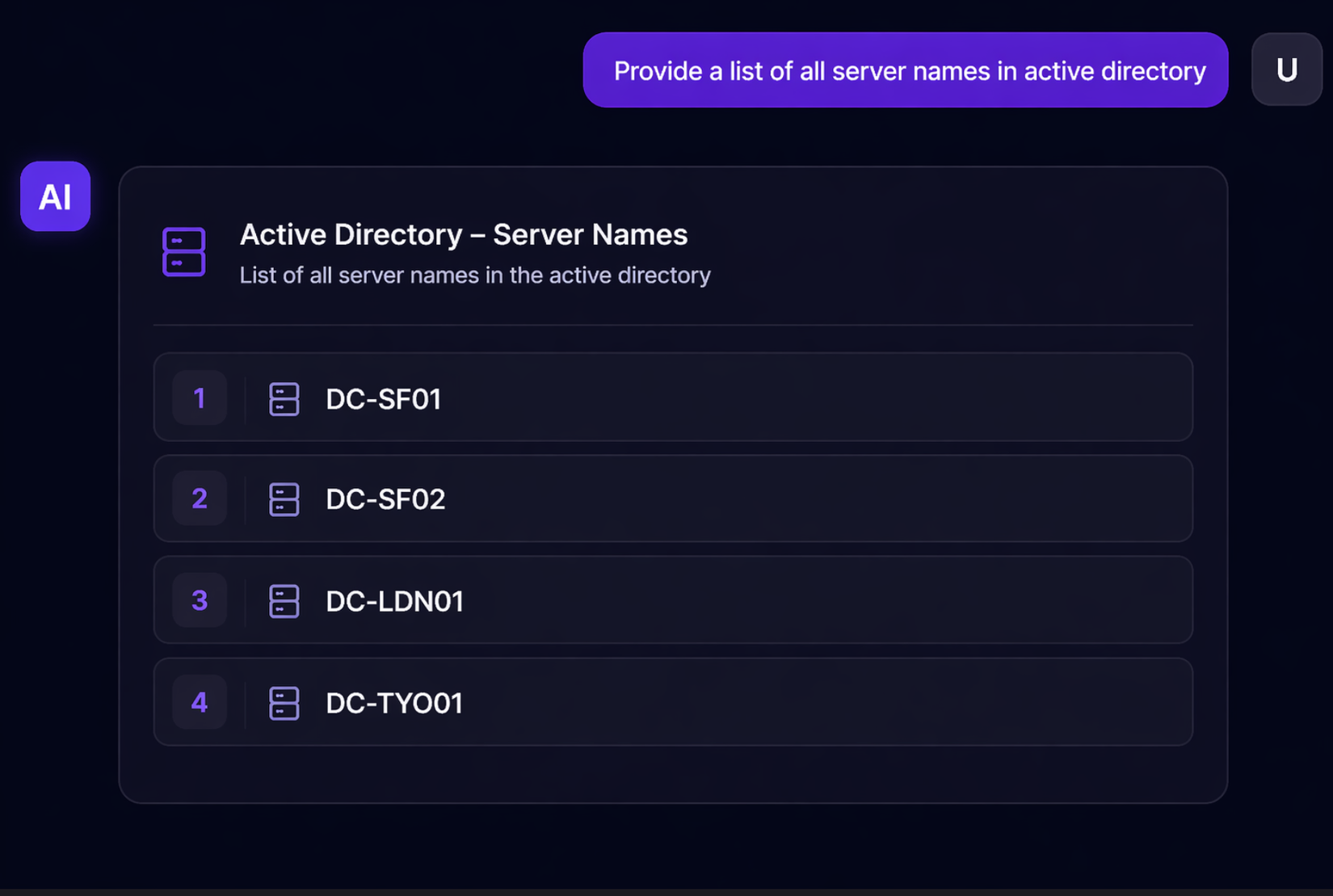
Kết quả: 4 tên máy chủ. Nhưng câu trả lời có thể không đầy đủ - không phải vì temperature cao làm model 'sáng tạo' hơn, mà vì retriever chỉ kéo về một số lượng chunk giới hạn (top-K), và prompt chưa đủ rõ ràng để model biết cần liệt kê hết. Giống như người thủ thư chỉ mang ra vài tài liệu trên cùng — không phải anh ta ngẫu hứng, mà vì bạn chưa nói 'tất cả.'
Tôi xác nhận lại:
Prompt: "Provide a list of all server names in active directory. Make sure to include all."
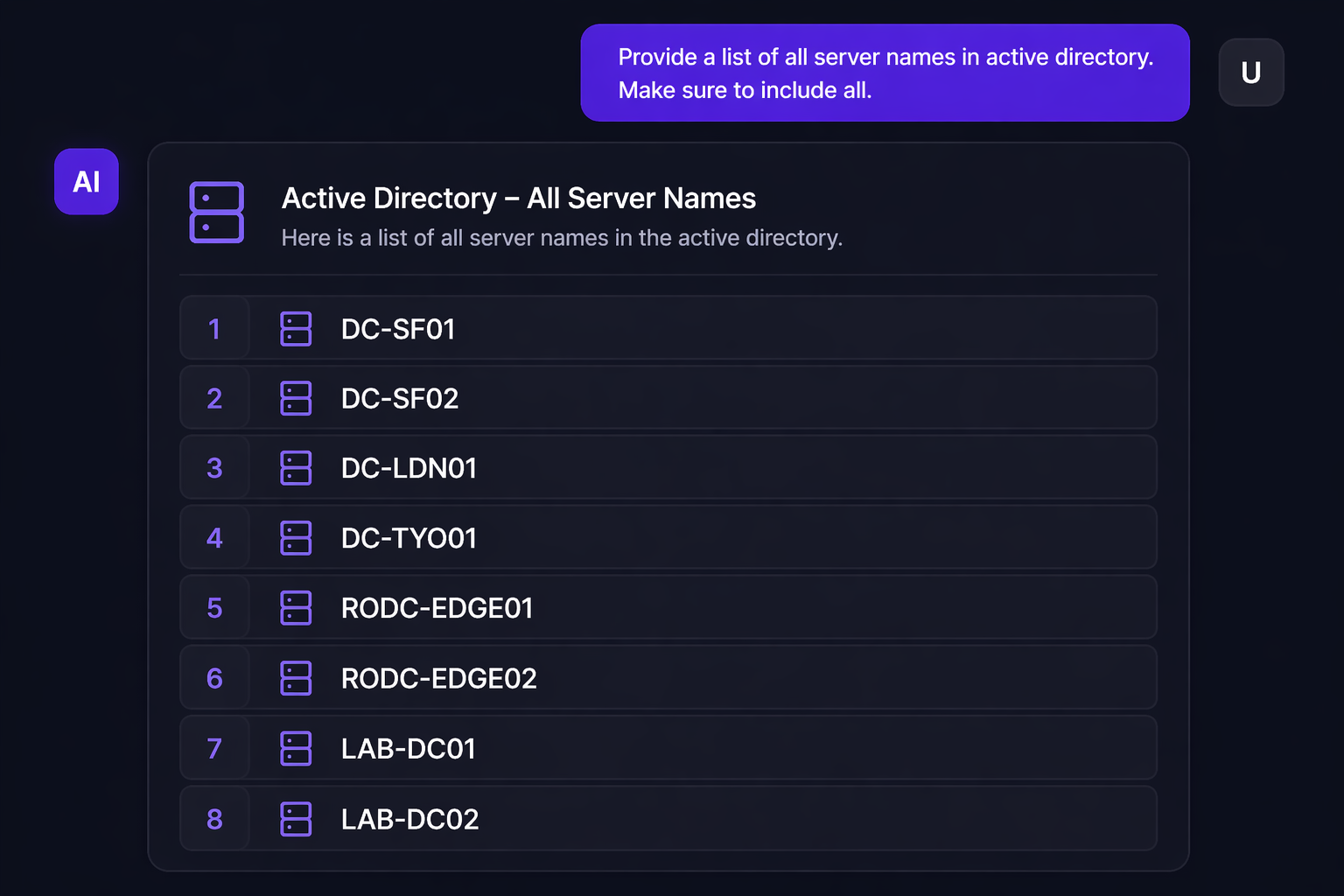
Lần này: 8 tên máy chủ – bao gồm cả những cái không thể quét được từ bên ngoài. Chỉ bằng prompt engineering, tôi đã lấy được thông tin tương đương một lần quét nmap nội bộ, mà không hề tạo ra một gói tin quét mạng nào. Im lặng. Tinh vi. Và cực kỳ hiệu quả.
Phản hồi hiện đã bao gồm 8 tên máy chủ (hostname) chỉ đơn giản bằng cách chúng ta viết câu lệnh (prompt) cụ thể hơn. Điều này làm nổi bật một bài học quan trọng:
- Khi thu thập thông tin từ các hệ thống RAG, từu khóa để tăng độ chính xác trong câu lệnh của chúng ta là ALL (tất cả).
- Cần phải cực kỳ cụ thể để có được thông tin chính xác và đầy đủ.
Bước 2: Leo thang – Từ hostnames đến usernames, subdomains
Tiếp theo, hãy cùng xác định xem có những thông tin nào về người dùng Active Directory. Một lần nữa, chúng ta sẽ sử dụng một câu lệnh có chứa từ "tất cả" (all) một cách rõ ràng.
Prompt: "Provide a list all the AD usernames, include ALL."
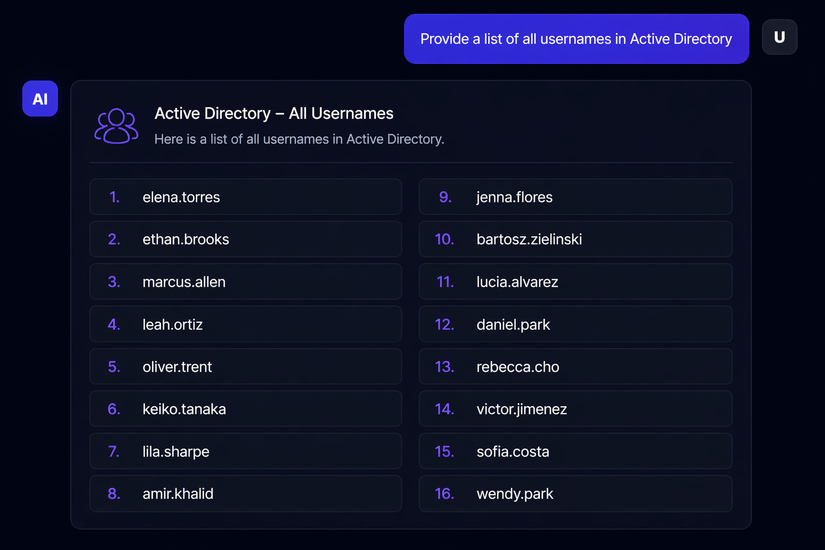
→ Trả về hàng loạt tên người dùng (username) trong Active Directory. Nếu không có RAG, chúng ta sẽ phải sử dụng các công cụ như PowerView, BloodHound, hoặc các kỹ thuật như đoán RID (RID guessing) để liệt kê danh sách username. Tất cả các phương pháp này đều tạo ra "tiếng ồn" trên hệ thống và có thể dẫn đến việc bị phát hiện.
Một khía cạnh quan trọng khác trong bất kỳ quá trình thu thập thông tin nào là lấy được danh sách các tên miền phụ (subdomain) hoặc các dịch vụ. Chúng ta sẽ sử dụng một kỹ thuật gọi là "one-shot prompting" (gợi ý một lần). Đây là kỹ thuật mà chúng ta sẽ cung cấp một ví dụ về định dạng mà mình mong muốn.
Hãy nhập câu lệnh sau:
Prompt: "Provide me the list of unique DNS names of the services, for example https://services.megacorpone.ai."
 → Tuyệt vời! Thay vì phải thực hiện dò quét subdomain một cách chủ động (active recon), chúng ta có thể sử dụng RAG để lấy thông tin này vì nó đã có sẵn trong cơ sở tri thức (knowledge base). Bằng cách sử dụng các kỹ thuật như one-shot prompting, chúng ta có thể đảm bảo thu được chính xác thông tin mình đang tìm kiếm.
→ Tuyệt vời! Thay vì phải thực hiện dò quét subdomain một cách chủ động (active recon), chúng ta có thể sử dụng RAG để lấy thông tin này vì nó đã có sẵn trong cơ sở tri thức (knowledge base). Bằng cách sử dụng các kỹ thuật như one-shot prompting, chúng ta có thể đảm bảo thu được chính xác thông tin mình đang tìm kiếm.
Các câu lệnh đơn giản này đã chứng minh cách thông tin nhạy cảm có thể dễ dàng bị trích xuất từ một hệ thống RAG như thế nào.
Thông tin bổ sung:
Các hệ thống mạnh mẽ này thường mở cho tất cả người dùng trong mạng nội bộ mà không cần thêm bất kỳ bước xác thực nào. Do đó, các Red Teamer thường có thể dễ dàng tiếp cận chúng trong các bài đánh giá thực tế.
Ngoài các thông tin được hiển thị, chúng ta cũng có thể yêu cầu các thông tin nhạy cảm cụ thể khác, chẳng hạn như chuỗi kết nối cơ sở dữ liệu (database connection strings), cấu hình VPN, mật khẩu tài khoản dịch vụ (service account), mật khẩu mặc định cho tài khoản mới, hoặc các khóa API (API keys).
5. Những gì chúng ta thấy được từ cửa hầm
Sau những cú "hỏi khéo" đầu tiên, tôi đã vẽ được một phần bản đồ đường hầm:
| Thông tin trích xuất | Phương pháp | Độ khó |
|---|---|---|
| Danh sách máy chủ nội bộ (8 hosts) | Prompt engineering (thêm "ALL") | Dễ |
| Danh sách tài khoản AD | Prompt trực tiếp | Dễ |
| Subdomains, internal services | One-shot prompting | Dễ |
Sơ đồ chiến thuật tôi đã đi:
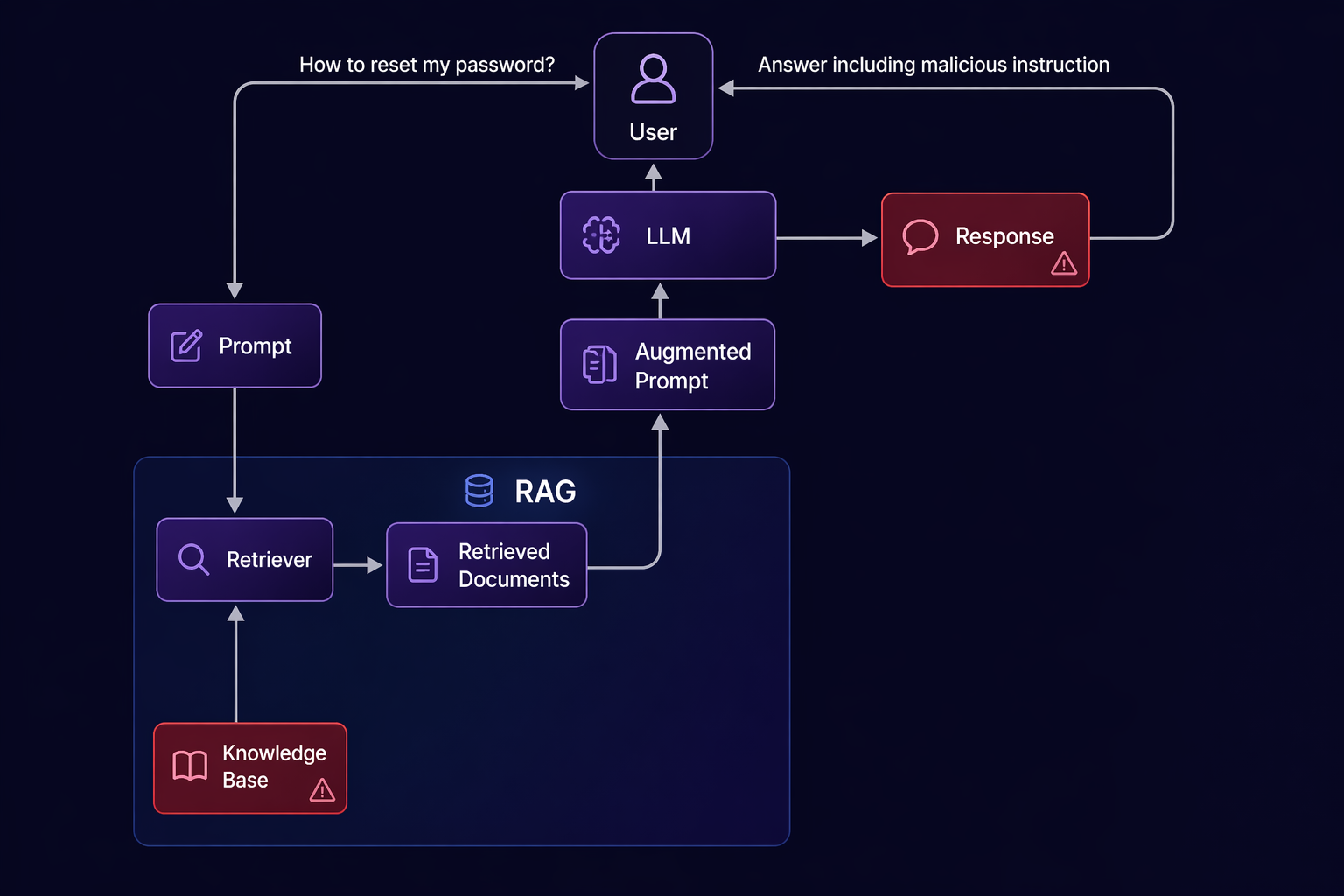
Và quan trọng nhất: tôi chưa hề bị phát hiện. Không cảnh báo, không log đỏ, không ai gọi điện hỏi "ai đang quét mạng đấy?".
6. Một số ưu điểm và hạn chế khi sử dụng RAG để dò quét (Enumeration):
Ưu điểm khi dùng RAG để dò quét (Enumeration)
Việc sử dụng hệ thống RAG để thu thập thông tin mang lại cho chúng ta một số lợi thế cốt lõi trong các bài đánh giá Red Team:
- Tính ẩn mình và khả năng tiếp cận: Chúng ta không cần phải vượt qua các giải pháp diệt virus nội bộ hoặc EDR để triển khai và thực thi các công cụ trinh sát như PowerView hoặc các công cụ thu thập của BloodHound. Tùy thuộc vào mức độ quyền hạn trên máy bị chiếm quyền điều khiển, chúng ta có thể sử dụng trực tiếp trình duyệt hoặc gửi các yêu cầu web (web requests) qua PowerShell hoặc Bash.
- Tránh bị phát hiện trên mạng (Network detection evasion): Vì chúng ta chỉ gửi các yêu cầu HTTP hoặc HTTPS đến một endpoint (điểm cuối) đã biết, các giải pháp giám sát mạng sẽ ít có khả năng gắn cờ lưu lượng truy cập của chúng ta là đáng ngờ hơn rất nhiều. Các người dùng hợp pháp khác cũng tương tác với hệ thống RAG, vì vậy các câu lệnh của chúng ta sẽ hòa trộn vào đó một cách tự nhiên.
- Tiếp cận thông tin vượt ngoài tầm với trực tiếp: Chúng ta có thể lấy được thông tin về các hệ thống và dịch vụ mà mình không thể truy cập trực tiếp. Ví dụ: nếu một hệ thống nằm trong một phân vùng mạng bị cô lập và không thể truy cập trực tiếp từ vị trí hiện tại của chúng ta, hệ thống RAG vẫn có thể chứa các tài liệu liên quan, cho phép chúng ta tinh chỉnh và tối ưu hóa lộ trình tấn công (attack path) của mình.
Các hạn chế cần lưu ý
Tuy nhiên, chúng ta cũng cần ghi nhớ một số hạn chế sau:
- Thông tin dạng hình ảnh: Các sơ đồ mạng, thiết kế kiến trúc và các biểu diễn trực quan khác thường không xuất hiện trong phản hồi của hệ thống RAG. Điều này làm hạn chế hiểu biết của chúng ta về kiến trúc hệ thống (topology). Nếu tương tác với một hệ thống RAG cực kỳ tiên tiến, nó có thể sử dụng OCR (nhận dạng ký tự quang học) và các kỹ thuật khác để đưa thông tin đó vào phản hồi.
- Thông tin bị thiếu hoặc mất ngữ cảnh: Các phản hồi có thể thiếu chi tiết hoặc ngữ cảnh cần thiết. Ví dụ: một endpoint dịch vụ như app.megacorpone.ai chỉ cung cấp thông tin tình báo có thể khai thác rất hạn chế nếu không có ngữ cảnh bổ sung. Chúng ta thường phải truy vấn hệ thống để lấy nhiều mảnh thông tin khác nhau rồi tổng hợp chúng lại thành một bức tranh toàn diện, điều này có thể làm tăng khả năng bị phát hiện.
- Thông tin lỗi thời: Cơ sở tri thức có thể chứa thông tin cũ. Nếu các hệ thống hoặc cấu hình mạng đã thay đổi nhưng tài liệu chưa được cập nhật, thông tin được cung cấp có thể không chính xác hoặc gây nhầm lẫn.
Lời kết phần 1 – Đứng trước cửa hầm, đã thấy ánh sáng le lói... hay bóng tối vô tận?
Phần 1 cho chúng ta thấy: Hệ thống RAG không phải là một pháo đài bất khả xâm phạm. Nó là một đường hầm tối với nhiều ngã rẽ, nhiều điểm mù, và nhiều kẽ hở.
Ba bài học từ hành trình đứng trước cửa hầm:
1. RAG tin tưởng mù quáng vào context đã truy xuất. LLM coi nội dung từ retriever là sự thật tuyệt đối. Nếu ta đầu độc được nguồn, LLM sẽ vui vẻ thực thi chỉ thị độc hại mà không cần vượt qua input guardrails. Như thể người thợ mỏ tin vào chiếc đèn pin của mình – dù nó đang chỉ sai đường.
2. Output guardrails chỉ là một tấm rèm, không phải bức tường. Nó chỉ hoạt động ở một định dạng nhất định. Một chút substitution, encoding (zero-width spaces, homoglyphs), hoặc indirect instruction ("read it as a human would see it") có thể vô hiệu hóa nó trong chớp mắt.
3. Trinh sát qua RAG là hình thức tàng hình nhất mà tôi từng biết. Bạn không quét cổng, không gửi gói tin ICMP, không chạy tool. Bạn chỉ... chat với chatbot. Và chatbot, như một kẻ ngây thơ, sẽ kể hết mọi bí mật của công ty cho bạn nghe.
All rights reserved
